ChemGPT 早期基座模型基于 EleutherAI 的语言模型 GPT‑Neo,在分子字符串语料(SMILES 或 SELFIES)上进行自回归建模。
典型预训练数据集为公开的大规模分子库 PubChem10M,参数规模覆盖百万到十亿级别(如约 4.7M 的轻量版本或 100M+ 的科研版本)。
属于领域特化的 decoder-only 化学语言模型。

ChemGPT 早期基座模型基于 EleutherAI 的语言模型 GPT‑Neo,在分子字符串语料(SMILES 或 SELFIES)上进行自回归建模。
典型预训练数据集为公开的大规模分子库 PubChem10M,参数规模覆盖百万到十亿级别(如约 4.7M 的轻量版本或 100M+ 的科研版本)。
属于领域特化的 decoder-only 化学语言模型。

DREAM TO CONTROL= LEARNING BEHAVIORS BY LATENT IMAGINATION

论文使用**RSSM(Recurrent State Space Model)**:使用encoder来编码环境和动作生成latent state, 预测未来latent state,最后基于latent state预测奖励。
奠定世界模型= Intelligence without representation
目前学界广泛认为,世界模型是通往AGI的正确道路。而世界模型这一理念可以追溯到这篇1991年的文章。
1890 年代的人想造飞机,却只能根据他们零碎的观察去猜。他们看到现代飞机巨大、复杂,于是做了一个错误类比:
“现代飞机又大又重 → 所以重量不是问题。”
这当然荒唐。真正让飞机能飞的前提是升力、功率重量比、材料强度等关键工程指标的平衡。但他们只看到了表象,所以:
寓言中的团队觉得项目太大,所以分专业化研究,但他们犯了一个致命错误: 没有系统架构,没有统一指标,没有工程指导思想。
因此:
Brooks 的核心观点用一句话总结就是:
智能不是“建模世界 + 推理”的结果,而是“直接在世界中行动”的结果。世界本身就是模型,不需要额外的表征。
传统 AI(symbolic AI)强调:
Brooks 强烈反对。他认为:
这种思想后来直接催生了:

Feature Pyramid Networks for Object Detection
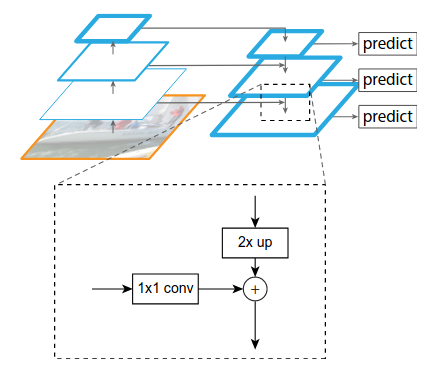
识别不同尺寸的物体是目标检测中的一个基本挑战,而特征金字塔一直是多尺度目标检测中的一个基本的组成部分,但是由于特征金字塔计算量大,会拖慢整个检测速度,所以大多数方法为了检测速度而尽可能的去避免使用特征金字塔,而是只使用高层的特征来进行预测。高层的特征虽然包含了丰富的语义信息,但是由于低分辨率,很难准确地保存物体的位置信息。与之相反,低层的特征虽然语义信息较少,但是由于分辨率高,就可以准确地包含物体位置信息。所以如果可以将低层的特征和高层的特征融合起来,就能得到一个识别和定位都准确的目标检测系统。所以本文就旨在设计出这样的一个结构来使得检测准确且快速。
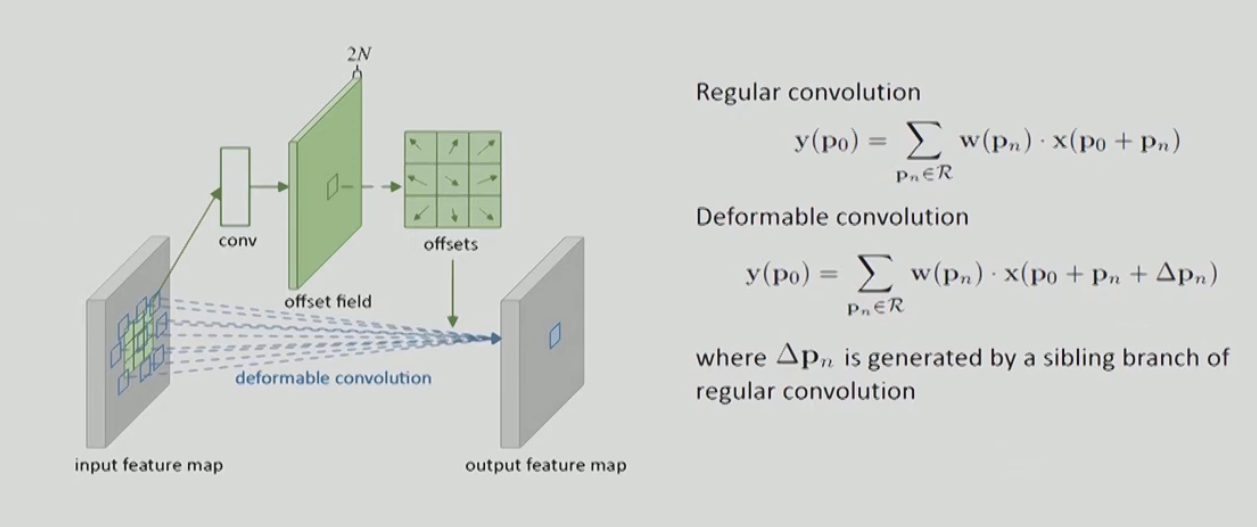
Deformable Convolutional Networks
Used in [[CenterNet]]
Associative Embedding= End-to-End Learning for Joint Detection and Grouping
What is standard dense supervised learning? Mentioned in [[CenterNet]].
Standard dense supervised learning typically refers to a supervised learning setup where:
In contrast to sparse supervision, where only a subset of the input (e.g., bounding boxes, keypoints) is labeled, dense supervision provides full annotations for every relevant part of the input.
Example
In semantic segmentation: