

On the Properties of Neural Machine Translation= Encoder–Decoder Approaches
概要
对比了 RNN Encoder-Decoder 和 GRU(new proposed)之间的翻译能力,发现GRU更具优势且能够理解语法。
背景
RNN Encoder–Decoder
因为会把要翻译的语句映射到固定长度的vector所以训练需要的内存空间是固定的且很小,500M和几十G形成对比。
但也有问题:
As this approach is relatively new, there has not been much work on analyzing the properties and behavior of these models. For instance: What are the properties of sentences on which this approach performs better? How does the choice of source/target vocabulary affect the performance? In which cases does the neural machine translation fail?
不够Fancy的地方:
- 随着源句长度的增加,神经机器翻译模型的性能迅速下降。
- 词汇量的大小对翻译效果有很大的影响。
Encoder For Variable-Length Sequences
RNN
递归神经网络(RNN)在变长序列x = ( x1 , x2, … , xT)上通过保持隐藏状态h随时间变化而工作
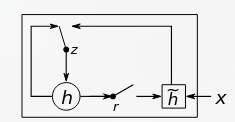
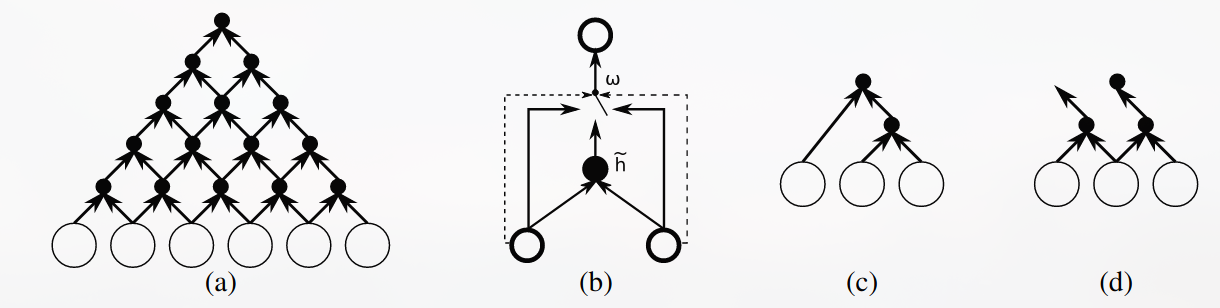
grConv
这是本文提出的用于替换RNN Encoder-Decoder 中的Encoder的一种新的神经网络,文中称为:gated recursive convolutional neural network (grConv)


On the Properties of Neural Machine Translation= Encoder–Decoder Approaches

