作者:Siyuan Mu (四川农业大学), Sen Lin (休斯顿大学)
研究背景
随着AI基础大模型的快速发展,现代数据集变得越来越多样化和复杂,包含多模态数据(文本、图像、音频)和复杂结构(图、层次关系)。这给大模型发展带来两大挑战:
- 计算资源消耗巨大:训练和部署大模型的计算成本呈指数增长
- 异构数据拟��困难:在单一模型中整合冲突或异构知识变得困难,导致训练不稳定和性能次优
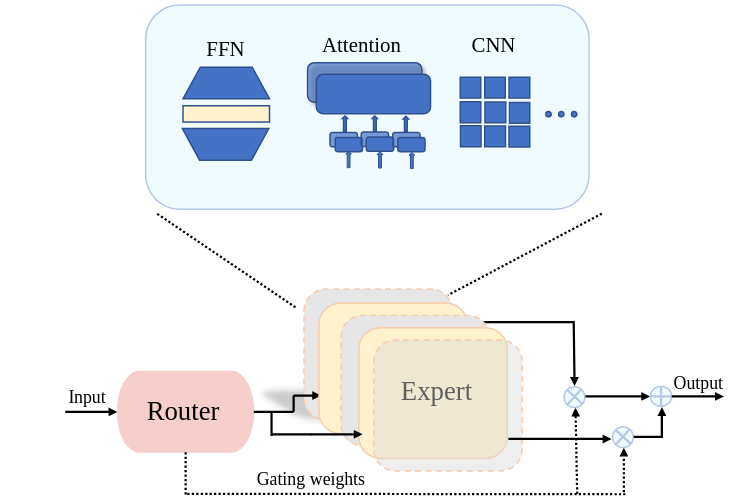
混合专家模型(Mixture of Experts, MoE)通过动态选择和激活最相关的子模型来处理输入数据,成为解决这些挑战的有效方案。
研究目标
- 填补现有MoE综述的空白(过时或缺乏关键领域讨论)
- 全面总结MoE的基础设计、算法、理论和应用四大关键组件
- 为研究者提供系统性参考,激发进一步研究
核心概念
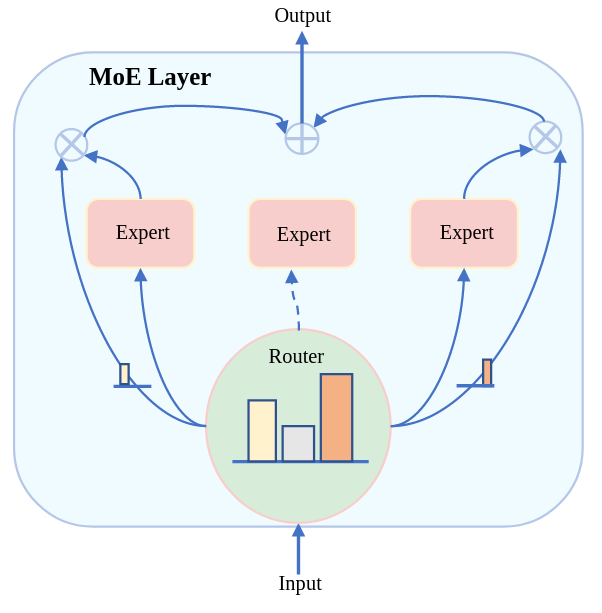
MoE基本原理
MoE采用”分而治之”(divide and conquer)策略,与传统密集模型不同:
- 传统模型:对每个输入激活所有参数
- MoE模型:根据输入特征动态选择和激活最相关的参数子集
MoE层数学表示
$$
\text{MoE}(x) = \sum_{i \in \mathcal{I}_D} w_i M_i(x)
$$
其中 $\mathcal{I}_D$ 是被选中专家的索引集,$w_i$ 是第 $i$ 个专家的权重,$M_i(x)$ 是专家网络输出。
研究方法
1. 门控函数(Gating Function)
线性门控(Softmax Gating)
$$
G(x)i = \text{softmax}(\text{TopK}(g(x) + R{noise}, k))i
$$
其中 $g(x)$ 是线性函数计算的门控值,$R{noise}$ 是鼓励专家探索的噪声。
非线性门控
- 余弦门控(GMoE):
$$
G(x) = \text{TopK}\left(\text{softmax}\left(\frac{E^T W_{linear} x}{\tau |W_{linear} x| |E|}\right)\right)
$$ - 指数族分布门控
- Soft MoE:使用加权平均而非离散分配
2. 专家网络(Expert Network)
| 类型 | 描述 | 应用场景 |
|---|---|---|
| FFN专家 | 替换Transformer中的FFN层 | 最常用,如Switch Transformer |
| MoA(混合注意力) | 将MoE应用于注意力模块 | 图像生成、多模态任务 |
| CNN专家 | 将MoE应用于CNN层 | 计算机视觉任务 |
3. 路由策略(Routing Strategy)
- Token级路由:基于token表示进行路由决策(最经典)
- 模态级路由:根据数据模态进行路由(多模态任务)
- 任务级路由:根据任务ID确定路由(多任务学习)
4. 训练策略
负载均衡损失(Switch Transformer)
$$
\mathcal{L}{aux} = \alpha \cdot N \cdot \sum{i=1}^{N} f_i \cdot Q_i
$$
其中 $f_i$ 是分配给专家 $i$ 的token比例,$Q_i$ 是路由概率比例。
MoA(Mixture-of-Attention)详解
基本架构
MoA将MoE机制引入多头注意力模块,每个注意力头视为一个”专家”。
工作流程
- 输入token进入MoA层
- 门控网络计算每个注意力头的重要性分数
- 选择TopK个最相关的注意力头
- 仅计算被选中头的输出并加权求和
代码实现核心
1 | class MixtureOfAttention(nn.Module): |
MoA vs 标准多头注意力
| 特性 | 标准多头注意力 | MoA |
|---|---|---|
| 头激活 | 所有头同时激活 | 动态选择部分头 |
| 计算开销 | 与头数量成正比 | 仅计算被选中的头 |
| 可扩展性 | 增加头数直接增加计算量 | 可扩展更多头而不显著增加计算 |
主要发现
算法应用领域
| 领域 | 代表性工作 | 核心贡献 |
|---|---|---|
| 持续学习 | CN-DPM, Lifelong-MoE, PMoE | 缓解灾难性遗忘 |
| 元学习 | MoE-NPs, MixER, Meta-DMoE | 增强快速适应能力 |
| 多任务学习 | MMoE, MOOR, TaskExpert | 解耦任务、减少干扰 |
| 强化学习 | MMRL, MACE, MENTOR | 处理非平稳环境 |
应用领域
| 领域 | 任务 | 代表性工作 |
|---|---|---|
| 计算机视觉 | 图像分类 | V-MoE, Soft MoE, CLIP-MoE |
| 目标检测 | MoCaE, DAMEX | |
| 语义分割 | DeepMoE, Swin2-MoSE | |
| 图像生成 | RAPHAEL, MEGAN | |
| 自然语言处理 | NLU | GLaM, MoE-LPR |
| 机器翻译 | GShard, NLLB | |
| 多模态融合 | LIMoE, LLaVA-MoLE |
代表性大模型
| 模型 | 参数规模 | 主要成就 |
|---|---|---|
| Switch Transformer | 万亿级 | 预训练速度比T5-Base快7倍 |
| GLaM | 万亿级 | 增强上下文信息利用能力 |
| Mixtral 8×7B | 470亿(激活130亿) | 高参数效率 |
| DeepSeek系列 | - | 多项基准SOTA |
讨论
优势
- 计算效率:通过稀疏激活显著降低计算成本
- 模型容量:可扩展至万亿参数而不成比例增加计算
- 专业化学习:不同专家专注于不同知识领域
- 可解释性:通过分析专家分配机制理解模型行为
局限性
- 训练稳定性:动态专家选择可能导致负载不均衡和模型崩溃
- 系统复杂性:All-to-All通信模式增加系统设计难度
- 内存需求:多专家参数存储可能超出单设备容量
未来方向
- 训练稳定性与负载均衡:开发更鲁棒的训练策略
- 训练与系统效率:优化硬件-软件协同设计
- 架构设计:使用元学习或强化学习动态调整专家数量
- 理论发展:深入理解专家路由决策和聚类机制
- 定制算法设计:探索MoE与对比学习、自监督学习的结合
- 新应用领域:医疗、机器人、自动驾驶、教育、金融
相关工作
- Switch Transformer:首个万亿参数MoE模型
- V-MoE:视觉领域MoE应用
- Mixtral 8×7B:高效MoE语言模型
- Soft MoE:软分配MoE新范式
- [[BAGEL-Unified-Multimodal-Pretraining]]
参考文献
- Fedus et al. (2022). Switch Transformers: Scaling to Trillion Parameter Models. JMLR.
- Shazeer et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv.
- Riquelme et al. (2021). Scaling Vision with Sparse Mixture of Experts. NeurIPS.
- Jiang et al. (2024). Mixtral of Experts. arXiv.