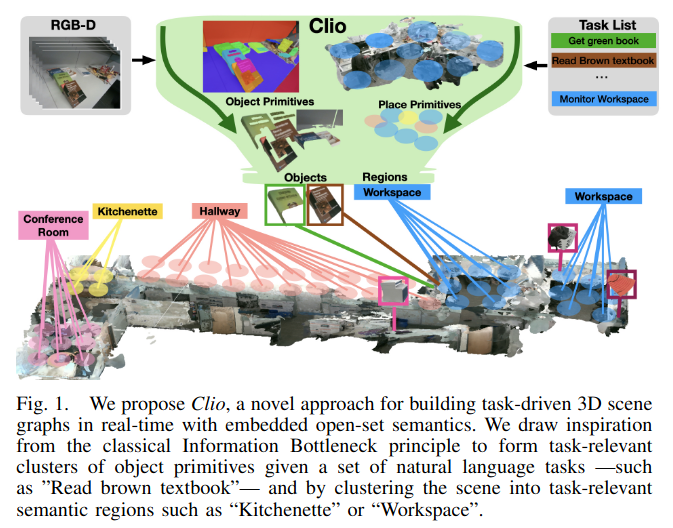

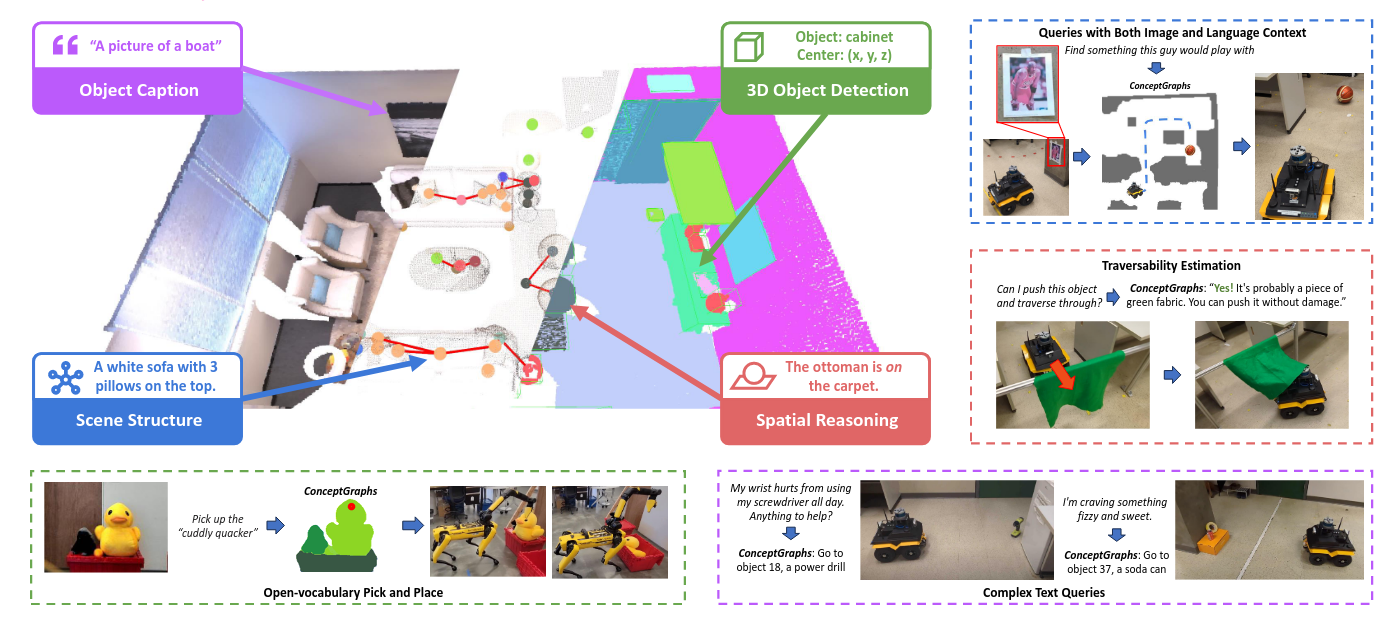
ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning
通过LLM来判断位置关系,以此构建scene graph
SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
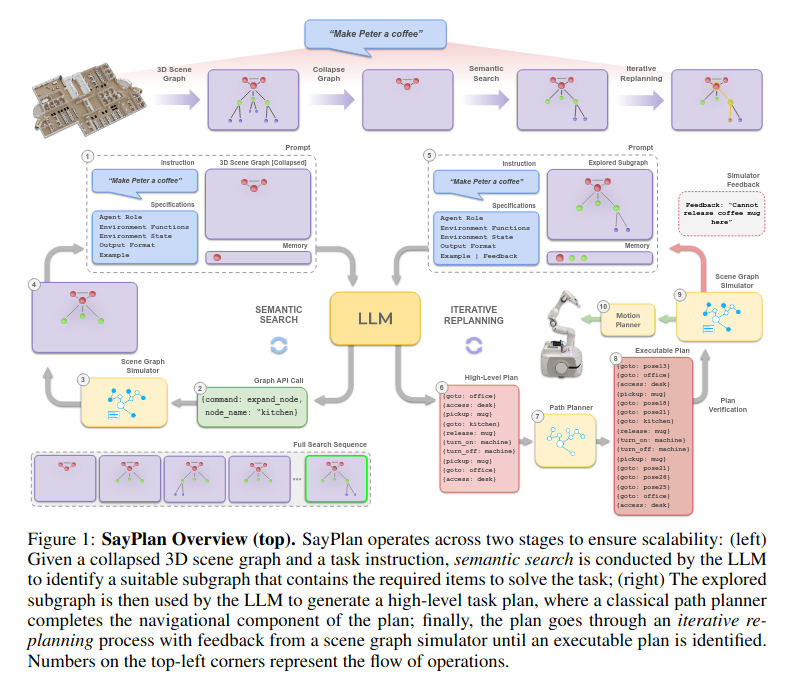
主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。

SceneGraphFusion- Incremental 3D Scene Graph Predictionfrom RGB-D Sequences
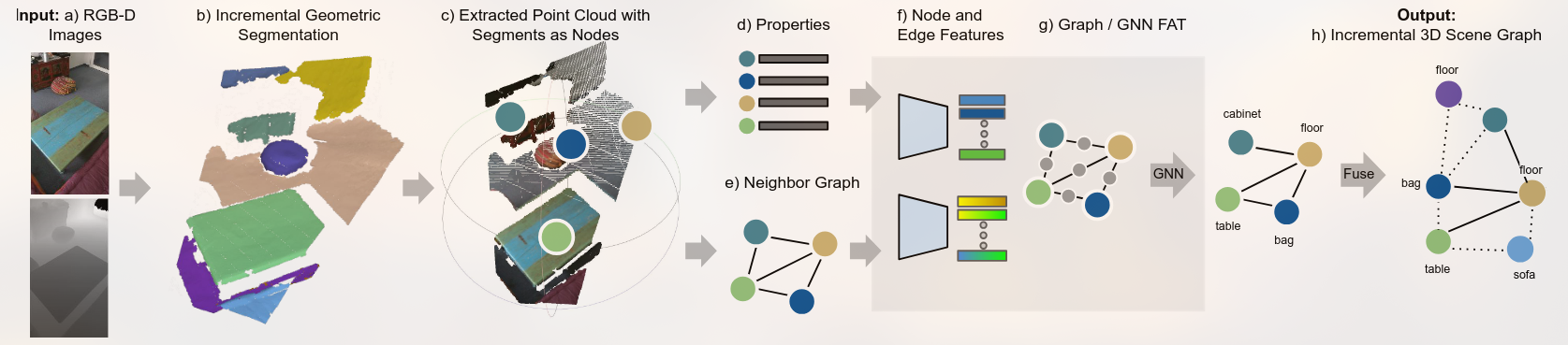
Overview of the proposed SceneGraphFusion framework. Our method takes a stream of RGB-D images a) as input to create an incremental geometric segmentation b). Then, the properties of each segment and a neighbor graph between segments are constructed. The properties d) and neighbor graph e) of the segments that have been updated in the current frame c) are used as the inputs to compute node and edge features f) and to predict a 3D scene graph g). Finally, the predictions are h) fused back into a globally consistent 3D graph.
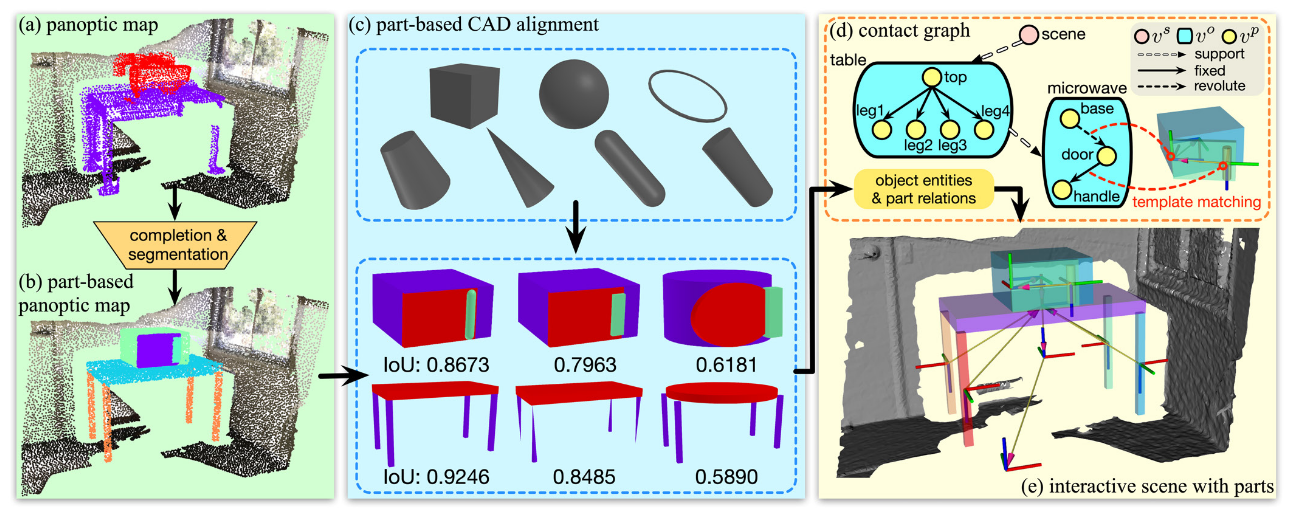
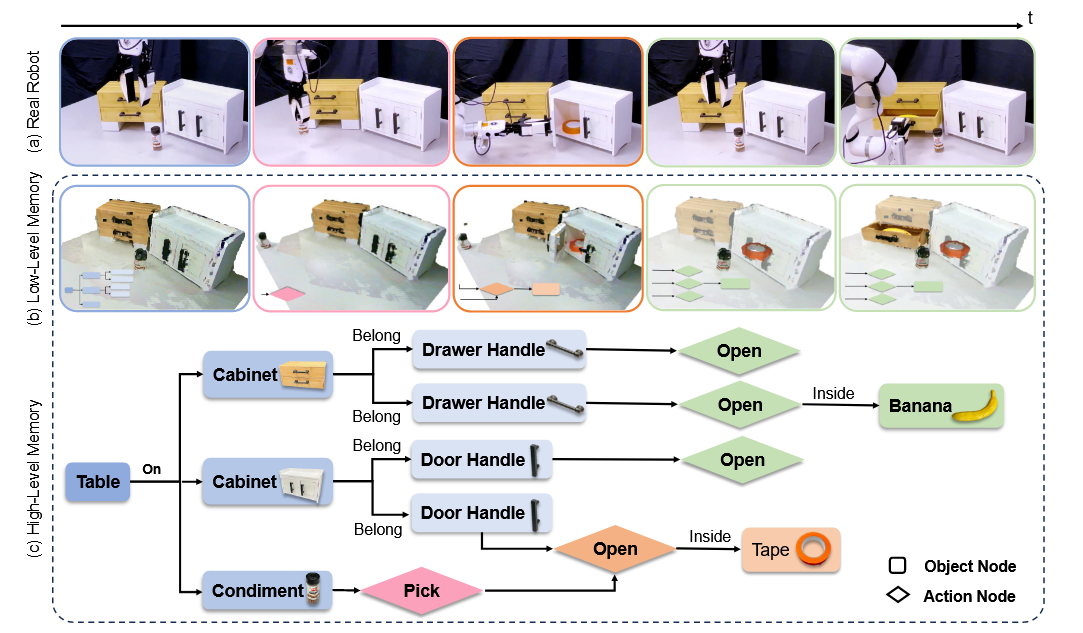
Scene Reconstruction with Functional Objects for Robot Autonomy
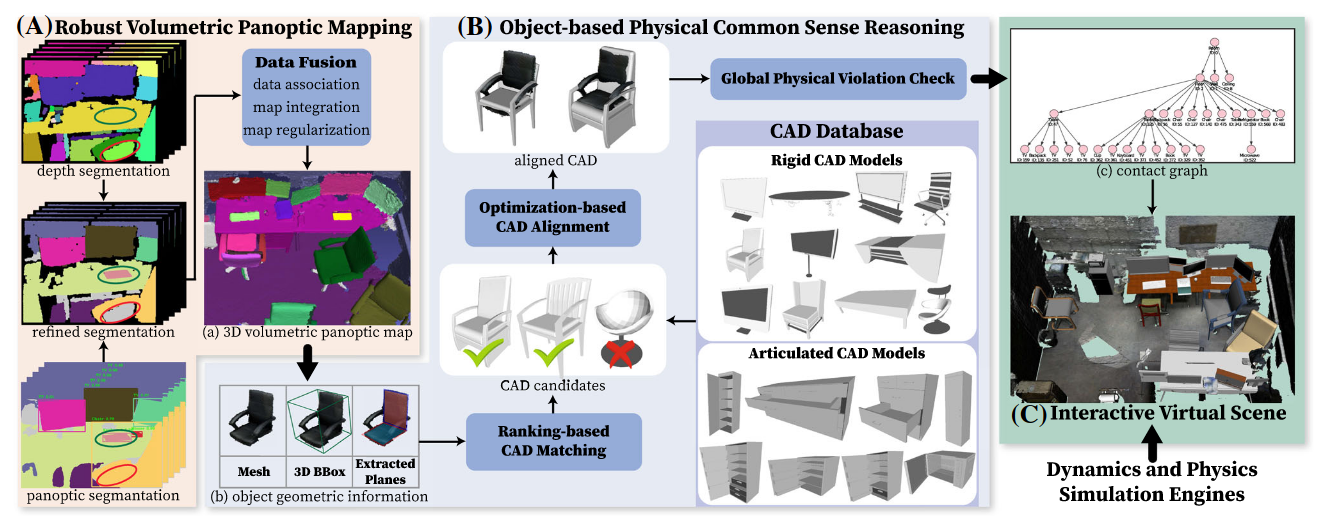
和李飞飞[[ACDC- Automated Creation of Digital Cousins for Robust Policy Learning]]的思想类似。

将不同帧$X_t$中的特征集合在M中特征点的公式: