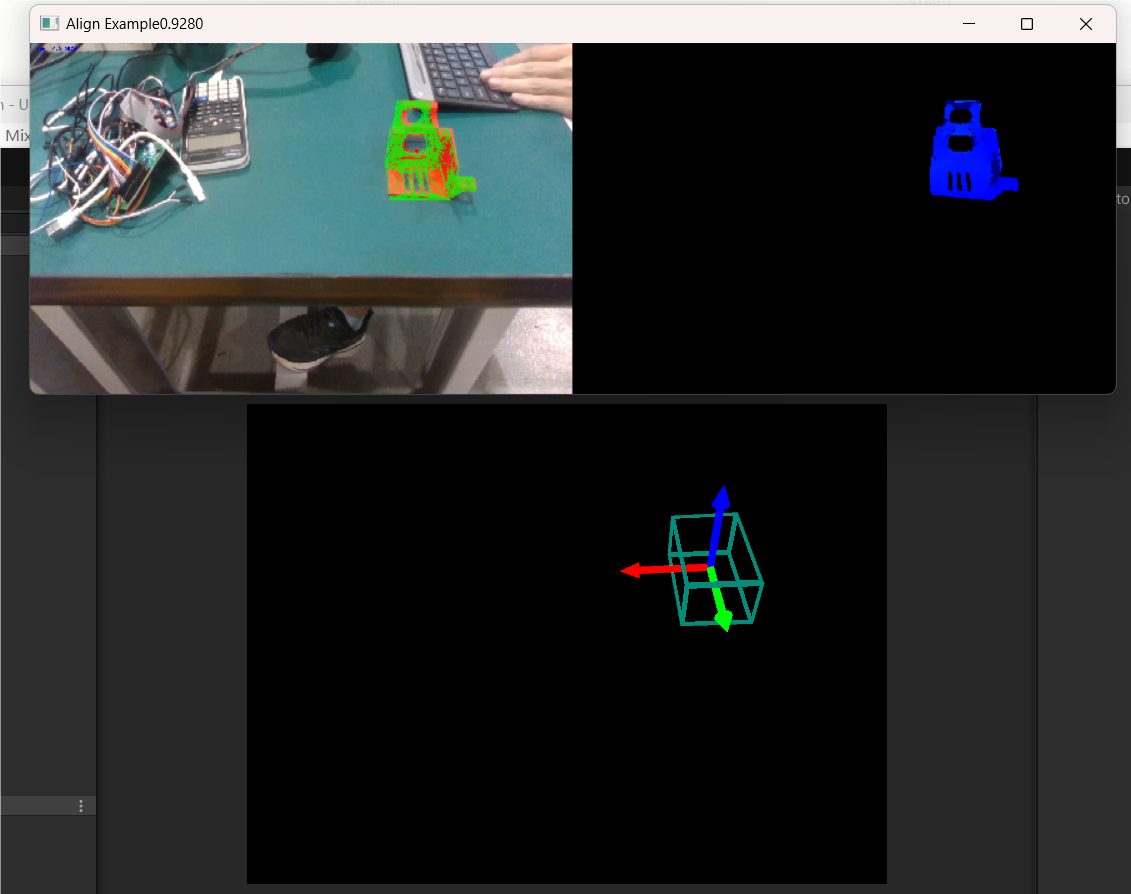
Setup
仓库: https://github.com/Simple-Robotics/cosypose
1 | git clone --recurse-submodules https://github.com/Simple-Robotics/cosypose.git |
注意执行这一步的时候pip 会提示setuptools 和matplotlib-inline不符合3.7.6的python,到环境中手动安装适配的版本
1 | conda activate cosypose |
1 | git lfs pull |
根据README下载数据
注意第一块指令无法下载成功,由 https://bop.felk.cvut.cz/datasets/ 得知下载链接迁移到了huggingface, https://huggingface.co/datasets/bop-benchmark/datasets/tree/main/ycbv 可以从这里手动下载测试集并放置到local_data/bop_datasets/ycbv/test
设置测试使用的models
1 | cp ./local_data/bop_datasets/ycbv/model_bop_compat_eval ./local_data/bop_datasets/ycbv/models |
Debug
np.where(mask)[0].item()
运行
1 | export CUDA_VISIBLE_DEVICES=0 |
时出现报错
1 | Traceback (most recent call last): |
添加debug输出,得到
1 | Debug - scene_id: 48, view_id: 1 |
发现是下载的测试数据集并不包含数据集keyframe.txt中所有的帧,导致一些关键帧识别不到
运行到一半被终止的情况
如果想重新开始新的训练: 清空local_data/joblib_cache
Framework
Prediction Script cosypose.scripts.run_cosypose_eval
AI explanation
The script predicts object poses based on multi-view input by following these steps:
Dataset Loading: It first loads the dataset using the
make_scene_datasetfunction, which prepares the scene data for evaluation. The dataset is wrapped in aMultiViewWrapperto handle multiple views.Model Loading: The script loads pre-trained models for pose prediction using the
load_modelsfunction. It loads both coarse and refiner models based on the configuration specified in the command-line arguments.Prediction Setup: The script sets up the prediction parameters, including the number of iterations for coarse and refiner models, and whether to skip multi-view processing based on the number of views specified.
Multi-view Prediction: The
MultiviewScenePredictoris initialized with the mesh database, which is used to predict poses across multiple views. TheMultiviewPredictionRunneris then used to run predictions on the dataset, leveraging the multi-view setup to improve pose estimation accuracy.Pose Estimation: The script uses the loaded models to predict object poses. It processes detections from either
pix2poseorposecnndepending on the dataset, and refines these predictions using the refiner model.Evaluation: After predictions, the script evaluates the predicted poses using the
PoseEvaluationclass. It calculates various metrics like ADD-S and AUC to assess the accuracy of the pose predictions.Results Logging: Finally, the script logs the results, including evaluation metrics, and saves them to a specified directory.
The multi-view approach allows the script to leverage information from different viewpoints, which can help resolve ambiguities and improve the robustness of the pose estimation.
Prediction Script run_custom_scenario
Terms
TCO
Transformation from Camera to Object.
It represents the transformation matrix or parameters that describe the pose of an object relative to the camera’s coordinate system
TWO
Transformation from World to Object.
It represents the transformation matrix or parameters that describe the pose of an object relative to the world’s coordinate system
Model dataset
1 | class MeshDataBase: |
一般使用的初始化方式:
1 | object_ds = BOPObjectDataset(scenario_dir / 'models') |
也可以通过load models一起加载:
1 | predictor, mesh_db = load_models(coarse_run_id, refiner_run_id, n_workers=n_plotters, object_set=object_set) |
Important Classes
Multiview_wrapper
作用:
读取 scene_dataset 并且通过视角数量n_views来分割这些数据为不同场景,然后方便遍历其中的场景元素(这里都是ground truth)
遍历时返回的值为
n_views张不同视角下的RGB图像n_views张对应的maskn_views份对应的observation- 识别到的物体位姿和类型
- 相机位姿和内参
- frame_info,没太多用
1
2scene_ds_pred = MultiViewWrapper(scene_ds, n_views=n_views)
scene_ds_pred[0][2] # scene48 multiview_group1 's observations in five views
1 | [ |
MultiviewPredictorRunner
作用:
接收Multiview_wrapper作为输入,并做出预测
首先是数据集接收:
1 | dataloader = DataLoader(scene_ds, batch_size=batch_size, |
use collate_fn to process the row data (最后的注释里面有真正用到的数据)
1 | def collate_fn(self, batch): |
最重要的function: get_predictions
1 | def get_predictions(self, pose_predictor, mv_predictor, |
Responsible for generating predictions for object poses in a scene using both single-view and multi-view approaches.
Input Parameters:
pose_predictor: single view predictor,比如ycbv数据集用的就是posecnn的检测模型mv_predictor: An object or function that predicts scene states using multi-view information.detections: A collection of detected objects with associated information, pre-generated and saved in a .pkl filen_coarse_iterations,n_refiner_iterations: Number of iterations for coarse and refinement pose estimation.sv_score_th: Score threshold for single-view detections.skip_mv: A flag to skip multi-view predictions.use_detections_TCO: A flag to use detections for initial pose estimation.
Filtering Detections:
需要注意的是这里使用的detection是直接来自预存好的检测数据(非ground truth)1
posecnn_detections = load_posecnn_results()
- The function filters the input
detectionsbased on thesv_score_ththreshold. - It assigns a unique detection ID to each detection and creates an index based on
scene_idandview_id.
- The function filters the input
Iterating Over Data:
- The function iterates over batches of data from the
dataloader. - For each batch, it extracts images, camera information, and ground truth detections.
- The function iterates over batches of data from the
Matching Detections:
- It matches the detections with the current batch of data using the index created earlier.
- It filters and prepares the detections for processing.
Pose Prediction:
- If there are detections, it uses the
pose_predictorto get single-view predictions. - It registers the initial bounding boxes with the candidates.
- If there are detections, it uses the
Multi-View Prediction:
- If
skip_mvisFalse, it uses themv_predictorto predict the scene state using multi-view information.
- If
Collecting Predictions:
- It collects the single-view and multi-view predictions into a dictionary.
Concatenating Results:
- It concatenates the predictions across all batches and returns the final predictions.
MultiviewScenePredictor
作用:
used by Myltiview_PredictionRunner.get_predictions
In run_cosypose_eval we initialize MultiviewScenePredictor in this way:
1 | mv_predictor = MultiviewScenePredictor(mesh_db) |
In the MultiviewScenePredictor we use the mesh_db to initialize MultiviewRefinement and solve:
1 | problem = MultiviewRefinement(candidates=candidates_n, |
The solve function of MultiviewRefinement:
1 | def solve(self, sample_n_init=1, **lm_kwargs): |
Adaption
准备基于run_custom_scenario进行修改run_custom_scenario的使用方式:
1 | python -m cosypose.scripts.run_custom_scenario --scenario=example |
1 | Setting OMP and MKL num threads to 1. |
该脚本只接收了candidates, mesh_db和camera_k信息,直接运行mv_predictor
写一个通过list输入构建candidates的function:
1 | def read_list_candidates_cameras(self, data_list, cameras_K_list): |
1 | # Example usage: |
1 | (PandasTensorCollection( |
之后就正常调用MultiviewScenePredictor.predict_scene_state() to estimate the scene:
1 | predictions = self.mv_predictor.predict_scene_state(candidates, cameras, |
之后再使用Non-Maximum Suppression来聚合重复检出的物体
1 | objects = predictions['scene/objects'] |
最终输出objects_
1 | PandasTensorCollection( |
Usage
Please refer to the notebook custom_scene.ipynb.