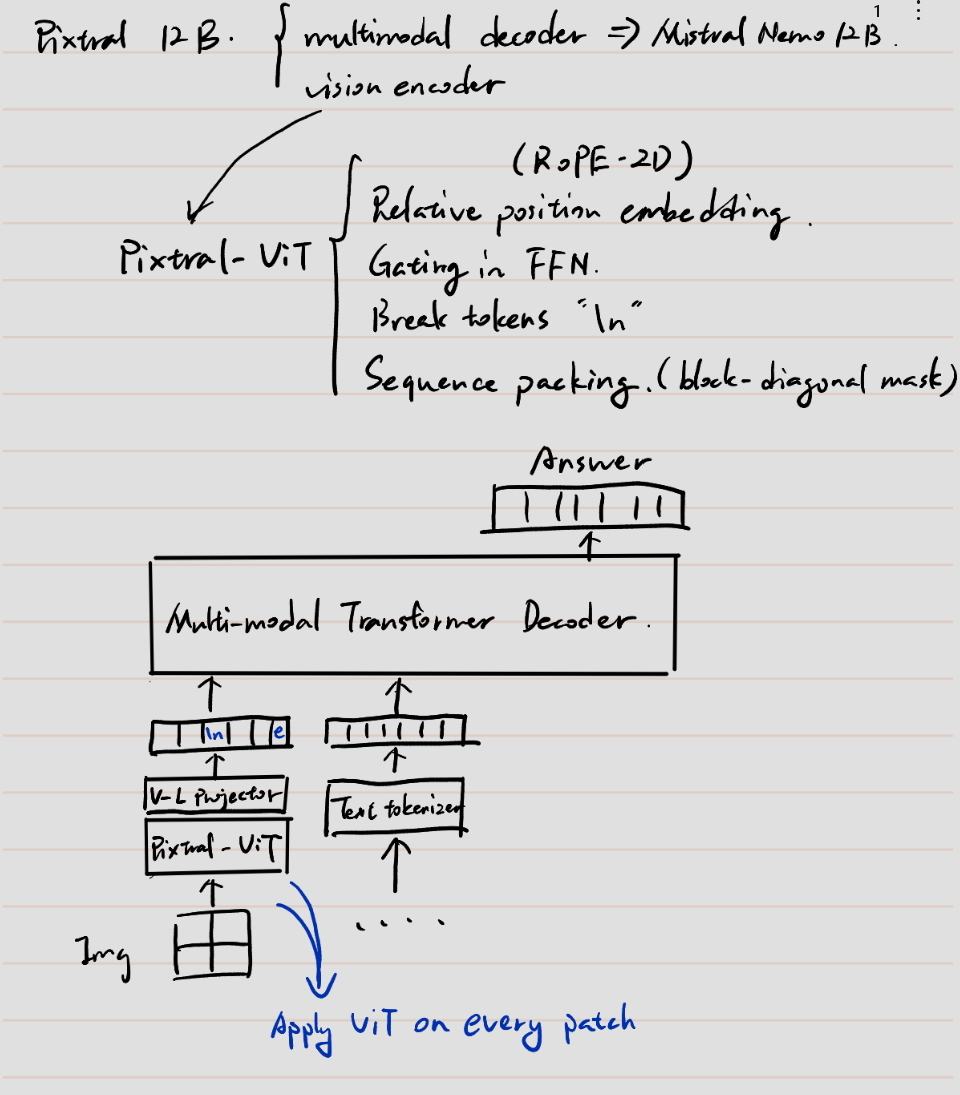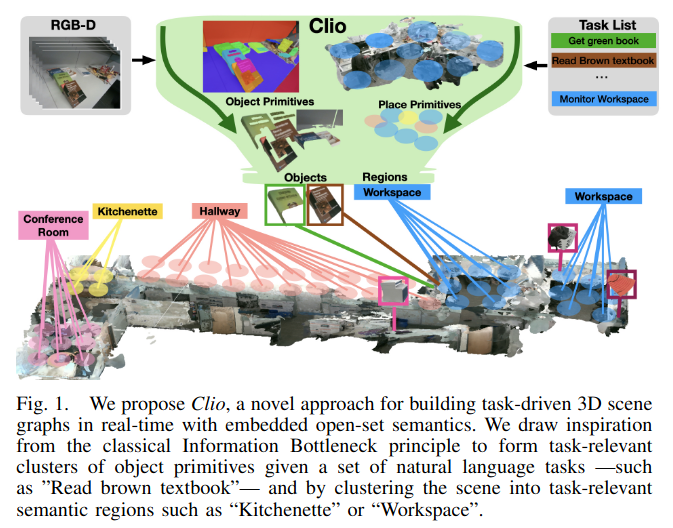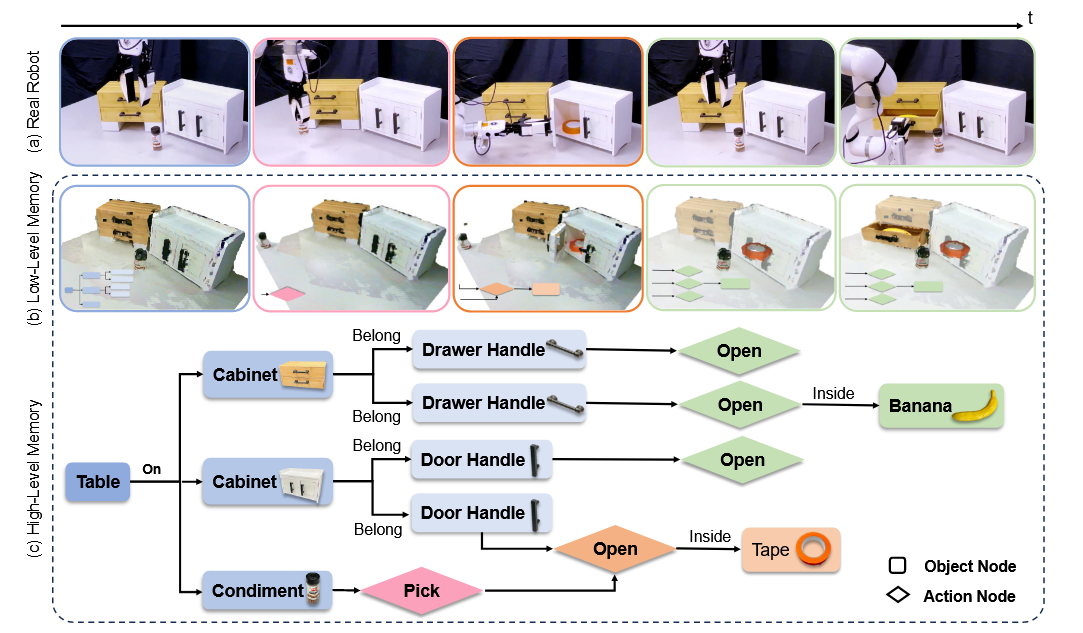

(Mindmap) Part-level Scene Understanding for Robots
 Part-level Scene Understanding for Robots/Pasted_image_20250414142333.png)
A scene graph is a structural representation, which can capture detailed semantics by explicitly Modeling:
三周年的post更多就是一种形式了,看了二周年的post, 感觉已经把我本人对于博客网的情感表达得较为详尽了,一年过去我并没有对此生发更多的感情了。看到自己在二周年的博客里提到了:
再往后就遇到了那个她,开始在博客上记录自己那股悸动的感觉,因为这种感觉不记录下来的话,就会溺死在往后的岁月里。当时真的从未想过我们会在一起,我感觉就是一个很特别的我喜欢的女孩子,她肯定有很多爱她的人并不渴求我的爱,毕竟牡丹这么多年了,这恋爱观念的惯性可不小。后来,她也看到了这篇博客,就这样,双向奔赴的我们以这种非常浪漫的方式在一起了。从此博客对我的意义,已经不再是可有可无了,是我的生活了。
不过很搞笑的是我写完那篇后过了20天我就失去了她,不过博客与我而言的意义依然没有太大变动,目前依然是我生活的一部分。
关于博客网本身确实每太多好生发的了,我还是主要写写这一年与博客有关的事情吧。
...
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
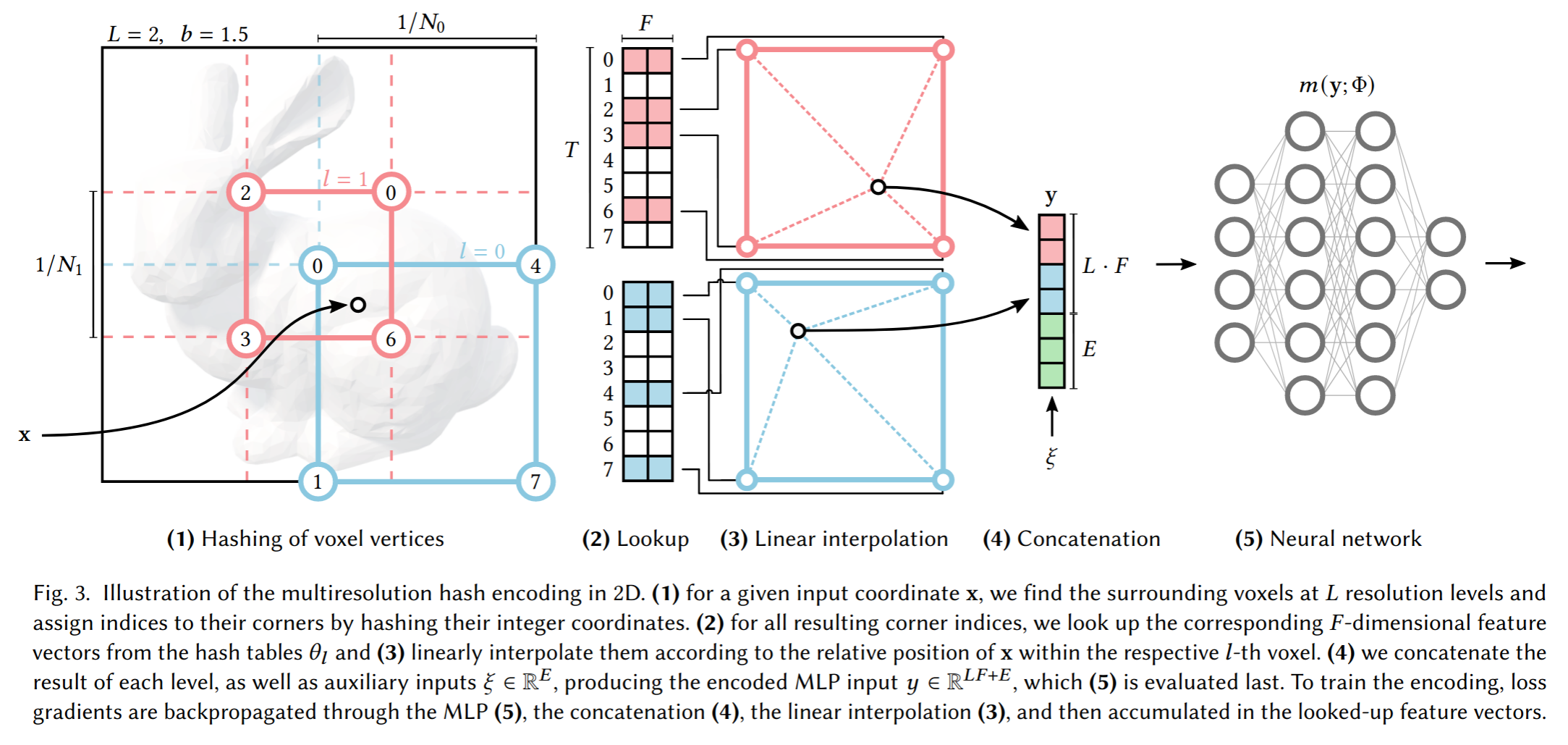
很重要的编码优化论文,MHE的概念:

ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning
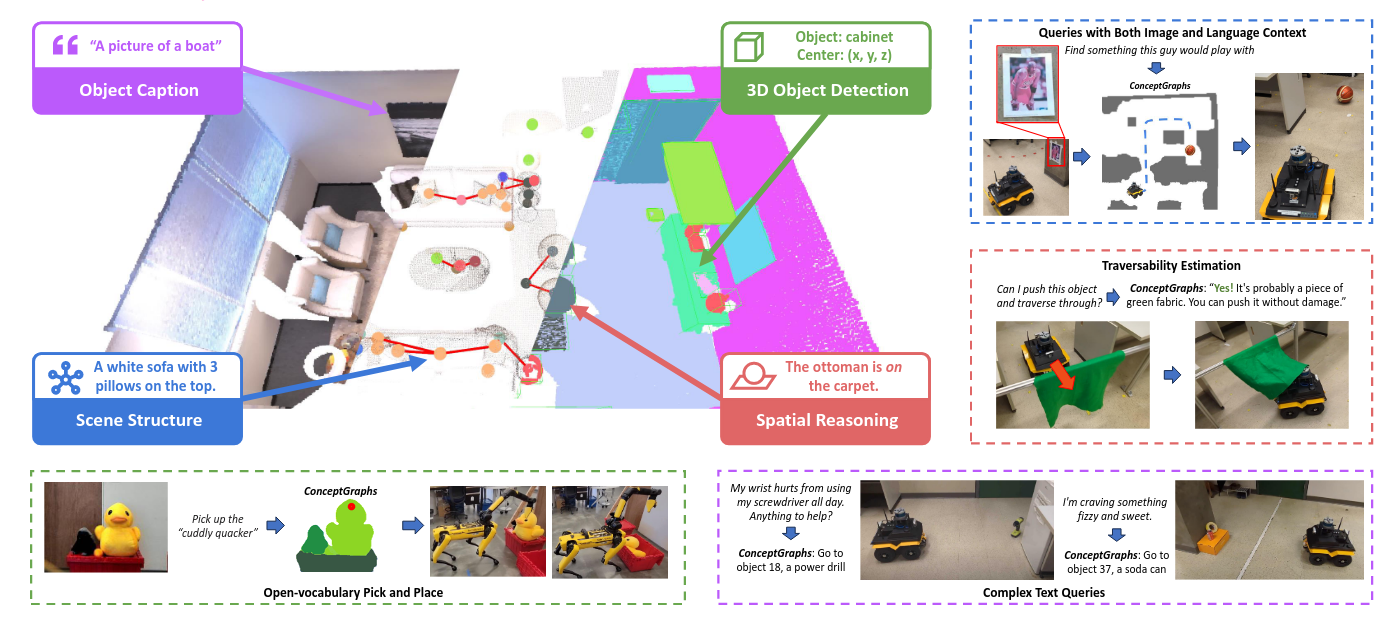
通过LLM来判断位置关系,以此构建scene graph
SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
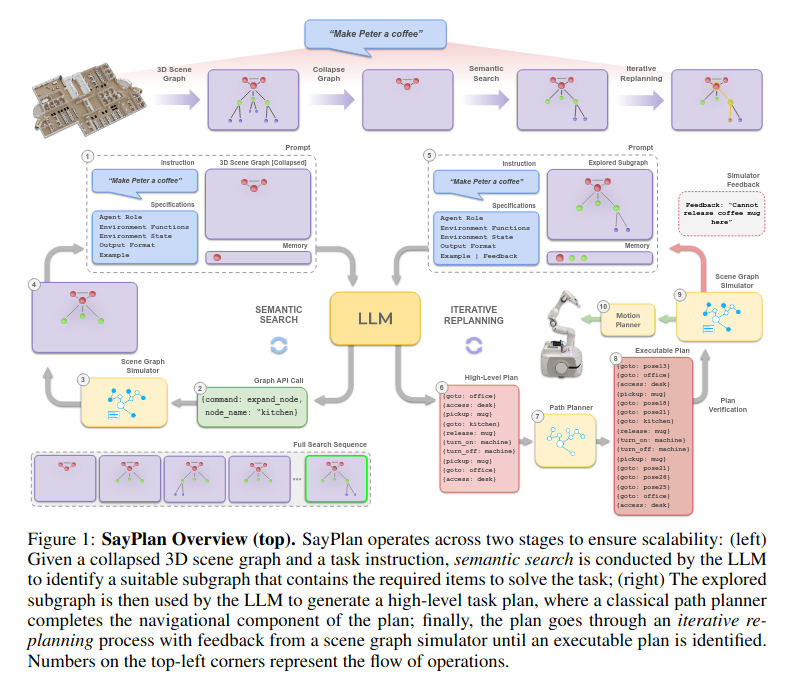
主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。