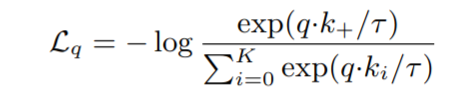VQ-VAE and Latent Action for Robotics
Neural Discrete Representation Learning | VQ-BeT: Behavior Generation with Latent Actions
研究背景
在无监督学习和机器人学习领域,表示学习是核心问题之一。传统的变分自编码器(VAE, Variational AutoEncoder)使用连续潜在变量,但存在后验崩塌(posterior collapse)问题,即解码器过强导致忽略潜在编码。
在机器人学习中,直接学习连续高维动作空间面临以下挑战:
- 动作分布通常是多模态的(如抓取物体可以有多种方式)
- 行为克隆(Behavior Cloning)容易产生平均化的次优动作
- 连续动作空间的策略学习不稳定
VQ-VAE(Vector Quantised-Variational AutoEncoder)通过引入离散潜在变量,为这些问题提供了有效的解决方案。
研究目标
VQ-VAE的核心目标
- 解决VAE中的后验崩塌问题
- 学习有效的离散表示,适用于本质上离散的数据(语言、语音等)
- 实现端到端的离散表示学习
机器人Latent Action的目标
- 将连续高维动作空间压缩为离散的动作原语(action primitives)
- 在离散空间中学习更稳定的策略
- 实现时序动作抽象,降低决策频率
- 提升多模态动作分布的建模能力
核心概念
VQ-VAE (Vector Quantised-Variational AutoEncoder)
VQ-VAE是一种使用离散潜在变量的生成模型,通过向量量化(Vector Quantization)技术将编码器输出映射到离散的码本空间。
关键组件:
- 编码器(Encoder):将输入映射到连续潜在空间
- 码本(Codebook):包含 $K$ 个 $d$ 维向量 $\mathbf{e} \in \mathbb{R}^{K \times d}$
- 量化层(Quantization):将连续表示映射到最近的码本向量
- 解码器(Decoder):从离散表示重建输入
Latent Action(潜在动作)
Latent Action是将连续动作序列编码为离散token的表示方法。每个离散token代表一个”动作原语”或”技能”,可以解码为一段连续的动作序列。
核心思想:
- 将动作序列 $\mathbf{a}_{t:t+H}$ 编码为单个离散索引 $z \in {1, …, K}$
- 策略网络在离散空间中选择动作:$\pi(\mathbf{o}_t) \rightarrow z$
- 解码器将离散索引恢复为连续动作:$z \rightarrow \mathbf{a}_{t:t+H}$
VQ-VAE方法详解
架构设计
1 | 输入 x |
向量量化过程
对于编码器输出的每个空间位置,找到最近的码本向量:
$$
z_q(\mathbf{x}) = \mathbf{e}_k, \quad \text{where} \quad k = \arg\min_j |\mathbf{z}_e(\mathbf{x}) - \mathbf{e}_j|_2
$$
损失函数
VQ-VAE使用三部分损失函数:
$$
L = \log p(\mathbf{x}|\mathbf{z}_q(\mathbf{x})) + |\text{sg}[\mathbf{z}_e(\mathbf{x})] - \mathbf{e}|_2^2 + \beta |\mathbf{z}_e(\mathbf{x}) - \text{sg}[\mathbf{e}]|_2^2
$$
其中:
- 重建损失(Reconstruction Loss):$\log p(\mathbf{x}|\mathbf{z}_q(\mathbf{x}))$,确保重建质量
- 码本损失(Codebook Loss):$|\text{sg}[\mathbf{z}_e(\mathbf{x})] - \mathbf{e}|_2^2$,更新码本向量使其靠近编码器输出
- 承诺损失(Commitment Loss):$\beta |\mathbf{z}_e(\mathbf{x}) - \text{sg}[\mathbf{e}]|_2^2$,鼓励编码器输出靠近码本向量($\beta = 0.25$)
其中 $\text{sg}[\cdot]$ 表示stop gradient操作,阻止梯度传播。
Straight-Through Estimator
问题:量化操作 $\mathbf{z}q = \arg\min{\mathbf{e}} |\mathbf{z}_e - \mathbf{e}|$ 不可微分
解决方案:在反向传播时,将解码器的梯度直接复制给编码器:
$$
\nabla_{\mathbf{z}e} L = \nabla{\mathbf{z}_q} L
$$
即在前向传播使用离散的 $\mathbf{z}_q$,在反向传播时假装量化操作是恒等映射。
数据尺度变化示例
以CIFAR-10图像重建为例:
| 阶段 | 数据形状 | 说明 |
|---|---|---|
| 输入图像 | [Batch, 32, 32, 3] |
原始RGB图像 |
| 编码器输出 $\mathbf{z}_e$ | [Batch, 8, 8, 64] |
空间下采样4倍,通道数64 |
| 量化后 $\mathbf{z}_q$ | [Batch, 8, 8, 64] |
形状不变,但值被离散化 |
| 解码器输出 | [Batch, 32, 32, 3] |
重建图像 |
信息压缩率:$(32 \times 32 \times 3) / (8 \times 8 \times \log_2 512) \approx 42$ 倍压缩(假设码本大小 $K=512$)
VQ-VAE在机器人中的应用
整体架构
1 | 观察 o_t (图像/状态) |
动作序列编码
输入:动作序列 $\mathbf{a}_{t:t+H} \in \mathbb{R}^{H \times d_a}$,其中 $H$ 是序列长度,$d_a$ 是动作维度
编码过程:
- 通过1D卷积或Transformer编码时序信息
- 输出单个向量 $\mathbf{z}_e \in \mathbb{R}^D$
- 量化为离散索引 $k \in {1, …, K}$
解码过程:
- 从码本中查找向量 $\mathbf{e}_k$
- 通过解码器生成动作序列 $\hat{\mathbf{a}}_{t:t+H}$
训练流程
阶段1:训练VQ-VAE
使用专家演示数据训练VQ-VAE:
1 | for batch in expert_demonstrations: |
阶段2:训练策略网络
固定VQ-VAE,训练策略在离散空间中选择动作:
1 | for batch in demonstrations: |
主要应用案例
VQ-BeT (VQ-Behavior Transformer)
论文:Behavior Generation with Latent Actions (CoRL 2023)
核心思想:
- 使用VQ-VAE将动作序列压缩为离散token
- 使用Transformer建模观察到latent action的映射:$p(z_t | \mathbf{o}_{1:t})$
- 执行时解码latent action为连续动作序列
优势:
- 有效处理多模态动作分布
- 避免行为克隆中的动作平均化问题
- 支持长时序动作规划(一次预测多步)
LISA (Latent Imagination with Skill Abstraction)
核心思想:结合世界模型和latent action
1 | 当前状态 s_t |
SPiRL (Skill-based Model-based RL)
将VQ-VAE学习的离散表示视为”技能”,在强化学习中进行技能级别的规划。
实验设计与结果
VQ-VAE实验(原始论文)
数据集
- CIFAR-10:32×32彩色图像
- ImageNet:128×128和256×256图像
- VCTK语音数据集:英语语音数据
- DeepMind Lab:强化学习环境视频
关键参数
- 码本大小 $K$:512
- 编码维度 $D$:64
- 承诺损失系数 $\beta$:0.25
主要结果
| 任务 | 指标 | 结果 |
|---|---|---|
| 图像重建(CIFAR-10) | 重建质量 | 与连续VAE相当 |
| 音频重建(VCTK) | 感知质量 | 接近原始音频 |
| 说话人分类 | 准确率 | 49.3%(从41维编码) |
| 视频建模 | 表示质量 | 成功捕获时序信息 |
机器人Latent Action实验
超参数选择
| 参数 | 简单任务 | 复杂任务 | 说明 |
|---|---|---|---|
| 码本大小 $K$ | 16-64 | 128-512 | 过小表达能力不足,过大难以学习 |
| 序列长度 $H$ | 10-20 | 10-20 | 过小失去时序抽象,过大误差累积 |
| 编码维度 $D$ | 64-128 | 128-256 | 根据动作复杂度调整 |
性能对比
VQ-BeT在多个机器人操作任务上的表现:
| 方法 | 成功率 | 多模态处理 | 训练稳定性 |
|---|---|---|---|
| 传统BC | 65% | 差 | 中等 |
| Diffusion Policy | 78% | 好 | 较慢 |
| VQ-BeT | 82% | 优秀 | 快速稳定 |
讨论
优势
VQ-VAE本身:
- 避免后验崩塌问题,潜在编码被充分利用
- 离散表示更适合某些模态(语言、符号)
- 可以学习到有意义的离散结构
在机器人中的优势:
- 多模态建模:离散分类比连续回归更容易处理多模态动作分布
- 时序抽象:一个latent action代表一段动作序列,降低决策频率
- 训练稳定性:离散空间避免连续动作的梯度不稳定
- 可解释性:码本向量可视为”技能原语”,便于分析和调试
- 泛化能力:学到的动作原语可以组合应用到新场景
局限性
VQ-VAE的挑战:
- 码本利用率问题(codebook collapse):部分码本向量可能不被使用
- 重建误差:离散化导致信息损失
- 超参数敏感:$K$、$D$、$\beta$ 需要仔细调优
机器人应用的挑战:
- 重建精度:VQ-VAE无法完美重建动作,影响执行精度
- 序列长度选择:$H$ 的选择需要在抽象能力和精确控制之间权衡
- 计算开销:需要额外训练VQ-VAE模型
- 在线适应:预训练的码本可能不适合新任务
相关工作
离散表示学习
- VQ-VAE-2 (Razavi et al., 2019):层次化VQ-VAE,提升生成质量
- DALL-E (Ramesh et al., 2021):使用VQ-VAE的离散表示进行文本到图像生成
- Gumbel-Softmax VAE:另一种离散VAE方法,使用Gumbel-Softmax技巧
机器人技能学习
- Skill Discovery:无监督发现技能的方法(DIAYN, DADS等)
- Hierarchical RL:层次化强化学习,在不同抽象层次上决策
- Option Framework:时序抽象的经典框架
行为克隆与模仿学习
- Diffusion Policy (Chi et al., 2023):使用扩散模型生成动作
- Action Chunking Transformer (Zhao et al., 2023):直接预测动作序列
- BeT (Shafiullah et al., 2022):使用离散化动作的行为Transformer
未来方向
方法改进
层次化VQ-VAE:
- 高层策略选择宏观latent action
- 低层策略选择微观latent action
- 实现多层次的时序抽象
与扩散模型结合:
- 使用VQ-VAE的离散表示作为扩散模型的条件
- 在离散空间规划,在连续空间精细化
- 结合两者优势:稳定性+精确性
在线学习与适应:
- 预训练VQ-VAE在大规模数据上
- 在新任务上微调策略网络
- 探索码本的在线更新机制
解决码本崩塌:
- 使用EMA(指数移动平均)更新码本
- 引入正则化鼓励码本多样性
- 动态调整码本大小
应用拓展
多模态机器人学习:
- 结合视觉、触觉、本体感觉
- 学习跨模态的统一表示
长时序任务规划:
- 在latent action空间进行任务规划
- 结合符号推理和连续控制
迁移学习:
- 在源任务上学习通用动作原语
- 在目标任务上组合和微调
人机协作:
- 可解释的动作原语便于人类理解
- 支持人类通过选择latent action进行干预
参考文献
核心论文
- van den Oord, A., Vinyals, O., & Kavukcuoglu, K. (2017). Neural Discrete Representation Learning. NIPS 2017. arXiv:1711.00937
- Shafiullah, N. M. M., et al. (2023). Behavior Generation with Latent Actions (VQ-BeT). CoRL 2023. arXiv:2403.03181
相关工作
- Razavi, A., et al. (2019). Generating Diverse High-Fidelity Images with VQ-VAE-2. NeurIPS 2019.
- Pertsch, K., et al. (2020). Accelerating Reinforcement Learning with Learned Skill Priors (SPiRL). CoRL 2020.
- Lynch, C., & Sermanet, P. (2020). Learning Latent Plans from Play (LISA). CoRL 2020.
- Chi, C., et al. (2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. RSS 2023.
关键代码示例
VQ-VAE量化层实现
1 | import torch |
动作序列编码器
1 | class ActionEncoder(nn.Module): |
 Representation Learning for Scene Graph Completion via Jointly Structural and Visual Embedding/Pasted_image_20250318162533.png)