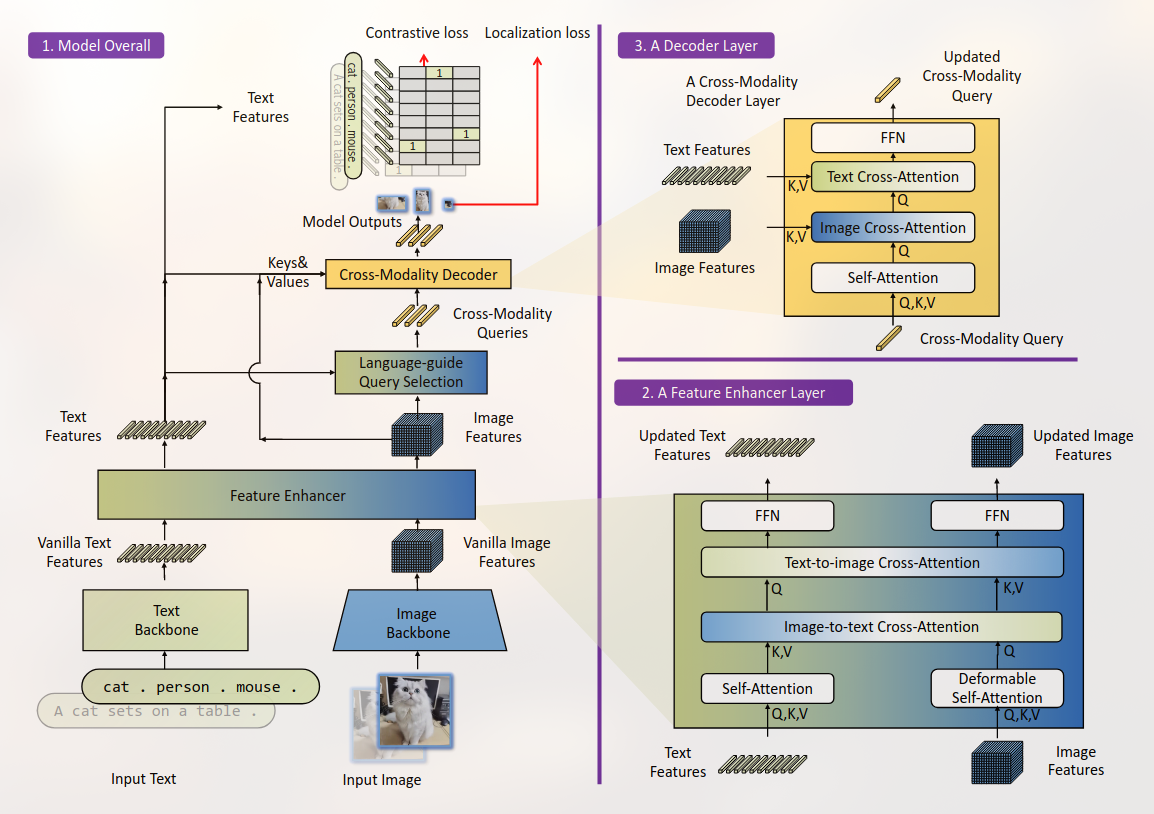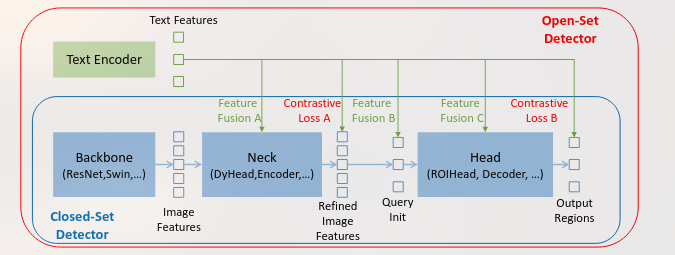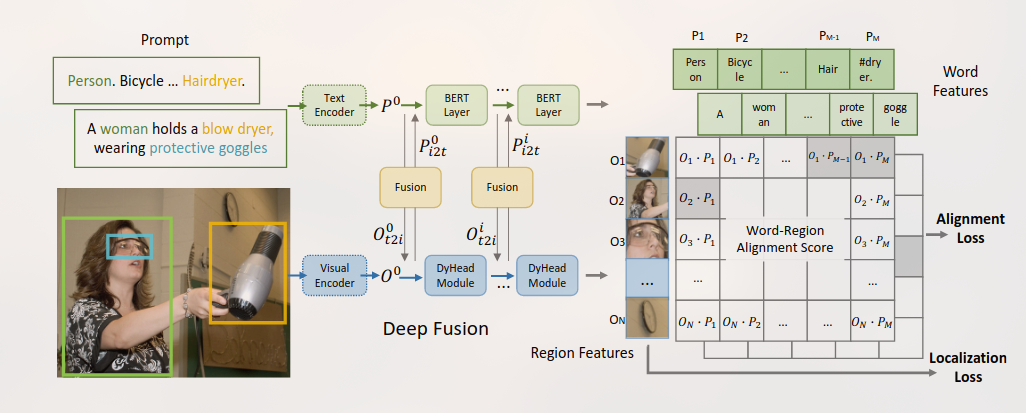
GLIP是一个学习了object-level, language-aware, and semantic-rich visual representations 的模型。
统一对象检测和短语接地进行预训练。
重要的问题
什么是 phrase grounding:
Phrase Grounding refers to the task of associating or “grounding” a natural language phrase (like a sentence or a word) to a specific region or object in an image. In other words, it’s about finding which part of the image corresponds to the object or concept described by a given text phrase.
For instance, if you have the phrase “the red ball on the table” and an image of a room with a red ball placed on a table, the goal of phrase grounding is to identify the exact region in the image that corresponds to the “red ball on the table”, distinguishing it from other objects in the image.
Unified Formulation
传统的物体检测方法会把每个region分类进c个classes,而本文使用的Object detection as phrase grounding.
我们通过将每个区域与文本提示中的c(class)短语进行接地/对齐,将检测重新制定为基础任务
the classification prompt “person. bicycle. car. … . toothbrush”