Here's something encrypted, password is required to continue reading.
Read more

文本(Text)是离散符号,动作(Motion)是连续信号,两者性质截然不同。现有方法面临两个核心矛盾:
提出一个统一的动作-语言模型,同时支持:
且需要避免量化误差,减少跨模态干扰。
来自 Liang et al. (2024) 的思想:为每个模态配备独立的 Transformer 分支,各自拥有独立的 Embedding、FFN 和 LayerNorm,仅在 Self-Attention 层共享。这样:
使用预训练的 Motion VAE 将动作编码为连续 latent 向量(而非 VQ 离散索引),避免量化误差。
1 | Motion VAE Bimodal LLM Motion VAE |
两个并行分支,基于 GPT-2 配置(12 层,维度 768,MLP 维度 3072):
| 组件 | Text Branch $\mathcal{T}$ | Motion Branch $\mathcal{M}$ |
|---|---|---|
| 初始化 | 预训练 GPT-2(124M) | 从零训练(238M) |
| Embedding | 文本 Embedding | 独立 Motion Embedding |
| FFN | 独立 | 独立 |
| LayerNorm | 独立 | 独立 |
| Self-Attention | 共享 | 共享 |
路由机制:硬路由(非学习),由特殊标记决定——
<som> / <eom> 界定动作边界<motion_in> / <motion_out> 标记 I/O 位置由于动作是连续信号,不能复用文本的 Embedding lookup 和 softmax 解码,需要专用接口:
轻量级扩散模型(3 层 MLP + ResBlock,隐藏维度 1024),在 VAE latent 空间中做去噪:
$$\mathcal{L}{\text{diff}} = \mathbb{E}{z_0, t, \epsilon}\left[|\epsilon - \mathcal{H}(z_t, h_m)|_2^2\right]$$
<motion_out> 占位 token,Motion Branch 输出 $h_m^{v:v+K}$,$\mathcal{H}$ 从纯噪声 $z_T$ 逐步去噪(默认 100 步)得到 $\hat{z}_0$,再由 VAE Decoder 解码在 HumanML3D 上:
| 架构类型 | 路由方式 | 代表 | 特点 |
|---|---|---|---|
| 单流 + Projector | 无路由,全拼接 | LLaVA, Qwen-VL | 简单,但有跨模态干扰 |
| MoE | 学习的 Router, TopK 选专家 | Mixtral, Switch Transformer | 动态路由,扩展性好 |
| MoT / 双分支 | 按模态硬路由,共享 Attention | MotionGPT3 | 隔离前馈,受控交互 |
3D-Scene
Atlas
CLIP
CV
Chemistry
Contrastive-Learning
DINO
DT
Diffusion
DiffusionModel
Embodied-AI
FL
FPN
FoundationModel
Gated-NN
HRI
Hierarchical
HumanoidRobot
Image-Grounding
Image-Text
Image-generation
Image2Text
ImgGen
ImitationLearning
LLM
LatentAction
ML
MoE
MoT
MotionGeneration
MR/AR
Message-Passing
Multi-modal
Multi-view
MultiModal
NLP
NN
Object-Detection
Open-Vocabulary
Panoptic
Physical-Scene
PoseEstimation
QML
Quantum
RL
RNN
Real2Sim
Reconstruct
Representation-Learning
RobotLearning
Robotics
Scalability
Scene-graph
Scene-synthesis
Segmentation
Semantic
Sim2Real
Subgraph
Survey
Task-Planning
Transformer
Translation-Embedding
VAE
VLA
VLM
VLP
VQ-VAE
ViT
Visual-Relation
WorldModel
Unified-Multimodal
BAGEL-Unified-Multimodal-Pretraining
作者:Chaorui Deng, Deyao Zhu, Kunchang Li 等 (ByteDance Seed)
统一多模态理解与生成(Unified Multimodal Understanding and Generation)是当前AI领域的热点方向。GPT-4o、Gemini 2.0等闭源系统展现了强大能力,但开源模型与之仍存在显著差距。现有开源统一模型主要在图文配对数据上训练,缺乏对复杂多模态交错数据(Interleaved Data)的利用。
在采用 External Diffuser 架构的模型中,LLM/VLM 与扩散模型通过轻量级适配器连接:
与传统MoE不同,MoT复制整个Transformer层而非仅FFN:
BAGEL采用无瓶颈的集成Transformer方案:
双视觉编码器:
| 模态 | 方法 | 损失函数 |
|---|---|---|
| 文本 | Next-Token-Prediction | Cross-Entropy |
| 视觉 | Rectified Flow | MSE |
损失权重比:$\text{CE} : \text{MSE} = 0.25 : 1$
对于交错多图像生成:
采用Diffusion Forcing策略,对不同图像添加独立噪声级别。
| 数据类型 | 数据量 | Token数 |
|---|---|---|
| 纯文本 | 400M | 0.4T |
| 图文配对(理解) | 500M | 0.5T |
| 图文配对(生成) | 1600M | 2.6T |
| 交错理解数据 | 100M | 0.5T |
| 交错生成数据(视频) | 45M | 0.7T |
| 交错生成数据(网页) | 20M | 0.4T |
视频数据:
网页数据:
受DeepSeek-R1启发,构建50万条推理增强样本:
论文定义:某能力在早期训练阶段不存在,但在后期训练中出现
不同能力的涌现时间点(达到85%峰值性能所需token数):
| 能力 | 涌现时间点 |
|---|---|
| 多模态理解 | ~0.18T tokens |
| 图像生成 | ~0.68T tokens |
| 图像编辑 | ~2.64T tokens |
| 智能编辑(复杂推理) | ~3.61T tokens |
关键发现:
在1.5B模型上对比Dense、MoE、MoT三种架构:
| 基准 | BAGEL | Janus-Pro | Qwen2.5-VL |
|---|---|---|---|
| MMMU | 58.6 | 41.8 | 49.3 |
| MM-Vet | 73.1 | 55.9 | 62.8 |
| MathVista | 69.3 | 54.7 | 68.2 |
| MMVP | 67.2 | 48.3 | - |
| 模型 | Overall |
|---|---|
| BAGEL (w/ rewriter) | 0.88 |
| BAGEL | 0.82 |
| Janus-Pro | 0.80 |
| FLUX.1-dev | 0.82 |
| SD3-Medium | 0.74 |
| 模型 | Score |
|---|---|
| GPT-4o | 78.9 |
| BAGEL w/ Self-CoT | 55.3 |
| BAGEL | 44.9 |
| Gemini 2.0 | 57.6 |
| Step1X-Edit | 14.9 |
统一多模态模型:
视觉生成:
论文链接 | GitHub | Checkpoints
视觉-语言-动作(Vision-Language-Action, VLA)基础模型是机器人操作领域的新兴方法,通过大规模预训练使机器人能够执行由自然语言指令引导的多样化操作任务。然而,目前存在以下问题:
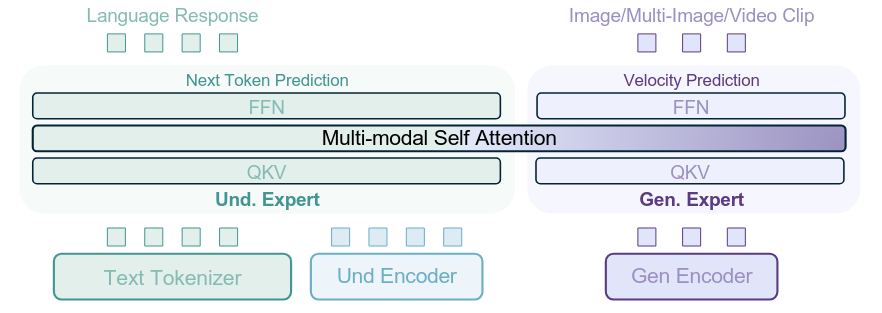
将预训练的视觉语言模型(VLM)与动作生成模块(Action Expert)结合,通过共享自注意力机制实现跨模态统一建模。视觉-语言和动作模态通过独立的 Transformer 路径处理,既保留 VLM 的语义先验,又避免跨模态干扰。
一种用于连续动作建模的生成方法,通过学习从噪声到目标动作的向量场来生成平滑的机器人控制信号。
将序列划分为图像-指令块、状态块和动作块,应用因果掩码防止信息泄露,确保动作预测只能访问当前和历史观测信息。
LingBot-VLA 采用 MoT 架构,整合 Qwen2.5-VL 作为视觉语言骨干网络,配合独立的 Action Expert 模块:
联合建模序列:
$$[O_t, A_t] = [I_t^1, I_t^2, I_t^3, T_t, s_t, a_t, a_{t+1}, \ldots, a_{t+T-1}]$$
其中 $I_t^{1,2,3}$ 为三视角图像,$T_t$ 为任务指令,$s_t$ 为机器人状态,$A_t$ 为动作序列(chunk length = 50)。
类似[[BAGEL-Unified-Multimodal-Pretraining]]
定义概率路径通过线性插值:
$$A_{t,s} = sA_t + (1-s)\epsilon, \quad \epsilon \sim \mathcal{N}(0, I)$$
训练目标:
$$\mathcal{L}{FM} = \mathbb{E}{s \sim U[0,1], A_t, \epsilon}|v_\theta(A_{t,s}, O_t, s) - (A_t - \epsilon)|^2$$
通过可学习查询 $Q_t$ 与 LingBot-Depth 模型的深度 token $D_t$ 对齐,增强空间感知:
$$\mathcal{L}{distill} = \mathbb{E}{Q_t}|Proj(Q_t) - D_t|$$
| 方法 | 平均成功率(SR) | 平均进度分(PS) |
|---|---|---|
| WALL-OSS | 4.05% | 10.35% |
| GR00T N1.6 | 7.59% | 15.99% |
| π0.5 | 13.02% | 27.65% |
| LingBot-VLA w/o depth | 15.74% | 33.69% |
| LingBot-VLA w/ depth | 17.30% | 35.41% |
| 方法 | Clean 场景 SR | Randomized 场景 SR |
|---|---|---|
| π0.5 | 82.74% | 76.76% |
| LingBot-VLA w/o depth | 86.50% | 85.34% |
| LingBot-VLA w/ depth | 88.56% | 86.68% |

作者:Siyuan Mu (四川农业大学), Sen Lin (休斯顿大学)
随着AI基础大模型的快速发展,现代数据集变得越来越多样化和复杂,包含多模态数据(文本、图像、音频)和复杂结构(图、层次关系)。这给大模型发展带来两大挑战:
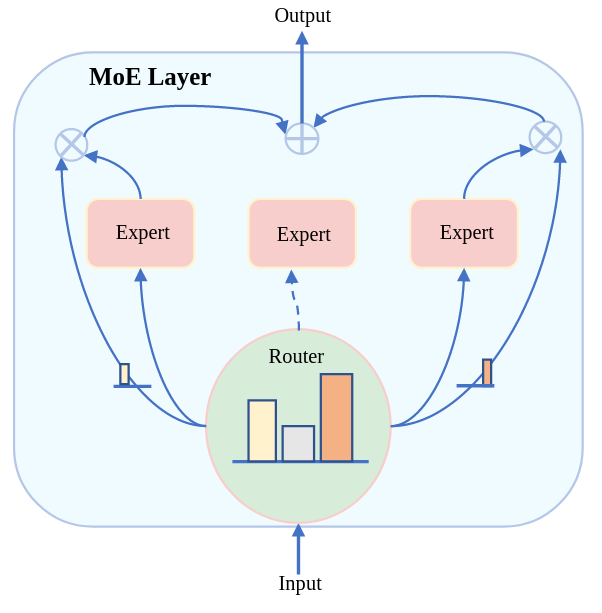
混合专家模型(Mixture of Experts, MoE)通过动态选择和激活最相关的子模型来处理输入数据,成为解决这些挑战的有效方案。
MoE采用”分而治之”(divide and conquer)策略,与传统密集模型不同:
$$
\text{MoE}(x) = \sum_{i \in \mathcal{I}_D} w_i M_i(x)
$$
其中 $\mathcal{I}_D$ 是被选中专家的索引集,$w_i$ 是第 $i$ 个专家的权重,$M_i(x)$ 是专家网络输出。
$$
G(x)i = \text{softmax}(\text{TopK}(g(x) + R{noise}, k))i
$$
其中 $g(x)$ 是线性函数计算的门控值,$R{noise}$ 是鼓励专家探索的噪声。
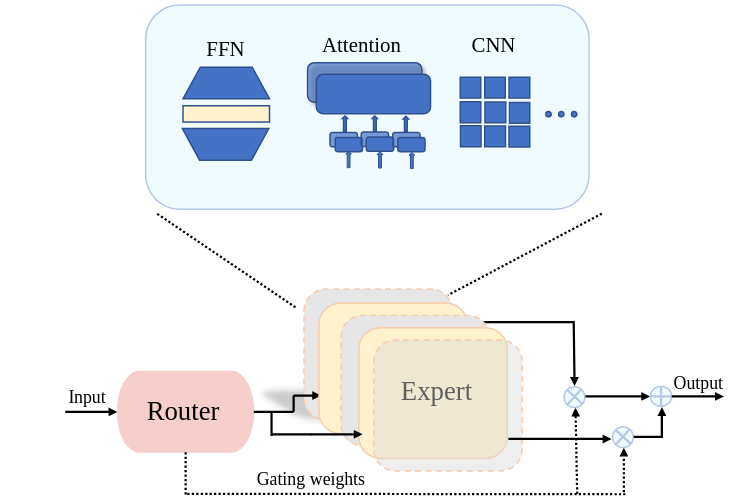
| 类型 | 描述 | 应用场景 |
|---|---|---|
| FFN专家 | 替换Transformer中的FFN层 | 最常用,如Switch Transformer |
| MoA(混合注意力) | 将MoE应用于注意力模块 | 图像生成、多模态任务 |
| CNN专家 | 将MoE应用于CNN层 | 计算机视觉任务 |
$$
\mathcal{L}{aux} = \alpha \cdot N \cdot \sum{i=1}^{N} f_i \cdot Q_i
$$
其中 $f_i$ 是分配给专家 $i$ 的token比例,$Q_i$ 是路由概率比例。
MoA将MoE机制引入多头注意力模块,每个注意力头视为一个”专家”。
1 | class MixtureOfAttention(nn.Module): |
| 特性 | 标准多头注意力 | MoA |
|---|---|---|
| 头激活 | 所有头同时激活 | 动态选择部分头 |
| 计算开销 | 与头数量成正比 | 仅计算被选中的头 |
| 可扩展性 | 增加头数直接增加计算量 | 可扩展更多头而不显著增加计算 |
| 领域 | 代表性工作 | 核心贡献 |
|---|---|---|
| 持续学习 | CN-DPM, Lifelong-MoE, PMoE | 缓解灾难性遗忘 |
| 元学习 | MoE-NPs, MixER, Meta-DMoE | 增强快速适应能力 |
| 多任务学习 | MMoE, MOOR, TaskExpert | 解耦任务、减少干扰 |
| 强化学习 | MMRL, MACE, MENTOR | 处理非平稳环境 |
| 领域 | 任务 | 代表性工作 |
|---|---|---|
| 计算机视觉 | 图像分类 | V-MoE, Soft MoE, CLIP-MoE |
| 目标检测 | MoCaE, DAMEX | |
| 语义分割 | DeepMoE, Swin2-MoSE | |
| 图像生成 | RAPHAEL, MEGAN | |
| 自然语言处理 | NLU | GLaM, MoE-LPR |
| 机器翻译 | GShard, NLLB | |
| 多模态融合 | LIMoE, LLaVA-MoLE |
| 模型 | 参数规模 | 主要成就 |
|---|---|---|
| Switch Transformer | 万亿级 | 预训练速度比T5-Base快7倍 |
| GLaM | 万亿级 | 增强上下文信息利用能力 |
| Mixtral 8×7B | 470亿(激活130亿) | 高参数效率 |
| DeepSeek系列 | - | 多项基准SOTA |
作者:Fan Bao, Shen Nie, Kaiwen Xue, Chongxuan Li, Shi Pu, Yaole Wang, Gang Yue, Yue Cao, Hang Su, Jun Zhu
发表于:ICML 2023

扩散模型(Diffusion Models)在图像生成领域取得了巨大成功,但现有方法主要基于 U-Net 架构。随着 Transformer 在各领域的成功应用,如何将 Transformer 有效地应用于多模态扩散模型成为一个重要研究方向。现有的多模态生成方法通常需要为不同任务(文生图、图生文、联合生成等)设计不同的模型架构。
扩散模型通过前向过程逐步向数据添加噪声,再通过反向过程学习去噪,从而实现生成。
UniDiffuser 的核心思想是对不同模态独立添加噪声,使用不同的时间步 $t$ 和 $s$,通过控制时间步实现任务切换。
将 U-Net 的长跳跃连接(Long Skip Connection)引入 Vision Transformer,在浅层和深层之间建立连接。

$$q(x_t | x_0) = \mathcal{N}(x_t; \alpha_t x_0, \sigma_t^2 I)$$
参数说明:
等价的重参数化表示:
$$x_t = \alpha_t x_0 + \sigma_t \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)$$
这个形式便于采样和训练,$\epsilon$ 是标准高斯噪声。
扩散模型学习反向过程 $p_\theta(x_{t-1}|x_t)$,通过神经网络预测噪声 $\epsilon_\theta(x_t, t)$,然后恢复 $x_0$:
$$\hat{x}_0 = \frac{x_t - \sigma_t \epsilon_\theta(x_t, t)}{\alpha_t}$$
解释:由 $x_t = \alpha_t x_0 + \sigma_t \epsilon$ 反解得到。预测出噪声后,即可估计原始数据。
对于图文对 $(x_0, y_0)$,独立地对每个模态加噪:
$$q(x_t, y_s | x_0, y_0) = q(x_t | x_0) \cdot q(y_s | y_0)$$
展开形式:
$$x_t = \alpha_t x_0 + \sigma_t \epsilon_x, \quad y_s = \alpha_s y_0 + \sigma_s \epsilon_y$$
关键点:两个模态使用独立的时间步 $t$ 和 $s$,这是实现多任务统一的核心设计。
数据的联合分布 $q(x_0, y_0)$ 加噪后变为:
$$q(x_t, y_s) = \int q(x_t, y_s | x_0, y_0) q(x_0, y_0) , dx_0 dy_0$$
解释:这是对所有可能的原始数据对进行积分,得到加噪后数据的边缘分布。
通过控制 $t$ 和 $s$ 的取值,可以从联合分布中恢复各种边缘分布和条件分布:
| 时间步设置 | 对应分布 | 实现的任务 |
|---|---|---|
| $t, s > 0$ | $q(x_t, y_s)$ | 联合生成 |
| $t > 0, s = 0$ | $q(x_t, y_0) = q(x_t | y_0) q(y_0)$ | 文生图 |
| $t = 0, s > 0$ | $q(x_0, y_s) = q(y_s | x_0) q(x_0)$ | 图生文 |
| $t > 0, s = T$ | $q(x_t, y_T) \approx q(x_t) q(y_T)$ | 无条件图像生成 |
当 $s=0$ 时,$y_s = y_0$(文本无噪声),此时:
$$q(x_t, y_0) = q(x_t | y_0) \cdot q(y_0)$$
解释:对 $y$ 不加噪声($s=0$)在数学上等价于以 $y$ 为条件进行生成。这是一个优雅的设计——不需要修改模型架构,只需控制时间步即可切换任务。
模型 $\epsilon_\theta$ 同时预测两个模态的噪声:
$$[\hat{\epsilon}_x, \hat{\epsilon}y] = \epsilon_\theta(x_t, y_s, t, s)$$
完整训练损失:
$$\mathcal{L}(\theta) = \mathbb{E}{t, s, (x_0, y_0), \epsilon_x, \epsilon_y} \left[ \lambda_t |\epsilon_x - \hat{\epsilon}_x|^2 + \lambda_s |\epsilon_y - \hat{\epsilon}_y|^2 \right]$$
各项说明:
简化形式(实际训练中常用):
$$\mathcal{L} = \mathbb{E}\left[|\epsilon_x - \hat{\epsilon}_x|^2 + |\epsilon_y - \hat{\epsilon}_y|^2\right]$$
从 $t=T$(纯噪声)开始,逐步去噪到 $t=0$:
$$x_{t-1} = \frac{1}{\sqrt{\alpha_{t|t-1}}} \left( x_t - \frac{1-\alpha_{t|t-1}}{\sigma_t} \hat{\epsilon}x \right) + \tilde{\sigma}t z$$
$$y{s-1} = \frac{1}{\sqrt{\alpha{s|s-1}}} \left( y_s - \frac{1-\alpha_{s|s-1}}{\sigma_s} \hat{\epsilon}_y \right) + \tilde{\sigma}_s z’$$
参数说明:
固定 $s=0$(即 $y_s = y_0$ 为输入文本),只对图像进行去噪:
$$x_{t-1} = \frac{1}{\sqrt{\alpha_{t|t-1}}} \left( x_t - \frac{1-\alpha_{t|t-1}}{\sigma_t} \hat{\epsilon}_x(x_t, y_0, t, 0) \right) + \tilde{\sigma}_t z$$
解释:文本时间步固定为 0,模型接收干净文本作为条件,只更新图像。
U-ViT 在第 $l$ 层和第 $(L-l)$ 层之间添加跳跃连接:
$$h^{(L-l)} = \text{Block}^{(L-l)}\left( \text{Concat}(h^{(L-l-1)}, h^{(l)}) \right)$$
参数说明:
设计动机:借鉴 U-Net 的成功经验,跳跃连接帮助保留低层的细节信息,有助于生成高质量图像。
为增强条件生成效果,使用 CFG 技术:
$$\tilde{\epsilon}_x = \epsilon_\theta(x_t, \varnothing, t, 0) + w \cdot \left( \epsilon_\theta(x_t, y_0, t, 0) - \epsilon_\theta(x_t, \varnothing, t, 0) \right)$$
参数说明:
等价形式:
$$\tilde{\epsilon}_x = (1-w) \cdot \epsilon_\theta(x_t, \varnothing, t, 0) + w \cdot \epsilon_\theta(x_t, y_0, t, 0)$$
训练技巧:训练时以一定概率(如 10%)将文本随机替换为空文本,使模型同时学习条件和无条件生成。
| 阶段 | 图像输入 | 文本输入 | 时间步 |
|---|---|---|---|
| 训练 | 加噪图像 $x_t$ | 加噪文本 $y_s$ | $t, s$ 随机采样 |
| 联合生成 | 纯噪声 | 纯噪声 | $t=s=T \to 0$ |
| 文生图 | 纯噪声 | 原始文本 | $t: T \to 0$, $s=0$ |
| 图生文 | 原始图像 | 纯噪声 | $t=0$, $s: T \to 0$ |
MS-COCO 256×256 文生图(零样本):
| 方法 | FID↓ | CLIP Score↑ |
|---|---|---|
| DALL-E | 27.50 | - |
| GLIDE | 12.24 | - |
| Stable Diffusion | 12.63 | 0.331 |
| UniDiffuser | 9.71 | 0.322 |
ImageNet 256×256 类条件生成:
| 方法 | FID↓ |
|---|---|
| ADM | 10.94 |
| LDM-4 | 10.56 |
| DiT-XL/2 | 9.62 |
| U-ViT-H/2 | 2.29 |
| 公式 | 含义 |
|---|---|
| $x_t = \alpha_t x_0 + \sigma_t \epsilon$ | 前向加噪过程 |
| $q(x_t, y_s | x_0, y_0) = q(x_t|x_0) q(y_s|y_0)$ | 独立加噪(多任务统一的关键) |
| $\mathcal{L} = |\epsilon_x - \hat{\epsilon}_x|^2 + |\epsilon_y - \hat{\epsilon}_y|^2$ | 训练目标 |
| $s=0 \Rightarrow$ 以文本为条件 | 任务切换机制 |
| $\tilde{\epsilon} = \epsilon_\varnothing + w(\epsilon_y - \epsilon_\varnothing)$ | 分类器自由引导 |
Scalable Diffusion Models with Transformers

Scalable Diffusion Models with Transformers | ICCV 2023
扩散模型(Diffusion Models)在图像生成领域取得了显著成功,但其架构设计一直沿用卷积U-Net作为主干网络。与此同时,Transformer架构已经在自然语言处理、视觉识别等多个领域取得了统治地位,并展现出优秀的可扩展性。本文探索将Transformer架构引入扩散模型,研究其在图像生成任务中的可扩展性和性能表现。
在潜在空间而非像素空间训练扩散模型,提高计算效率:
对于256×256×3的图像,VAE将其压缩为32×32×4的潜在表示(下采样因子为8)。
注意:这里使用的是标准VAE,输出是连续的潜在表示,而非VQ-VAE的离散codebook索引。
将潜在表示分解为patch序列:
例如,$p=2$ 时,序列长度 $T = (32/2)^2 = 256$。
条件生成的采样技巧,提高生成质量:
$$
\hat{\epsilon}_\theta(x_t, c) = \epsilon_\theta(x_t, \emptyset) + s \cdot (\epsilon_\theta(x_t, c) - \epsilon_\theta(x_t, \emptyset))
$$
其中:
DiT基于Vision Transformer (ViT)架构,包含以下组件:
探索了四种将时间步 $t$ 和类别标签 $c$ 注入Transformer的方式:
将 $t$ 和 $c$ 的embedding作为额外token添加到序列中:
1 | tokens = [t_embed, c_embed, patch_1, patch_2, ..., patch_T] |
通过交叉注意力机制注入条件:
1 | # 标准self-attention后添加cross-attention |
通过自适应归一化层注入条件:
1 | γ, β = MLP(t_embed + c_embed) |
在adaLN基础上增加门控参数并零初始化:
1 | γ, β, α = MLP(t_embed + c_embed) |
为什么需要两组参数?
Transformer block有两个子层(Attention + FFN),每个子层需要独立的条件控制:
总共6个参数:shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp
零初始化的优势:
设计四种规模的模型配置:
| 模型 | 层数N | 隐藏维度d | 注意力头数 | Gflops (p=4) |
|---|---|---|---|---|
| DiT-S | 12 | 384 | 6 | 1.4 |
| DiT-B | 12 | 768 | 12 | 5.6 |
| DiT-L | 24 | 1024 | 16 | 19.7 |
| DiT-XL | 28 | 1152 | 16 | 29.1 |
Transformer中的标准组件,对序列中每个位置独立应用前馈网络:
1 | class PointwiseFeedForward(nn.Module): |
与Self-Attention的分工:
这是所有Transformer变体(LLM、ViT、DiT)的统一设计。
模型前向传播的计算量(Gflops)与FID呈强负相关(相关系数-0.93):
关键洞察:参数量不是���一决定因素,计算量才是提升性能的关键。
在400K训练步数时的FID对比:
| 方法 | FID-50K | 计算开销 |
|---|---|---|
| In-Context | ~80 | 119.4 Gflops |
| Cross-Attention | ~60 | 137.6 Gflops |
| adaLN | ~45 | 118.6 Gflops |
| adaLN-Zero | ~23 | 118.6 Gflops |
DiT展现出与ViT类似的可扩展性:
DiT-XL/2 (118.6 Gflops) 比传统方法更高效:
增加采样步数(增加测试时计算量)无法弥补模型规模不足:
结论:模型计算量比采样计算量更重要。
ImageNet 256×256基准测试:
| 方法 | FID↓ | IS↑ | Precision | Recall |
|---|---|---|---|---|
| LDM-4-G (cfg=1.50) | 3.60 | 247.67 | 0.87 | 0.48 |
| StyleGAN-XL | 2.30 | 265.12 | 0.78 | 0.53 |
| DiT-XL/2-G (cfg=1.50) | 2.27 | 278.24 | 0.83 | 0.57 |
ImageNet 512×512基准测试:
| 方法 | FID↓ | IS↑ |
|---|---|---|
| ADM-G, ADM-U | 3.85 | 221.72 |
| DiT-XL/2-G (cfg=1.50) | 3.04 | 240.82 |
DiT-XL/2在两个分辨率上都达到了SOTA性能。
| 特性 | U-Net | DiT |
|---|---|---|
| 归纳偏置 | 强(卷积、多尺度) | 弱(纯注意力) |
| 可扩展性 | 有限 | 优秀 |
| 架构统一性 | 领域特定 | 跨领域通用 |
| 训练稳定性 | 需要技巧 | 天然稳定 |
| 特性 | VAE (DiT使用) | VQ-VAE |
|---|---|---|
| 潜在空间 | 连续(浮点数) | 离散(codebook索引) |
| 输出维度 | 32×32×4(4通道特征) | 32×32(单个索引) |
| 适用场景 | 扩散模型 | 自回归模型 |
| 量化 | 无 | 有(查表) |
1 | def dit_block(x, c): |
对于DiT-XL/2($N=256$ tokens,$d=1152$):
FFN占据了大部分计算量!
GR00T N1 An Open Foundation Model for Generalist Humanoid Robots
论文链接 | NVIDIA, 2025
人形机器人作为通用机器人的理想硬件平台,需要强大的基础模型来实现智能自主操作。受大语言模型和视觉模型成功的启发,研究者希望通过在大规模异构数据上训练机器人基础模型,使其能够理解新场景、处理真实世界的变化并快速学习新任务。然而,与文本和图像领域不同,机器人领域缺乏互联网规模的训练数据,不同机器人的传感器、自由度、控制模式差异巨大,形成”数据孤岛”问题。
本论文要解决的核心问题:
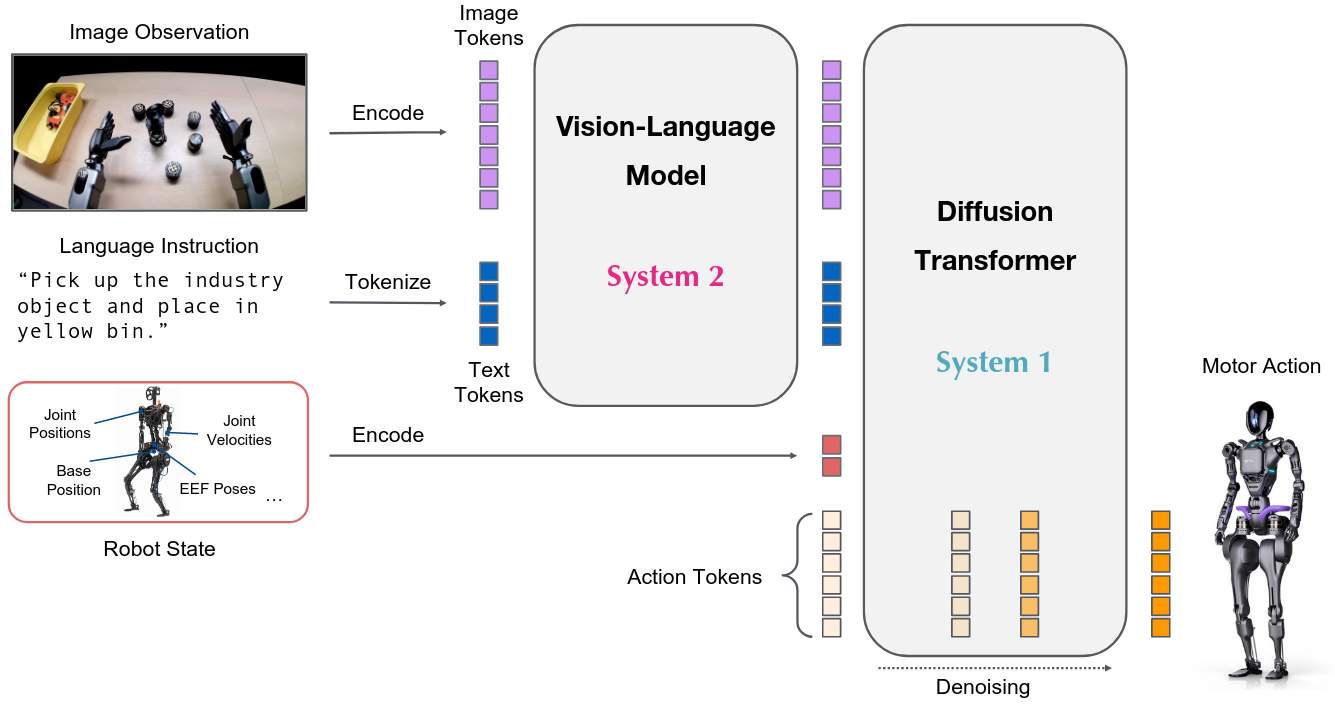
视觉-语言-动作模型,接收图像观察和语言指令作为输入,直接输出机器人动作。与传统的分层方法(VLM规划 + 低层策略执行)不同,VLA模型实现端到端优化。
受人类认知理论启发(Kahneman, 2011),将模型分为:
将异构训练数据按规模和具身特异性组织成三层结构:
通过VQ-VAE([[VQ-VAE-and-Latent-Action-for-Robotics]])学习的通用动作表示,能够统一不同具身体(包括人类)的动作空间,使无动作标签的视频数据可用于训练。
GR00T N1采用双系统组合架构,总参数量22亿(GR00T-N1-2B):
1 | 输入处理: |
关键设计:
1 | DiT Block结构(重复N次): |
动作生成流程:
Flow-Matching损失:
$$
\mathcal{L}{fm}(\theta) = \mathbb{E}{\tau} |V_{\theta}(\varphi_t, A_t^{\tau}, q_t) - (\epsilon - A_t)|^2
$$
其中 $V_{\theta}$ 是[[Diffusion-Transformers-DiT]]模型,预测去噪向量场。
1 | 信息流: |
端到端联合训练:
$$
\mathcal{L} = \mathcal{L}{fm} + \mathcal{L}{det}
$$
| 层级 | 数据源 | 时长 | 特点 |
|---|---|---|---|
| 顶层 | 真实机器人数据 | 3,289小时 | 具身特定,高质量 |
| 中层 | 仿真数据 | 1,743小时 | 可扩展,物理约束 |
| 中层 | 神经生成数据 | 827小时 | 反事实场景,多样性 |
| 底层 | 人类视频 | 2,517小时 | 大规模,通用先验 |
总计:8,376小时训练数据
VQ-VAE训练:
1 | # 编码器 |
跨具身一致性:
训练使用:
目标:从88小时真实数据扩增到827小时(~10倍)
技术流程:
1 | 步骤1: 微调视频生成模型 |
生成能力:
DexMimicGen系统:
1 | 输入: 少量人类演示(几十条) |
规模:
处理不同维度的状态和动作:
1 | embodiments = { |
预训练阶段:
后训练阶段:
在GR-1人形机器人上的零样本评估:
| 任务 | 成功率 | 说明 |
|---|---|---|
| 左手抓取→右手交接→放置 | 76.6% | 需要双手协调 |
| 新物体→新容器 | 73.3% | 泛化到未见物体 |
100条演示/任务的性能对比:
| 方法 | RoboCasa | DexMG | GR-1 | 平均 |
|---|---|---|---|---|
| BC-Transformer | 26.3% | 53.9% | 16.1% | 26.4% |
| Diffusion Policy | 25.6% | 56.1% | 32.7% | 33.4% |
| GR00T-N1-2B | 32.1% | 66.5% | 50.0% | 45.0% |
关键观察:
GR-1人形机器人任务成功率:
| 任务类型 | Diffusion Policy (10%数据) |
Diffusion Policy (全量数据) |
GR00T-N1-2B (10%数据) |
GR00T-N1-2B (全量数据) |
|---|---|---|---|---|
| 抓取放置 | 3.0% | 36.0% | 35.0% | 82.0% |
| 铰接物体 | 14.3% | 38.6% | 62.0% | 70.9% |
| 工业操作 | 6.7% | 61.0% | 31.0% | 70.0% |
| 多机协作 | 27.5% | 62.5% | 50.0% | 82.5% |
| 平均 | 10.2% | 46.4% | 42.6% | 76.8% |
数据效率:
RoboCasa基准(协同训练3K神经轨迹/任务):
| 数据量 | 仅真实数据 | +LAPA | +IDM |
|---|---|---|---|
| 30条 | 17.4% | 20.8% (+3.4%) | 20.0% (+2.6%) |
| 100条 | 32.1% | 38.5% (+6.4%) | 40.9% (+8.8%) |
| 300条 | 49.6% | 53.8% (+4.2%) | 56.4% (+6.8%) |
真实世界(协同训练100神经轨迹/任务):
观察:
运动质量:
泛化能力:
RoboCasa Kitchen(24任务):
DexMimicGen Cross-Embodiment Suite(9任务):
GR-1 Tabletop Tasks(24任务):
任务类别:
抓取放置(5任务):
铰接物体(3任务):
工业操作(3任务):
多机协作(2任务):
数据收集:
仿真:
真实机器人:
预训练:
后训练:
统一的跨具身学习:
卓越的数据效率:
可扩展的数据生成:
端到端优化:
开源生态:
任务范围限制:
合成数据质量:
硬件依赖:
泛化-专精权衡:
视觉-语言骨干限制:
VLA模型:
GR00T N1的区别:
真实机器人数据:
人类视频数据:
GR00T N1的创新:
仿真数据:
神经生成:
GR00T N1的规模:
长时域移动操作:
更强的视觉-语言骨干:
改进合成数据生成:
新型模型架构:
鲁棒性和泛化:
多模态感知:
长时域视频生成:
统一不同具身体的表示:
使用OWL-v2检测器标注目标物体边界框:
$$
\mathcal{L}{det} = |\mathbf{x}{pred} - \mathbf{x}_{gt}|^2
$$
其中 $\mathbf{x}$ 是归一化的边界框中心坐标。
VQ-VAE and Latent Action for Robotics

Neural Discrete Representation Learning | VQ-BeT: Behavior Generation with Latent Actions
在无监督学习和机器人学习领域,表示学习是核心问题之一。传统的变分自编码器(VAE, Variational AutoEncoder)使用连续潜在变量,但存在后验崩塌(posterior collapse)问题,即解码器过强导致忽略潜在编码。
在机器人学习中,直接学习连续高维动作空间面临以下挑战:
VQ-VAE(Vector Quantised-Variational AutoEncoder)通过引入离散潜在变量,为这些问题提供了有效的解决方案。
VQ-VAE是一种使用离散潜在变量的生成模型,通过向量量化(Vector Quantization)技术将编码器输出映射到离散的码本空间。
关键组件:
Latent Action是将连续动作序列编码为离散token的表示方法。每个离散token代表一个”动作原语”或”技能”,可以解码为一段连续的动作序列。
核心思想:
1 | 输入 x |
对于编码器输出的每个空间位置,找到最近的码本向量:
$$
z_q(\mathbf{x}) = \mathbf{e}_k, \quad \text{where} \quad k = \arg\min_j |\mathbf{z}_e(\mathbf{x}) - \mathbf{e}_j|_2
$$
VQ-VAE使用三部分损失函数:
$$
L = \log p(\mathbf{x}|\mathbf{z}_q(\mathbf{x})) + |\text{sg}[\mathbf{z}_e(\mathbf{x})] - \mathbf{e}|_2^2 + \beta |\mathbf{z}_e(\mathbf{x}) - \text{sg}[\mathbf{e}]|_2^2
$$
其中:
其中 $\text{sg}[\cdot]$ 表示stop gradient操作,阻止梯度传播。
问题:量化操作 $\mathbf{z}q = \arg\min{\mathbf{e}} |\mathbf{z}_e - \mathbf{e}|$ 不可微分
解决方案:在反向传播时,将解码器的梯度直接复制给编码器:
$$
\nabla_{\mathbf{z}e} L = \nabla{\mathbf{z}_q} L
$$
即在前向传播使用离散的 $\mathbf{z}_q$,在反向传播时假装量化操作是恒等映射。
以CIFAR-10图像重建为例:
| 阶段 | 数据形状 | 说明 |
|---|---|---|
| 输入图像 | [Batch, 32, 32, 3] |
原始RGB图像 |
| 编码器输出 $\mathbf{z}_e$ | [Batch, 8, 8, 64] |
空间下采样4倍,通道数64 |
| 量化后 $\mathbf{z}_q$ | [Batch, 8, 8, 64] |
形状不变,但值被离散化 |
| 解码器输出 | [Batch, 32, 32, 3] |
重建图像 |
信息压缩率:$(32 \times 32 \times 3) / (8 \times 8 \times \log_2 512) \approx 42$ 倍压缩(假设码本大小 $K=512$)
1 | 观察 o_t (图像/状态) |
输入:动作序列 $\mathbf{a}_{t:t+H} \in \mathbb{R}^{H \times d_a}$,其中 $H$ 是序列长度,$d_a$ 是动作维度
编码过程:
解码过程:
使用专家演示数据训练VQ-VAE:
1 | for batch in expert_demonstrations: |
固定VQ-VAE,训练策略在离散空间中选择动作:
1 | for batch in demonstrations: |
论文:Behavior Generation with Latent Actions (CoRL 2023)
核心思想:
优势:
核心思想:结合世界模型和latent action
1 | 当前状态 s_t |
将VQ-VAE学习的离散表示视为”技能”,在强化学习中进行技能级别的规划。
| 任务 | 指标 | 结果 |
|---|---|---|
| 图像重建(CIFAR-10) | 重建质量 | 与连续VAE相当 |
| 音频重建(VCTK) | 感知质量 | 接近原始音频 |
| 说话人分类 | 准确率 | 49.3%(从41维编码) |
| 视频建模 | 表示质量 | 成功捕获时序信息 |
| 参数 | 简单任务 | 复杂任务 | 说明 |
|---|---|---|---|
| 码本大小 $K$ | 16-64 | 128-512 | 过小表达能力不足,过大难以学习 |
| 序列长度 $H$ | 10-20 | 10-20 | 过小失去时序抽象,过大误差累积 |
| 编码维度 $D$ | 64-128 | 128-256 | 根据动作复杂度调整 |
VQ-BeT在多个机器人操作任务上的表现:
| 方法 | 成功率 | 多模态处理 | 训练稳定性 |
|---|---|---|---|
| 传统BC | 65% | 差 | 中等 |
| Diffusion Policy | 78% | 好 | 较慢 |
| VQ-BeT | 82% | 优秀 | 快速稳定 |
VQ-VAE本身:
在机器人中的优势:
VQ-VAE的挑战:
机器人应用的挑战:
层次化VQ-VAE:
与扩散模型结合:
在线学习与适应:
解决码本崩塌:
多模态机器人学习:
长时序任务规划:
迁移学习:
人机协作:
1 | import torch |
1 | class ActionEncoder(nn.Module): |

