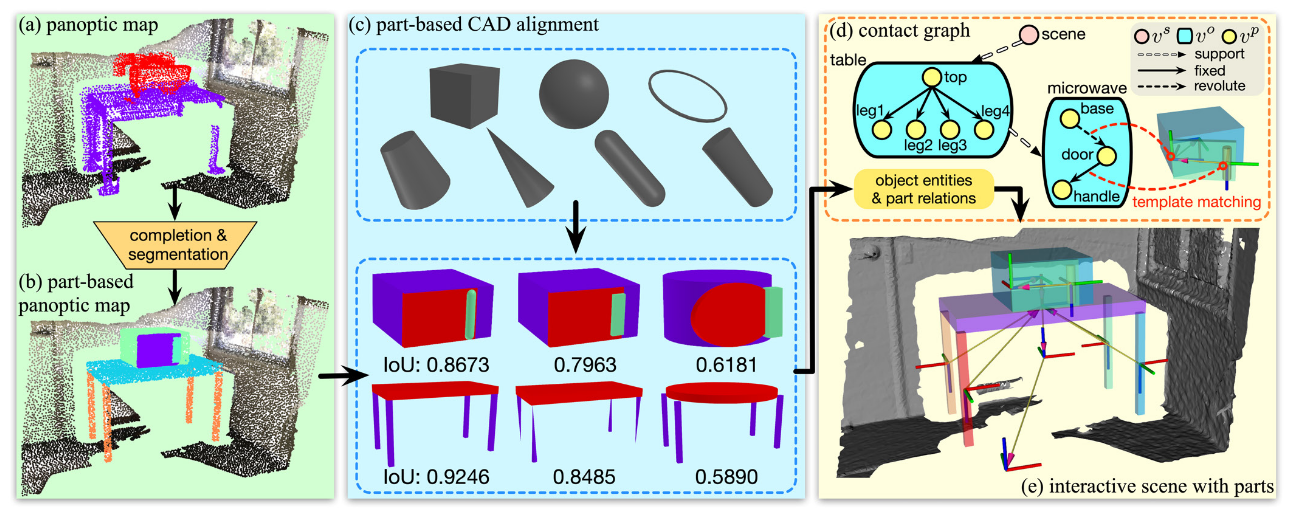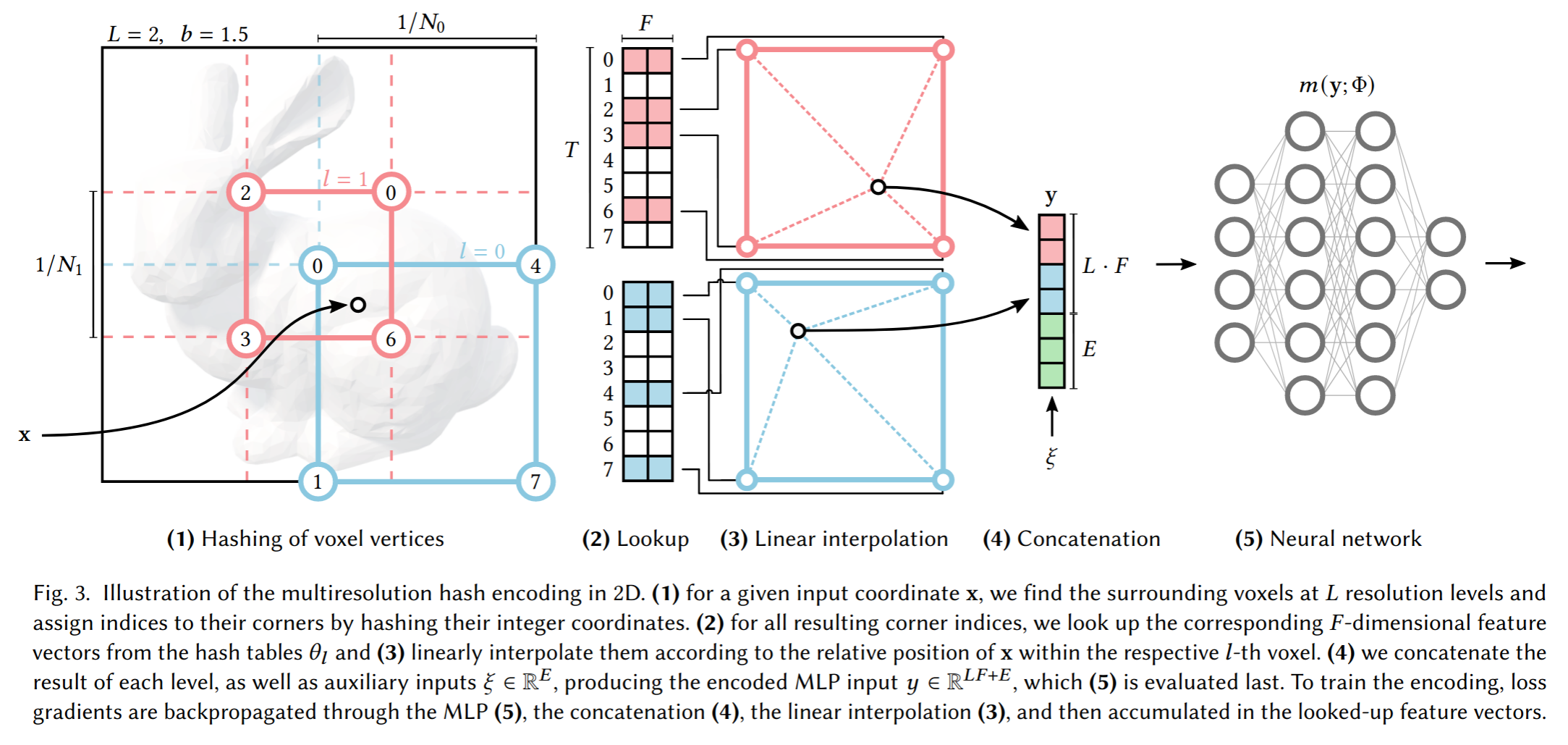
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
很重要的编码优化论文,MHE的概念:

Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
很重要的编码优化论文,MHE的概念:
SceneGraphFusion- Incremental 3D Scene Graph Predictionfrom RGB-D Sequences
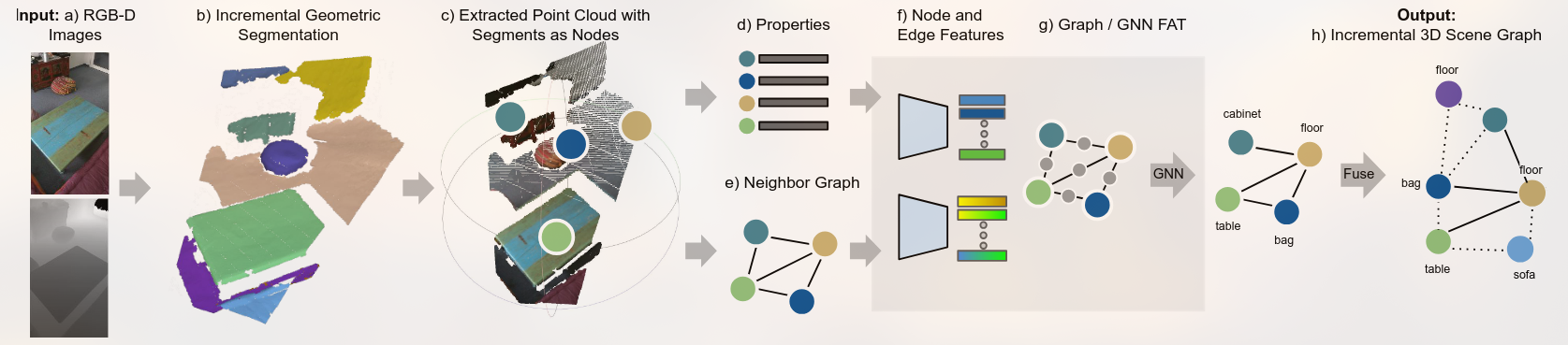
Overview of the proposed SceneGraphFusion framework. Our method takes a stream of RGB-D images a) as input to create an incremental geometric segmentation b). Then, the properties of each segment and a neighbor graph between segments are constructed. The properties d) and neighbor graph e) of the segments that have been updated in the current frame c) are used as the inputs to compute node and edge features f) and to predict a 3D scene graph g). Finally, the predictions are h) fused back into a globally consistent 3D graph.
Reconstruct Anything Literature Review
涉及的文章:
通过构建part-level scene-graph,结合Reasoning with LLM 让机器人能够实现更复杂的交互,并以此完成更复杂的任务。
Visual scene understanding长期以来一直被认为是计算机视觉的圣杯
Visual scene understanding 可以被分为两块任务
recognition task
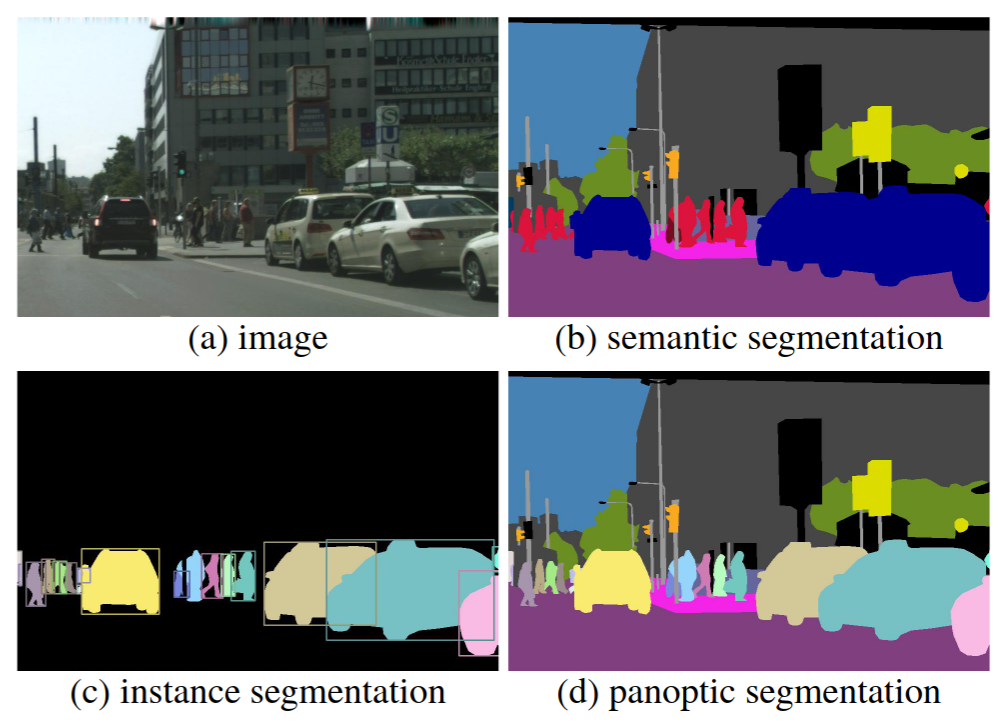
application task
但是以上这些Generally的工作注重的都是the localization of objects,更高级别的任务强调探索对象之间的丰富语义关系,以及对象与周围环境的相互作用
除此之外还有将NLP和CV结合起来的方向,主要是一些VLM
对于总体场景的感知和信息的有效表示仍然是瓶颈。
所以Li Feifei 在[[Image Retrieval using Scene Graphs]]提出Scene Graph
与Structured Representation相对的是Latent Representation
A scene graph is a structural representation, which can capture detailed semantics by explicitly Modeling
A scene graph is a set of visual relationship triplets in the form of <subject, relation, object> or <object, is, attribute>
Scene graphs should serve as an objective semantic representation of the state of the scene
Scene Graph具有应对和改善其他视觉任务的内在潜力。
可以解决的视觉任务包括:
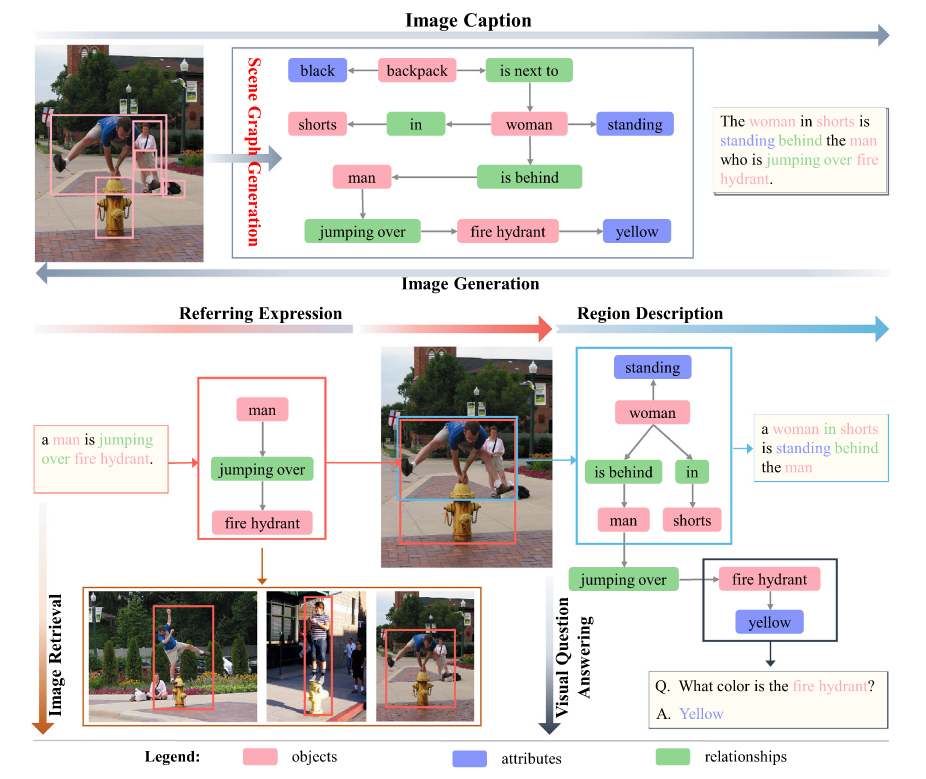
场景图生成的目的是解析图像或一系列图像,并且生成结构化表示,以此弥合视觉和语义感知之间的差距,并最终达到对视觉场景的完整理解。
任务的本质是检测视觉关系。
早先由Feifei [[Visual Relationship Detection with Language Priors]] 提出了视觉关系检测的方法。
以及Visual Genome这个包含物体关系的数据集
Detects objects first and then solves a classification task to determine the relationship between each pair of objects
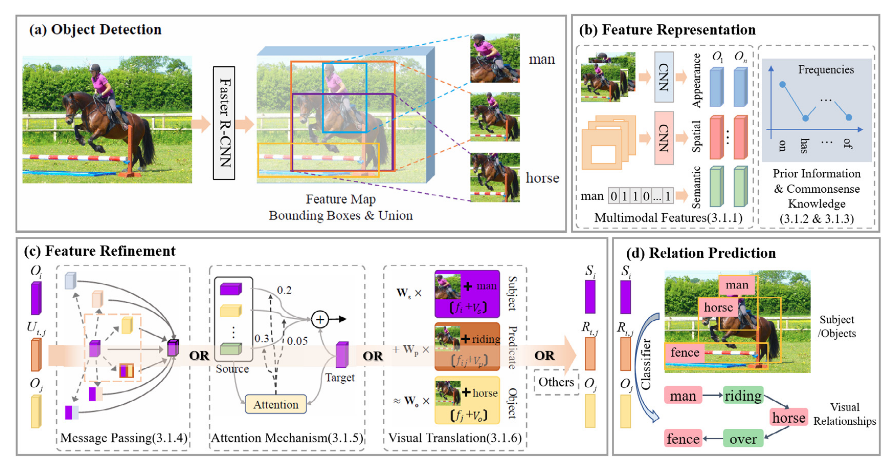
b) 提取每个区域的特征。包括object的appearance, spatial information, label, depth, and mask;predicate的appearance, spatial, depth, and mask。
c) 这些多模态特征被 vectorized, combined, and refined。可以通过:
d) 分类器用于预测predicate的类别
基于Visual translation embedding的
Simultaneously detects and recognizes objects and relations
相较于two-stage:
基本都是基于LLM或者VLM之类的大模型
这里所有的工作都是关于如何判断两个独立物体之间的谓语关系(例如riding, holding…),并没有涉及part-level relationship的工作。part-level的父子关系和object-level的谓语关系是很不一样的。
即场景信息存储在一个神经网络中,并没有显式的结构,规划器(可以是LLM)通过query这个模型来获得信息。
核心思想是用交互更丰富的模型组合成可交互的替代场景。
主要用于建模物体之间的运动学关系
将 scene graph 用于机器人任务理解和规划
Scene Reconstruction with Functional Objects for Robot Autonomy
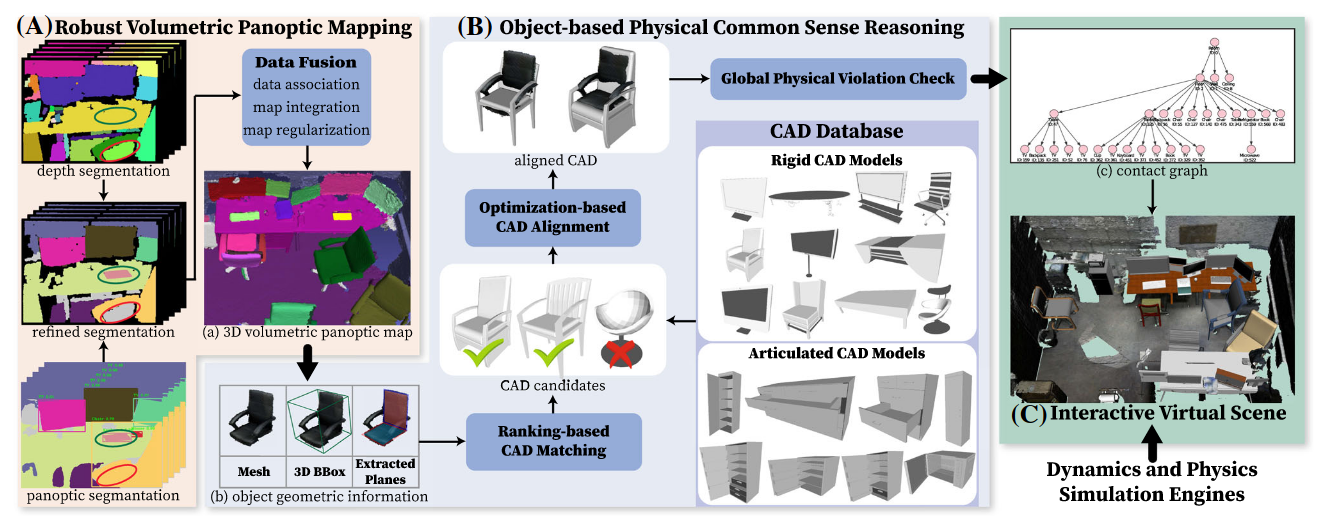
和李飞飞[[ACDC- Automated Creation of Digital Cousins for Robust Policy Learning]]的思想类似。

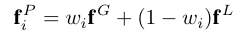
将不同帧$X_t$中的特征集合在M中特征点的公式:
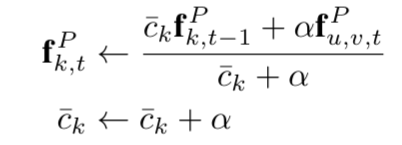

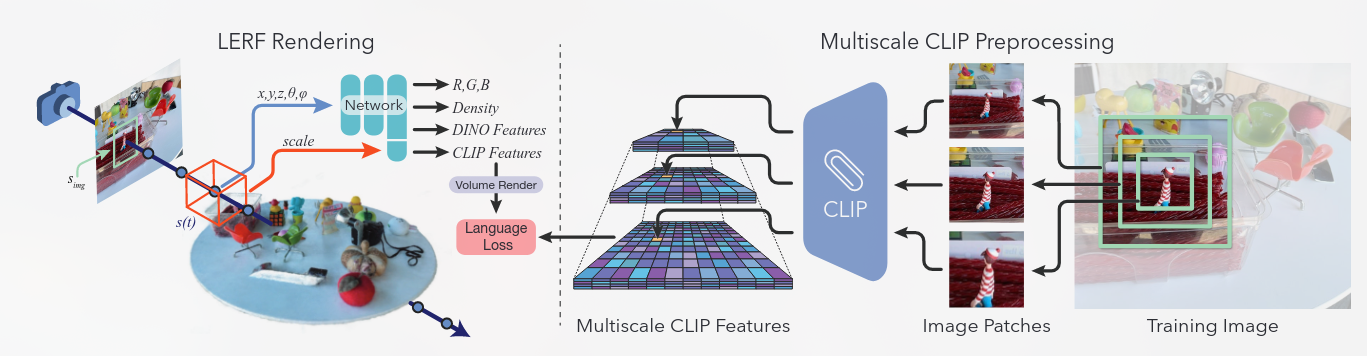
LERF- Language Embedded Radiance Fields

NeRF+CLIP
一个Language Field
通过优化从现成的视觉语言模型(如 CLIP)到 3D 场景的嵌入,为 NeRF 中的语言奠定基础。
LERF 提供了一个额外的好处:由于我们从多个尺度的多个视图中提取 CLIP 嵌入,因此通过 3D CLIP 嵌入获得的文本查询的相关性图与通过 2D CLIP 嵌入获得的文本查询的相关性图相比更加本地化。根据定义,它们也是 3D 一致的,可以直接在 3D 字段中进行查询,而无需渲染到多个视图。
相较于Clip-Field[[CLIP-Fields- Weakly Supervised Semantic Fields for Robotic Memory]], LERF 更密集。
CLIP-Fields [32] and NLMaps-SayCan [8] fuse CLIP embeddings of crops into pointclouds, using a contrastively supervised field and classical pointcloud fusion respectively. In CLIP-Fields, the crop locations are guided by Detic [40]. On the other hand, NLMaps-SayCan relies on region proposal networks. These maps are sparser than LERF as they primarily query CLIP on detected objects rather than densely throughout views of the scene. Concurrent work ConceptFusion [19] fuses CLIP features more densely in RGBD pointclouds, using Mask2Former [9] to predict regions of interest, meaning it can lose objects which are out of distribution to Mask2Former’s training set. In contrast, LERF does not use region or mask proposals.
Some Thoughts Regarding -Reconstruct Anything-
主要记录一些读场景语义化重建的论文的过程中的想法
限定:暂不考虑机器人的移动性,也就是不需要跨视野的导航(OK-Robot),暂定为桌面机器人
具体来说,通用机器人的特点包括:
受DINO自蒸馏自监督的启发,可以通过物体活动的图像序列来推测物体各个部分的物理关系(attention map)[[DINO]]
训练集可以使用Unity生成不同的光影/物体,连接语义
voxel collider for detected objects, joints, physics agent interact with physics engine.
点云数据,grounded caption=>object property, hierarchy relation, joints(maybe new model should be proposed)
受[[BLIP]]启发,understanding for language & existing point cloud, generation for the rest of the point cloud (Wonder3D已实现)
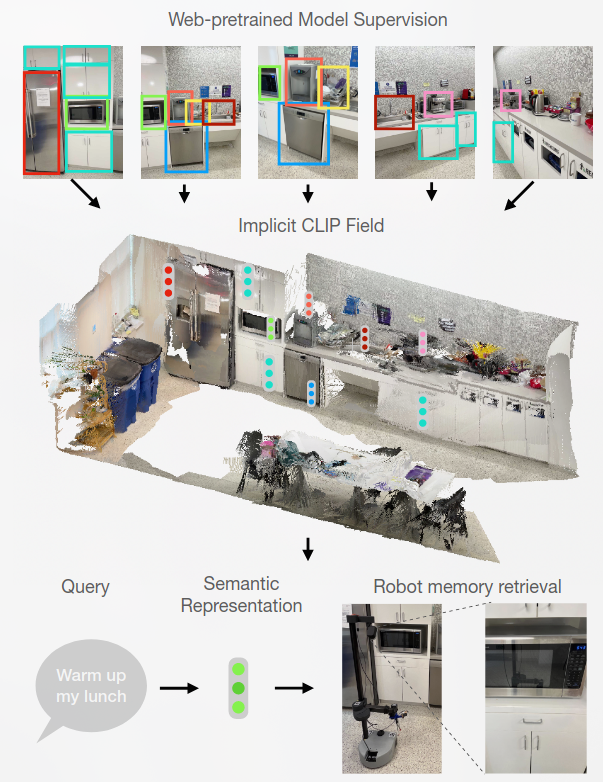
CLIP-Fields- Weakly Supervised Semantic Fields for Robotic Memory
疑问:
A spatial-semantic memory
是一个隐式场景模型,可用于各种任务,例如分割、实例识别、空间语义搜索和视图定位
CLIP-Fields 学习从空间位置到语义嵌入向量的映射。
这种映射可以仅通过来自网络图像和网络文本训练模型(例如 CLIP[[CLIP多模态预训练模型]]、Detic 和 Sentence-BERT)的监督进行训练;因此不使用直接的人类监督。
We aim to build a system that can connect points of a 3D scene with their visual and semantic meaning.
Provide an interface with a pair of scene-dependent implicit functions $f, h : R^3 → R^n$ such that for the coordinates of any point P in our scene, f (P ) is a vector representing its semantic features, and h(P ) is another vector representing its visual features.
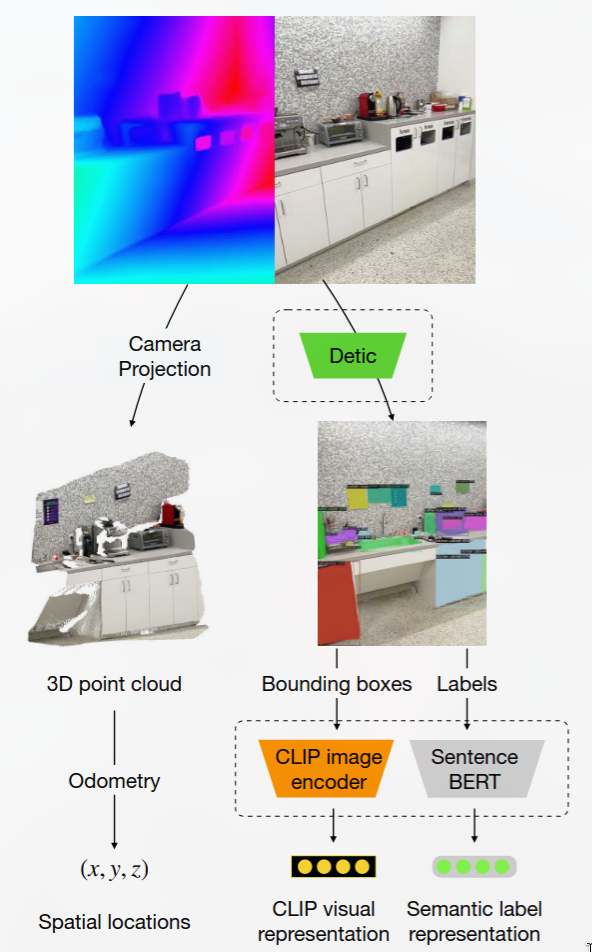
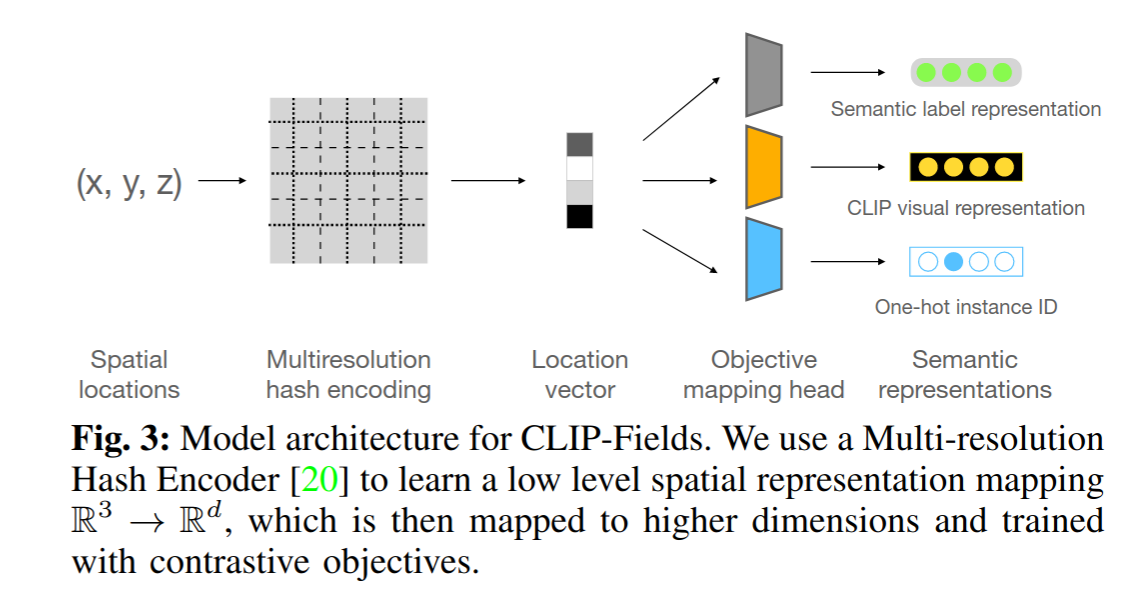
貌似每针对一个新场景都需要重新train一遍来获得坐标到语义的映射。
OK-Robot- What Really Matters in Integrating Open-Knowledge Models for Robotics

Creating a general-purpose robot has been a longstanding dream of the robotics community.
当前想要实现这一目标的系统脆弱、封闭,并且在遇到未见过的情况时会失败。即使是最大的机器人模型通常也只能部署在以前见过的环境中 [5, 6]。在机器人数据很少的环境中,例如在非结构化的家庭环境中,这些系统的脆弱性会进一步加剧。
虽然大型视觉模型显示出语义理解 、检测以及将视觉表示与语言联系起来的能力并且与此同时,机器人的导航、抓取和重新排列等基本机器人技能已经相当成熟。
但是将现代视觉模型与机器人特定基元相结合的机器人系统表现非常差。
这可能是因为单纯将多个不确定性的系统组合在一起会导致准确率急剧恶化。
所以我们需要一个将VLM和机器人primitives(导航,抓取,放置)结合在一起的细致框架,即OK-Robot。
Pick up A (from B) and drop it on/in C”, where A is an object and B and C are places in a real-world environment such as homes
负责空间重建,识别物体大致位置,机器人导航
用到的方法: