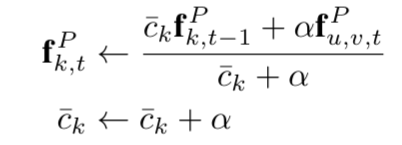

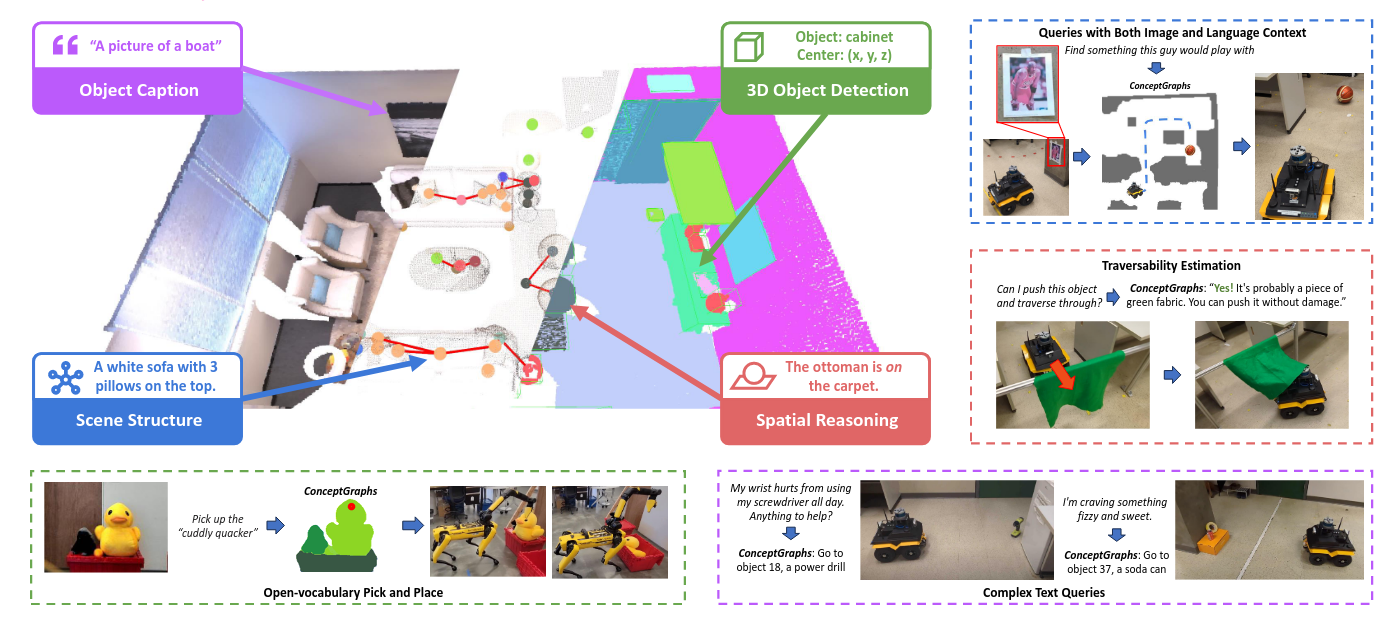
ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning
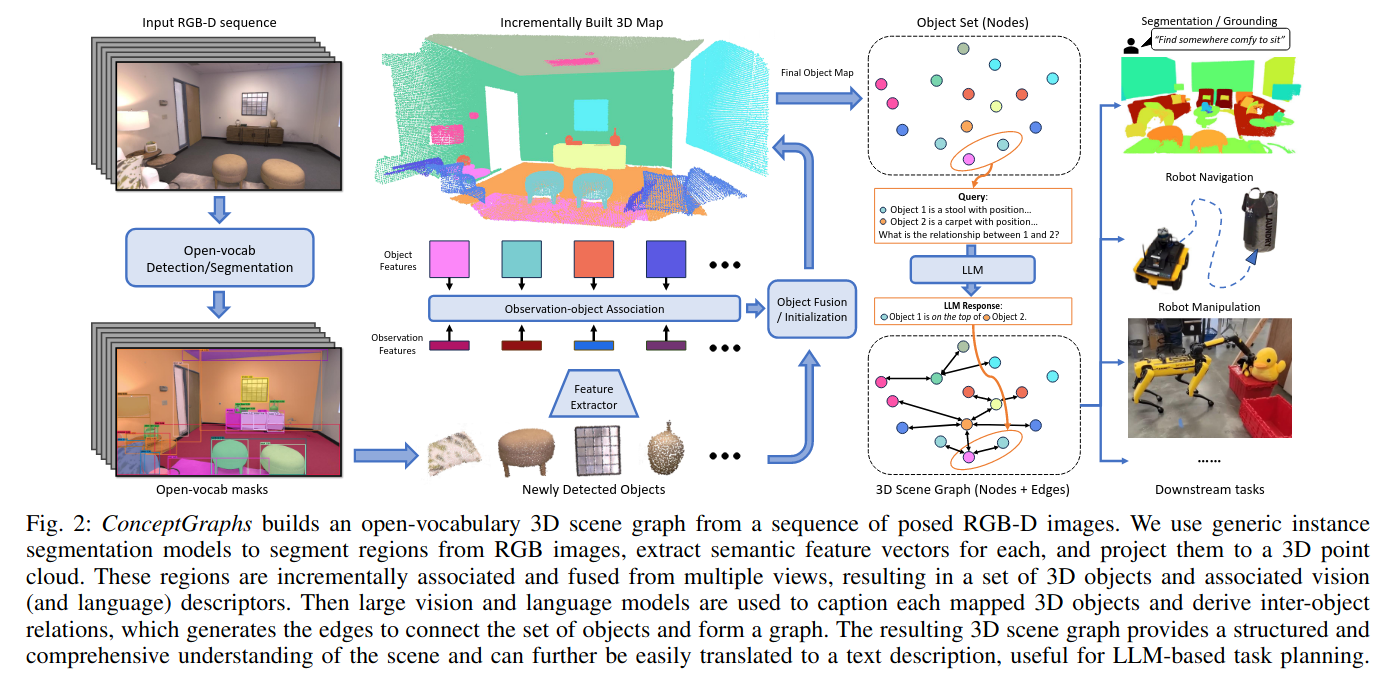
通过LLM来判断位置关系,以此构建scene graph
还是只能判断object-level空间关系,做不了part-level manipulation
SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
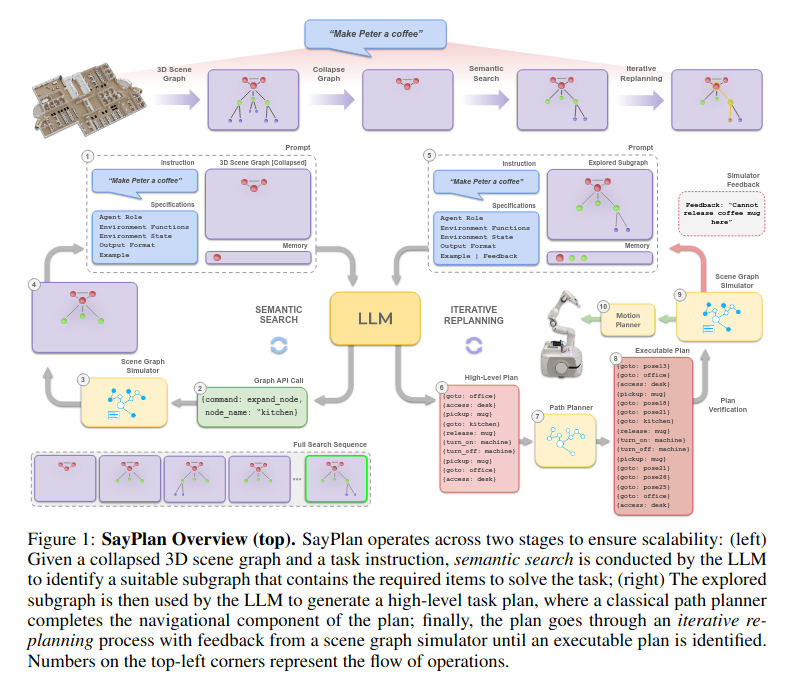
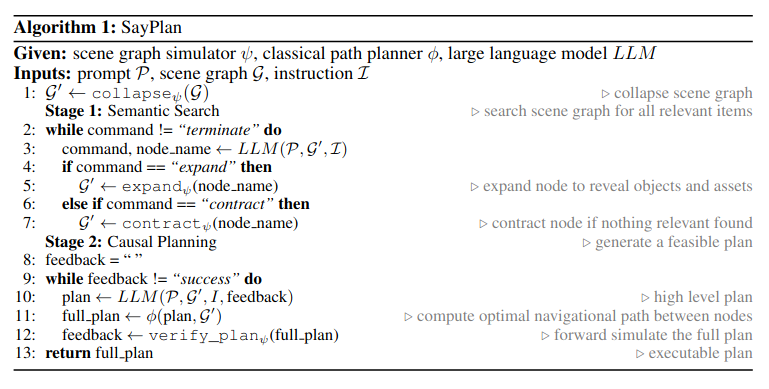
主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。
A scalable approach to ground LLM-based task planners across environments spanning multiple rooms and floors
Scene Graph 通过networkx (python package)表示
Three key innovations:
Collapsed 3DSG来在少数根节点上寻找task-relevant子图(后续通过展开子图进行进一步的搜寻),提高了scalability(避免过于复杂的整体场景图超过LLM的token限制)Scene Graph Simulator作为任务是否可行的验证器。
Clio= Real-time Task-Driven Open-Set 3D Scene Graphs
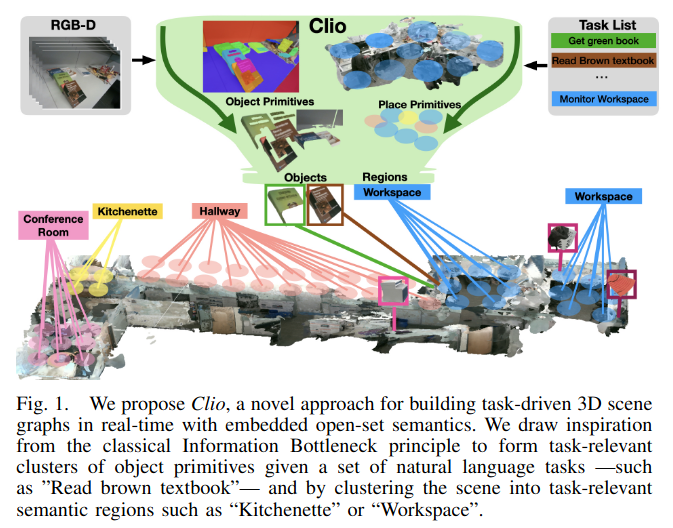
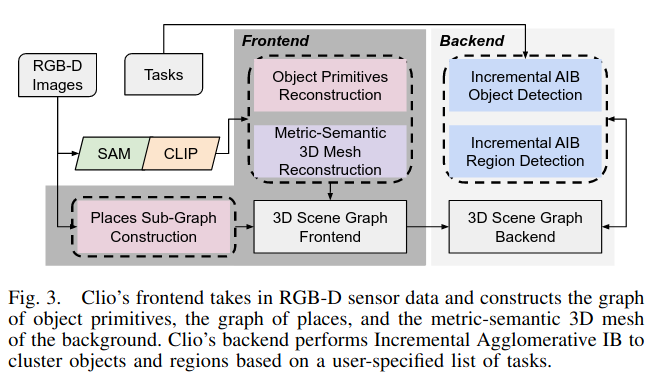
贡献:
提出了针对不同任务需要不同粒度的语义信息,本文是通过结合SAM和[[CLIP多模态预训练模型]]实现,但是忽略了物体之间的谓语关系或者父子关系。本质还是智能做导航,拾取,放下,导航的基本操作。
SceneGraphFusion- Incremental 3D Scene Graph Predictionfrom RGB-D Sequences
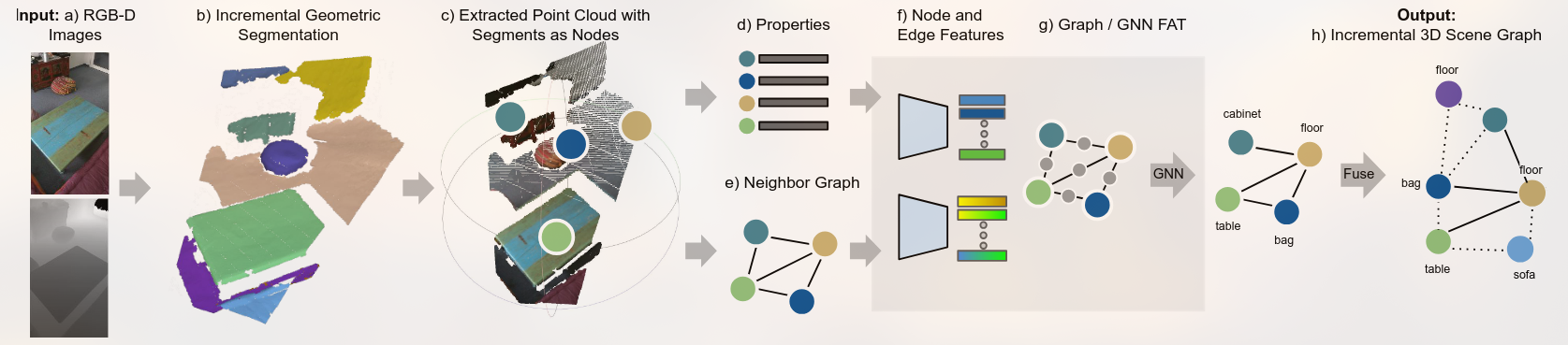
Overview of the proposed SceneGraphFusion framework. Our method takes a stream of RGB-D images a) as input to create an incremental geometric segmentation b). Then, the properties of each segment and a neighbor graph between segments are constructed. The properties d) and neighbor graph e) of the segments that have been updated in the current frame c) are used as the inputs to compute node and edge features f) and to predict a 3D scene graph g). Finally, the predictions are h) fused back into a globally consistent 3D graph.
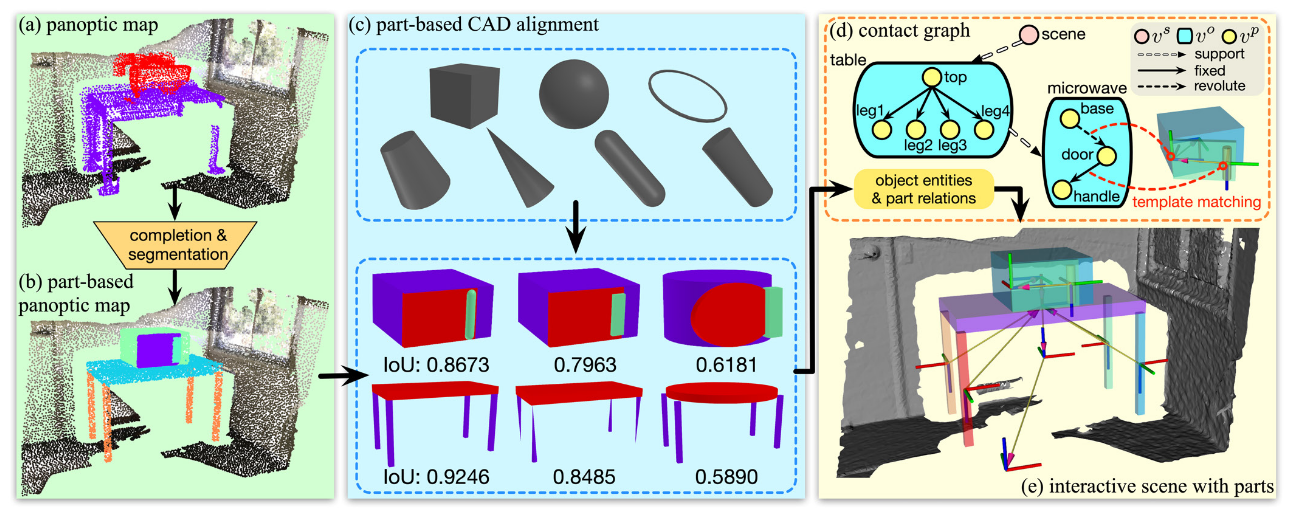
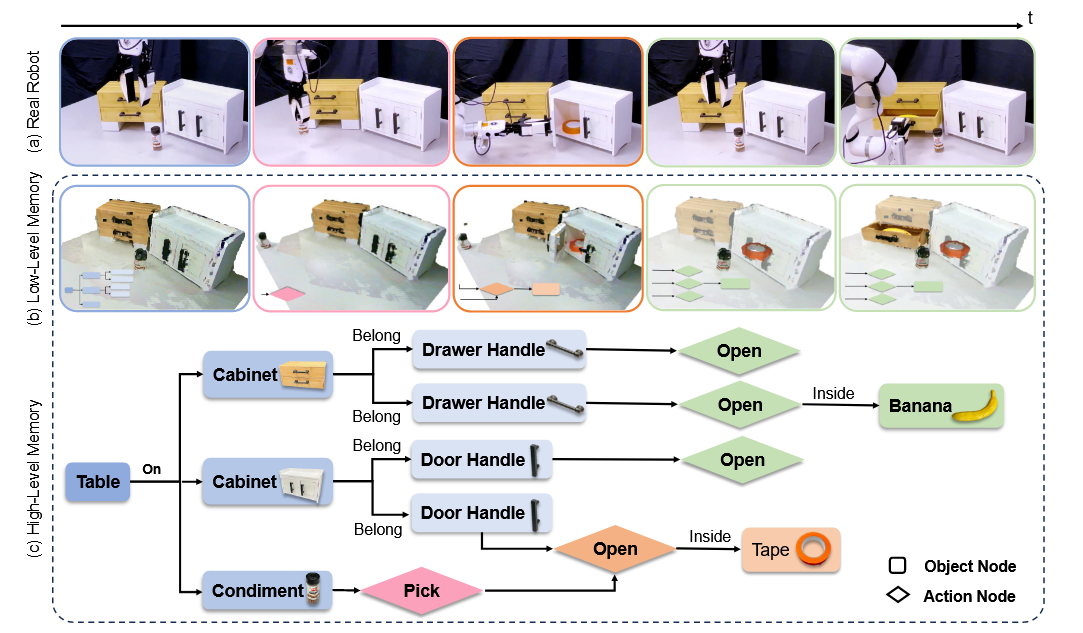
Scene Reconstruction with Functional Objects for Robot Autonomy
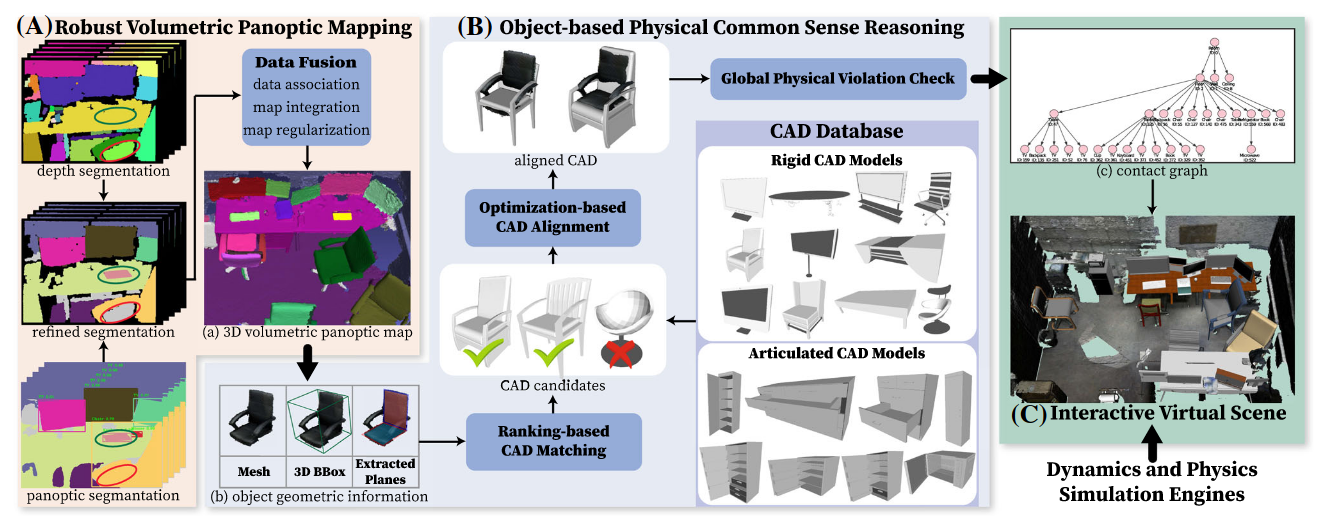
和李飞飞[[ACDC- Automated Creation of Digital Cousins for Robust Policy Learning]]的思想类似。

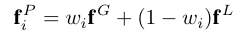
将不同帧$X_t$中的特征集合在M中特征点的公式: