涉及的文章:
- 相近工作
- [[Part-level Scene Reconstruction Affords Robot Interaction]]
- [[Scene Reconstruction with Functional Objects for Robot Autonomy]]
- [[Reasoning with Scene Graphs for Robot Planning under Partial Observability]]
- [[ACDC- Automated Creation of Digital Cousins for Robust Policy Learning]]
- [[CLIP-Fields- Weakly Supervised Semantic Fields for Robotic Memory]]
- [[Factorizable Net= An Efficient Subgraph-based Framework for Scene Graph Generation]]
- [[SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning]]
- [[ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning]]
- 数据生成
- [[PHYSCENE- Physically Interactable 3D Scene Synthesis for Embodied AI]]
- 数据集
- 其他
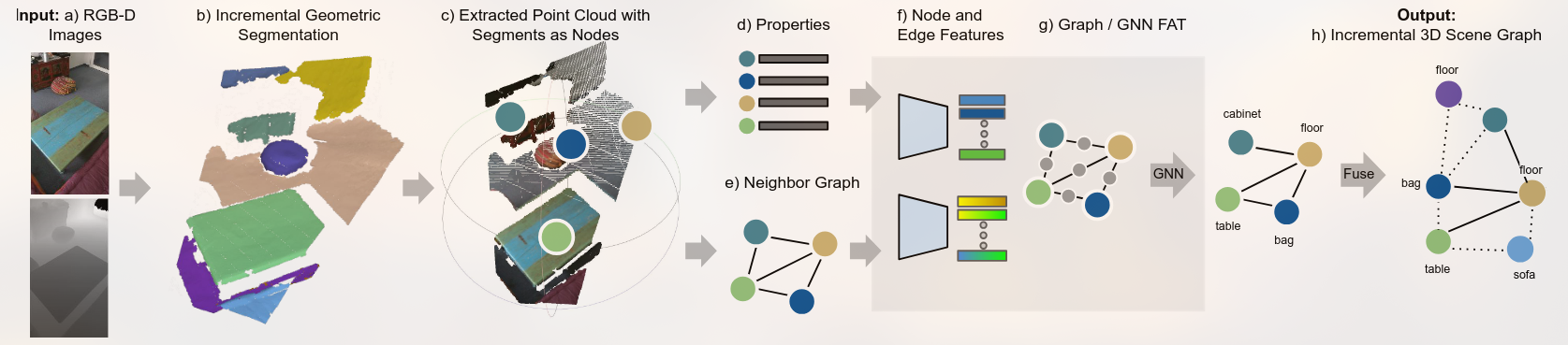
- [[SceneGraphFusion- Incremental 3D Scene Graph Prediction from RGB-D Sequences]]
- [[Visual Relationship Detection with Language Priors]]
- [[Image generation from scene graphs]]
- [[(FCSGG) Fully Convolutional Scene Graph Generation]]
- [[RelTR= Relation Transformer for Scene Graph Generation]]
- [[Scene Graph Generation by Iterative Message Passing]]
- [[From Pixels to Graphs= Open-Vocabulary Scene Graph Generation with Vision-Language Models]]
- [[(VtransE) Visual Translation Embedding Network for Visual Relation Detection]]
- [[(UVtransE) Contextual Translation Embedding for Visual Relationship Detection and Scene Graph Generation]]
- [[(RLSV) Representation Learning for Scene Graph Completion via Jointly Structural and Visual Embedding]]
- [[Energy-Based Learning for Scene Graph Generation]]
研究目标
通过构建part-level scene-graph,结合Reasoning with LLM 让机器人能够实现更复杂的交互,并以此完成更复杂的任务。
Scene Graph Introduction
Background
Visual scene understanding长期以来一直被认为是计算机视觉的圣杯
Rapid scene understanding at all levels
Generally
Visual scene understanding 可以被分为两块任务
recognition task
- image level
- image classification
- [[DINO]]
- [[CLIP多模态预训练模型]]
- pixel level
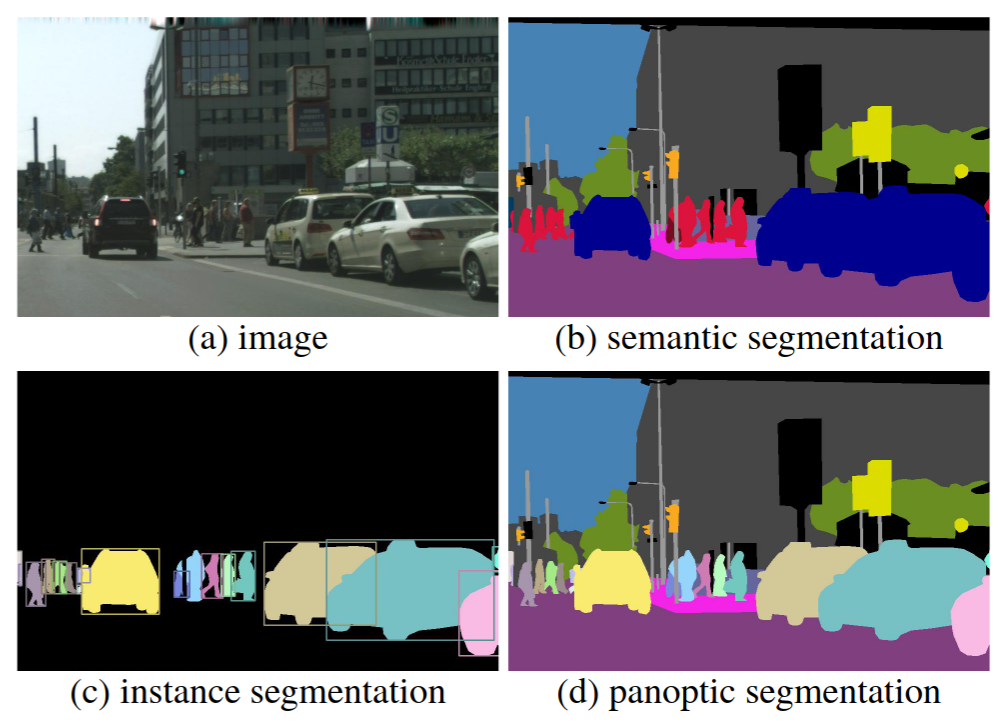
- semantic segmentation: classify each pixel in an image into a category
- instance level
- instance segmentation: detect and delineate each individual object instance in an image (bounding boxes or segmentation masks)
- [[Grounding-DINO]]
- [[Gounded-SAM]]
- pixel & instance level
- [[Panoptic Segmentation]]: takes into account both per-pixel class and instance labels
- [[MaskDINO]]
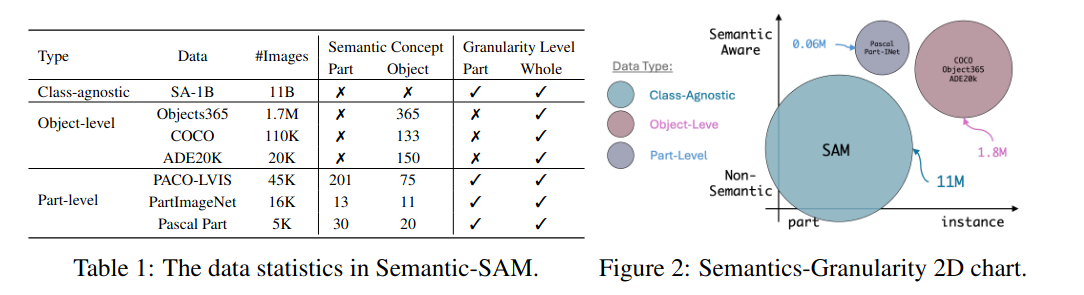
- [[Semantic-SAM]]
application task
Relation & Interaction
但是以上这些Generally的工作注重的都是the localization of objects,更高级别的任务强调探索对象之间的丰富语义关系,以及对象与周围环境的相互作用
- 视觉关系检测(VRD)
- [[GPS-Net= Graph Property Sensing Network for Scene Graph Generation]]
- [[Large-scale visual relationship understanding]]
- 人类对象相互作用(HOI)
CV & NLP
除此之外还有将NLP和CV结合起来的方向,主要是一些VLM
- image caption
- visual question answering
- visual dialog
Structured Representation of Scene (Scene Graph)
对于总体场景的感知和信息的有效表示仍然是瓶颈。
所以Li Feifei 在[[Image Retrieval using Scene Graphs]]提出Scene Graph
与Structured Representation相对的是Latent Representation
Scene Graph Definition
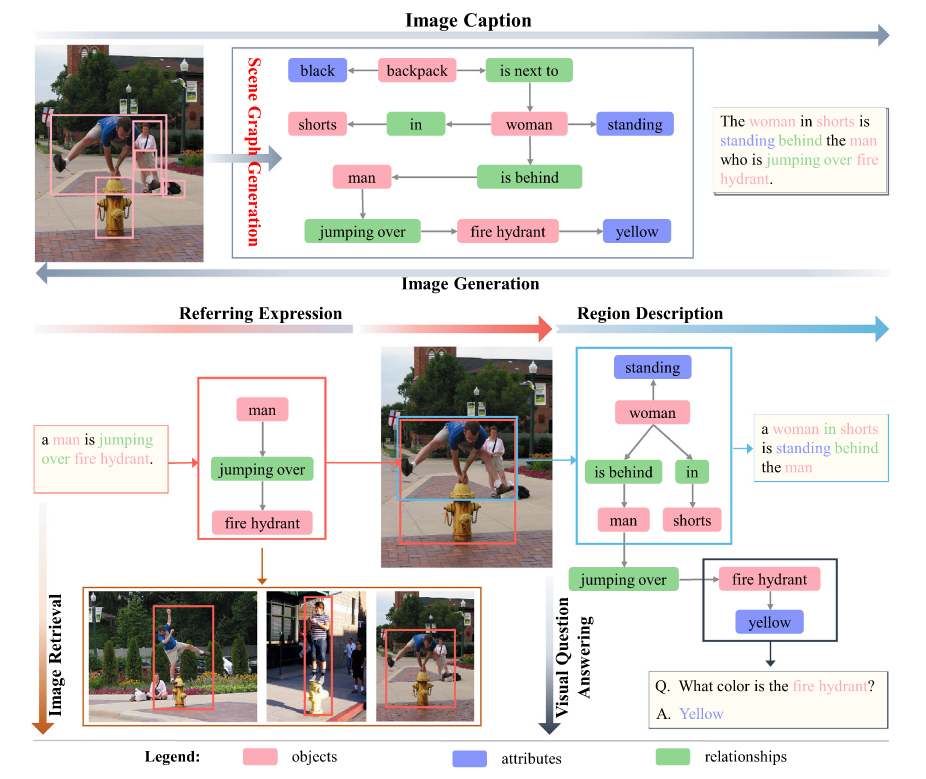
A scene graph is a structural representation, which can capture detailed semantics by explicitly Modeling
- objects (‘‘man’’, ‘‘fire hydrant’’, ‘‘shorts’’)
- attributes of objects (‘‘fire hydrant is yellow’’)
- relations between paired objects (‘‘man jumping over fire hydrant’’)
A scene graph is a set of visual relationship triplets in the form of <subject, relation, object> or <object, is, attribute>
Scene graphs should serve as an objective semantic representation of the state of the scene
为什么选择scene graph
Scene Graph具有应对和改善其他视觉任务的内在潜力。
可以解决的视觉任务包括:
- Image captioning
- take an image as an input and parse it into a scene graph, and then generate a reasonable text as output.
- Visual question answering
- Content-based image retrieval
- Image generation
- extracting scene graphs from the text description and then generate realistic images
- [[Image generation from scene graphs]]
- referring expression comprehension
Scene Graph Generation
场景图生成的目的是解析图像或一系列图像,并且生成结构化表示,以此弥合视觉和语义感知之间的差距,并最终达到对视觉场景的完整理解。
任务的本质是检测视觉关系。
先驱工作
早先由Feifei [[Visual Relationship Detection with Language Priors]] 提出了视觉关系检测的方法。
以及Visual Genome这个包含物体关系的数据集
生成方法
Two-stage
Detects objects first and then solves a classification task to determine the relationship between each pair of objects
**General:**
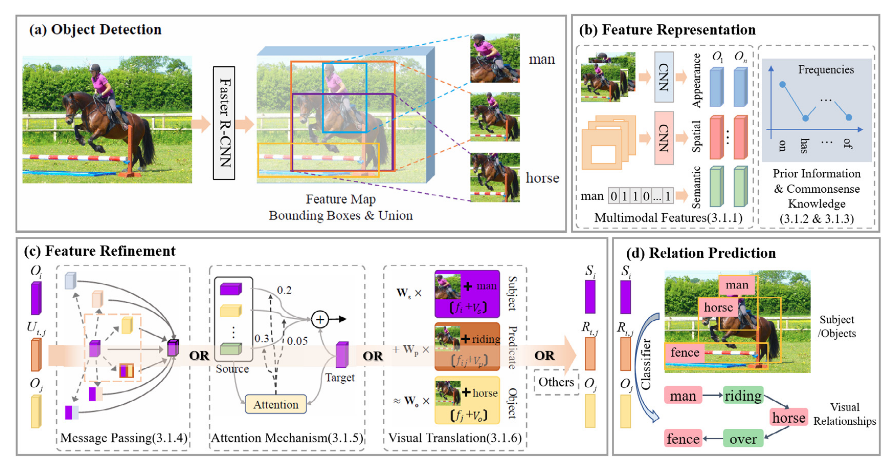
a) 通过图片获取 subject/object and union box proposals (ROI感兴趣区域)
b) 提取每个区域的特征。包括object的appearance, spatial information, label, depth, and mask;predicate的appearance, spatial, depth, and mask。
c) 这些多模态特征被 vectorized, combined, and refined。可以通过:
- message passing mechanisms
- [[Scene Graph Generation by Iterative Message Passing]]
- attention mechanisms
- visual translation embedding
d) 分类器用于预测predicate的类别
基于Visual translation embedding的
- Translation between Subject and Object (subject+predicate ≈ object)
- [[(VtransE) Visual Translation Embedding Network for Visual Relation Detection]]
- Translation among Subject, Object and Predicate
- [[(UVtransE) Contextual Translation Embedding for Visual Relationship Detection and Scene Graph Generation]]
- [[(RLSV) Representation Learning for Scene Graph Completion via Jointly Structural and Visual Embedding]]
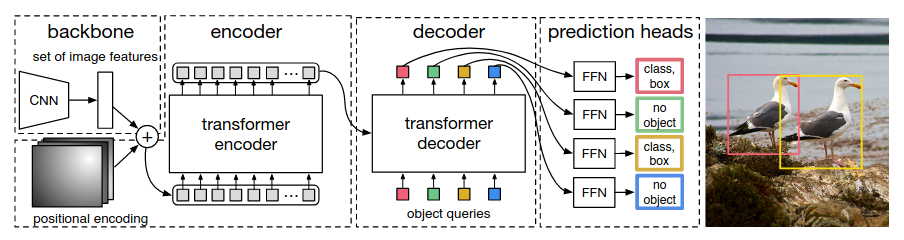
One-stage!!!
Simultaneously detects and recognizes objects and relations
相较于two-stage:
- 需要更少的计算资源和参数
- 不会受到object detection的质量影响
Example:
- [[(FCSGG) Fully Convolutional Scene Graph Generation]] (bottom-up + RAF)
- [[RelTR= Relation Transformer for Scene Graph Generation]] (bottom-up)
- [[SGTR= End-to-end Scene Graph Generation with Transformer]] (top-down)
Open-Vocabulary
基本都是基于LLM或者VLM之类的大模型
- [[From Pixels to Graphs= Open-Vocabulary Scene Graph Generation with Vision-Language Models]]
- [[ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning]]
Scene Graph小结
这里所有的工作都是关于如何判断两个独立物体之间的谓语关系(例如riding, holding…),并没有涉及part-level relationship的工作。part-level的父子关系和object-level的谓语关系是很不一样的。
不基于Scene Graph 的场景理解方法
隐式场景
即场景信息存储在一个神经网络中,并没有显式的结构,规划器(可以是LLM)通过query这个模型来获得信息。
- [[CLIP-Fields- Weakly Supervised Semantic Fields for Robotic Memory]]
数字表亲场景
核心思想是用交互更丰富的模型组合成可交互的替代场景。
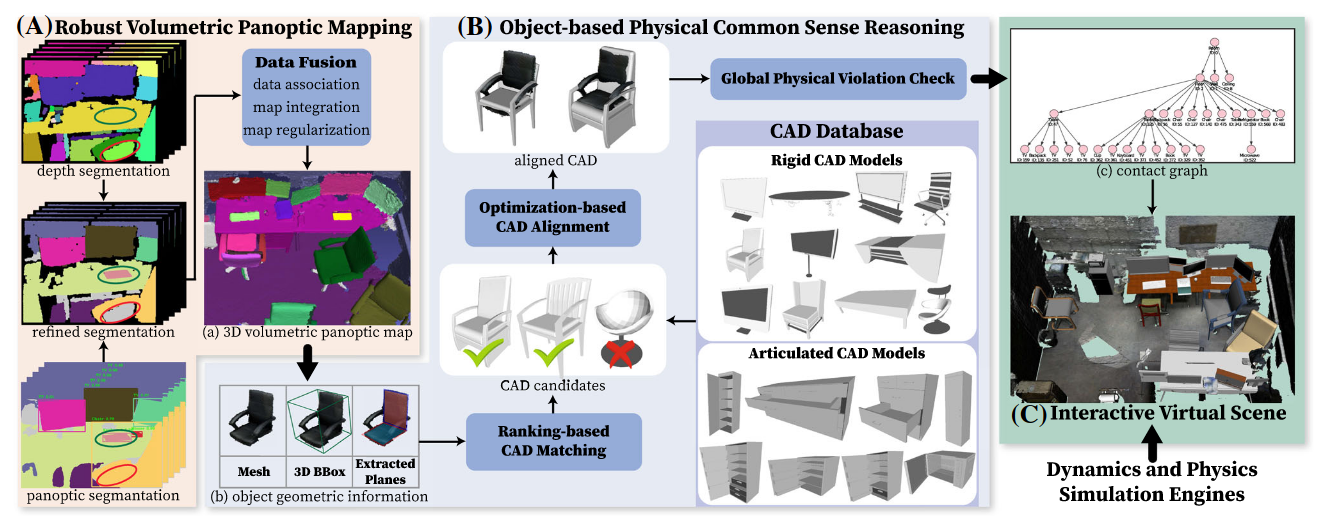
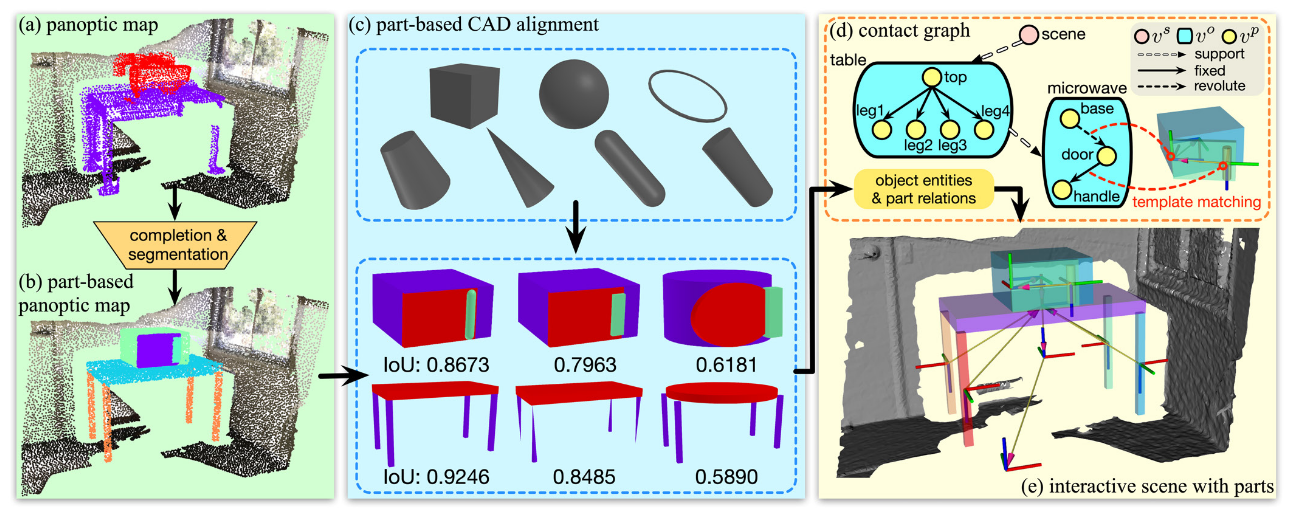
- [[Scene Reconstruction with Functional Objects for Robot Autonomy]]
- [[ACDC- Automated Creation of Digital Cousins for Robust Policy Learning]]
- 通既有的精细模型库来拟合场景中的物体,可以实现更丰富的交互,对家常物品zero-shot,但是精度有限,不能应对复杂物体
主要用于建模物体之间的运动学关系
- [[Scene Reconstruction with Functional Objects for Robot Autonomy]]
- [[Part-level Scene Reconstruction Affords Robot Interaction]]
Scene Graph & Robots
将 scene graph 用于机器人任务理解和规划
- [[SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning]]
- [[Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation]]
- [[ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning]]