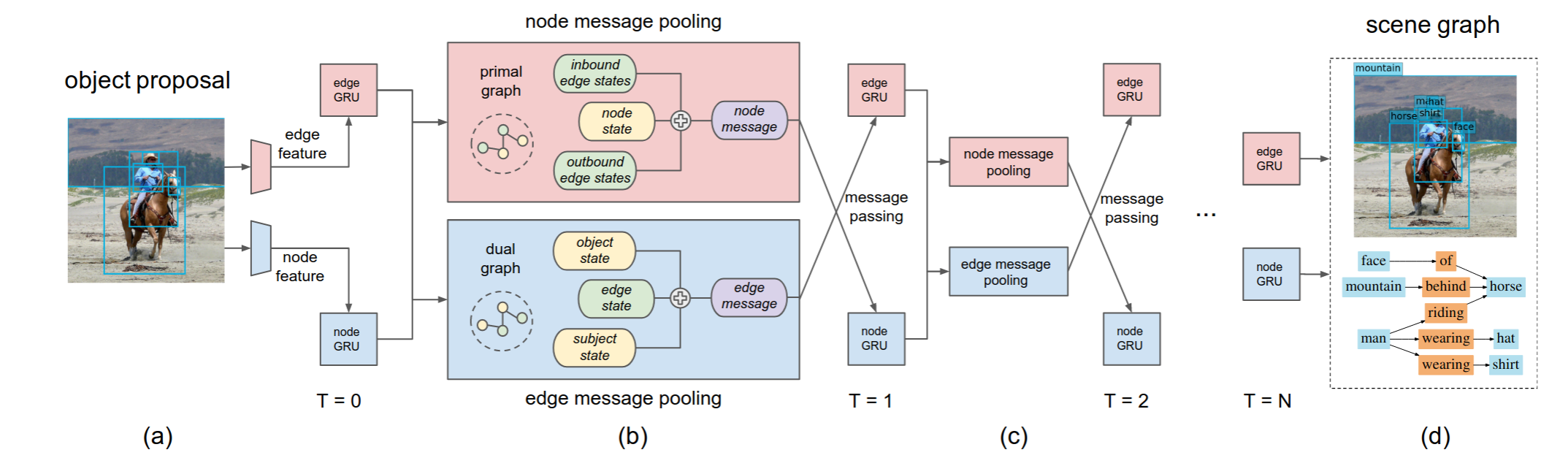
ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning
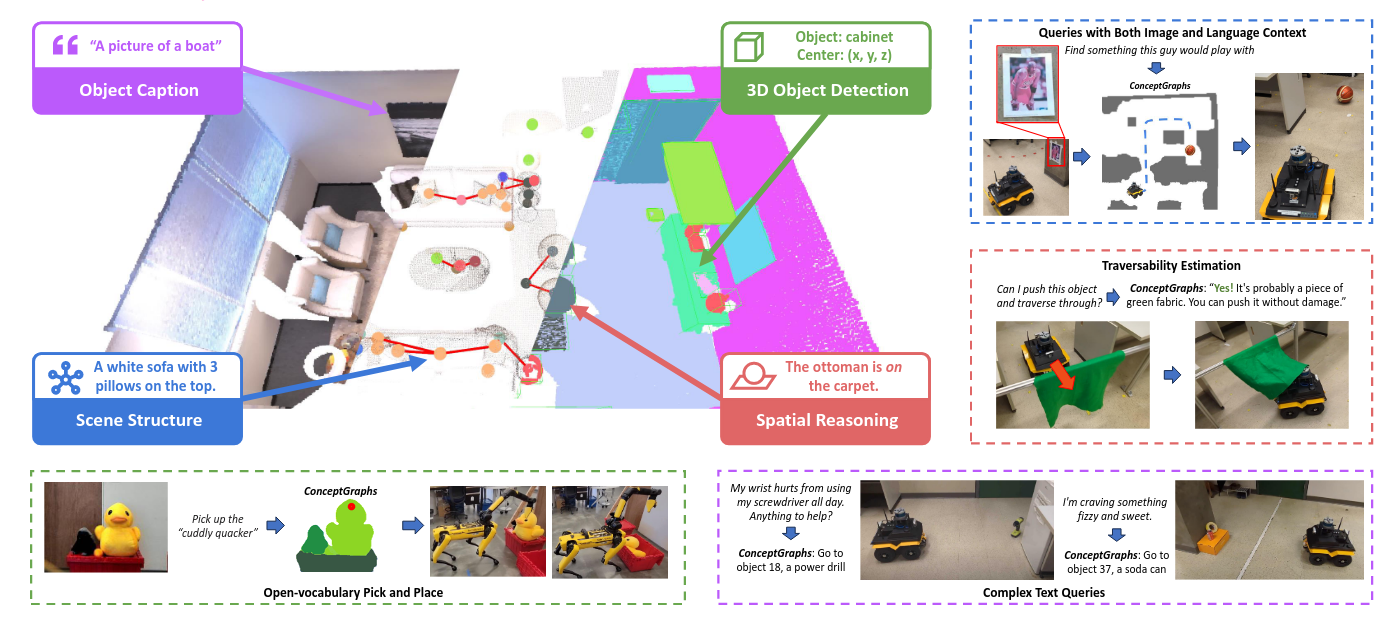
通过LLM来判断位置关系,以此构建scene graph

ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning
通过LLM来判断位置关系,以此构建scene graph
SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
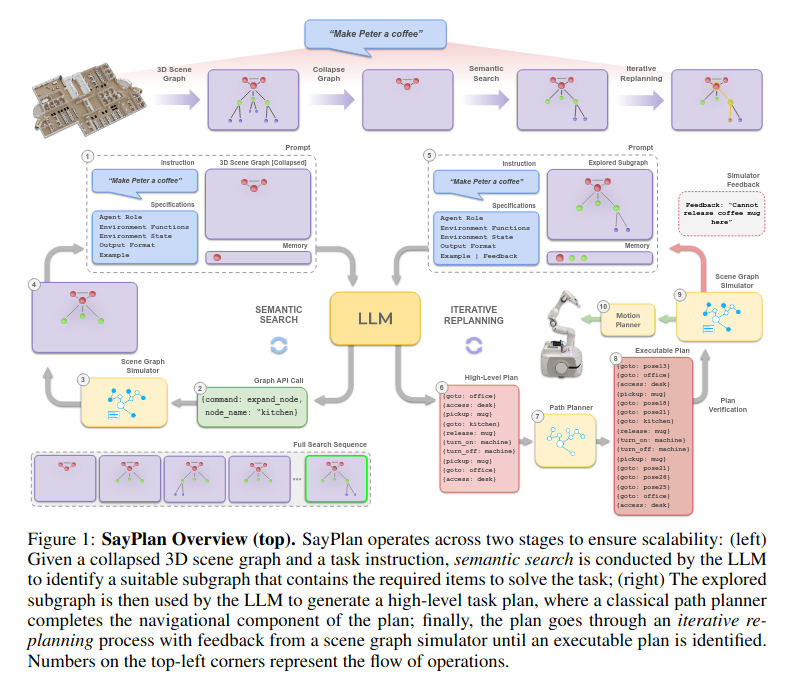
主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。

Representation Learning for Scene Graph Completion via Jointly Structural and Visual Embedding
 Representation Learning for Scene Graph Completion via Jointly Structural and Visual Embedding/Pasted_image_20250318162533.png)
The architecture of RLSV is a three-layered hierarchical projection that projects a visual triple onto the attribute space, the relation space, and the visual space in order.
Factorizable Net= An Efficient Subgraph-based Framework for Scene Graph Generation

我的想法是将场景进行panoptic segmentation 之后再在每个物体上进行hierarchical part relation detection,异曲同工。
RelTR= Relation Transformer for Scene Graph Generation
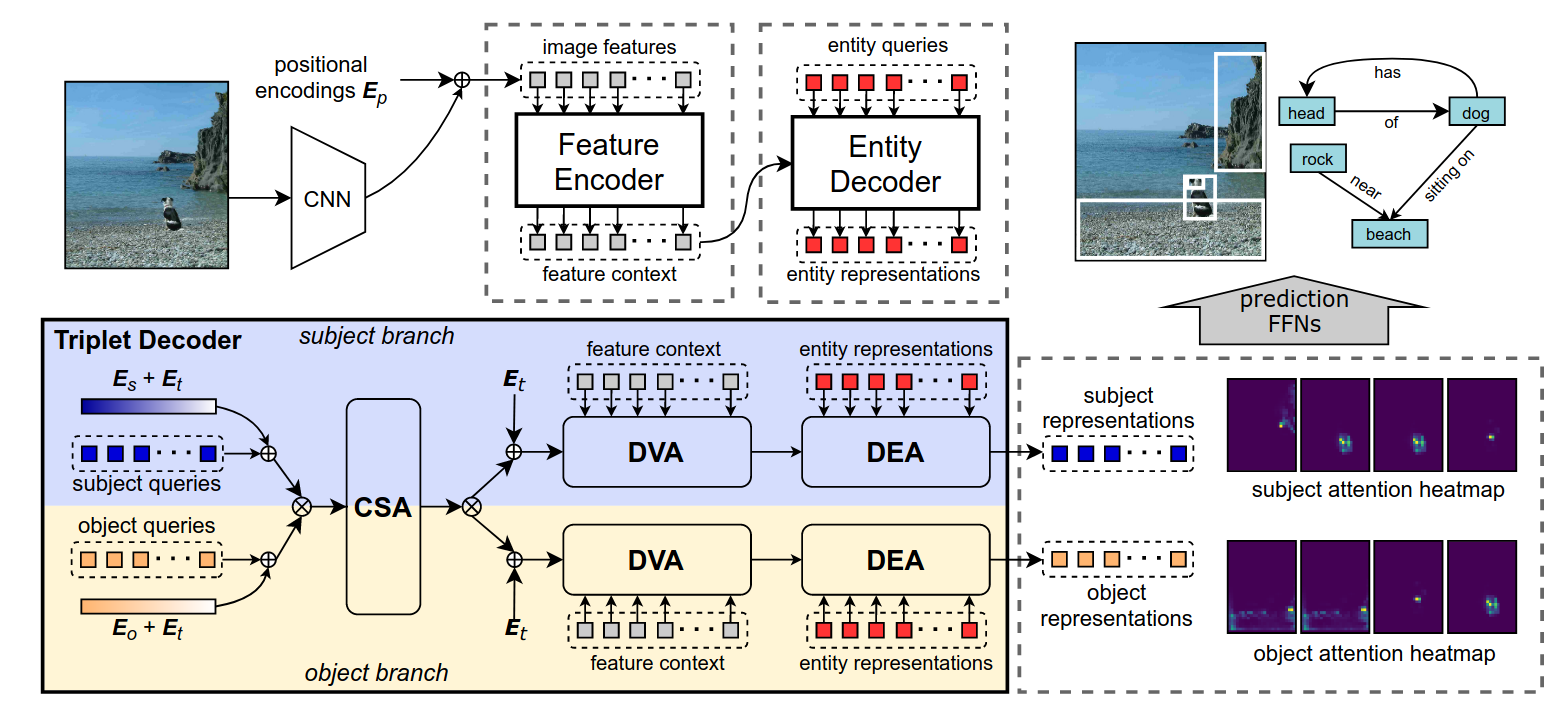
RelTR是自下而上的方法, 使用基于Transformer的 object detector(例如DETR)生成对象候选者,然后使用relation transformer来预测object pairs之间的关系。它还设计了一种基于积分的关系表示方法,该方法将关系编码为二维矢量场。
Fully Convolutional Scene Graph Generation
 Fully Convolutional Scene Graph Generation/Pasted_image_20250314123239.png)
这个模型受启发于 [[CenterNet]] 和 [[OpenPose Using Part Affinity Fields]],通过添加一个新的用于生成RAF的卷积头来获取物体之间的关系。

 Visual Translation Embedding Network for Visual Relation Detection/Pasted_image_20250318155431.png)