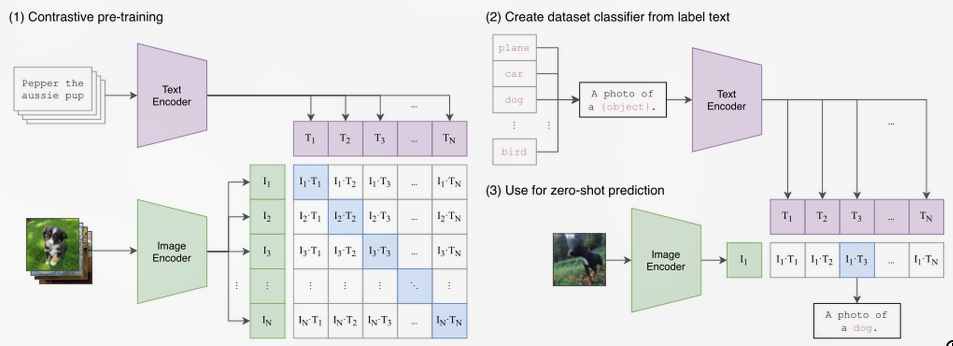
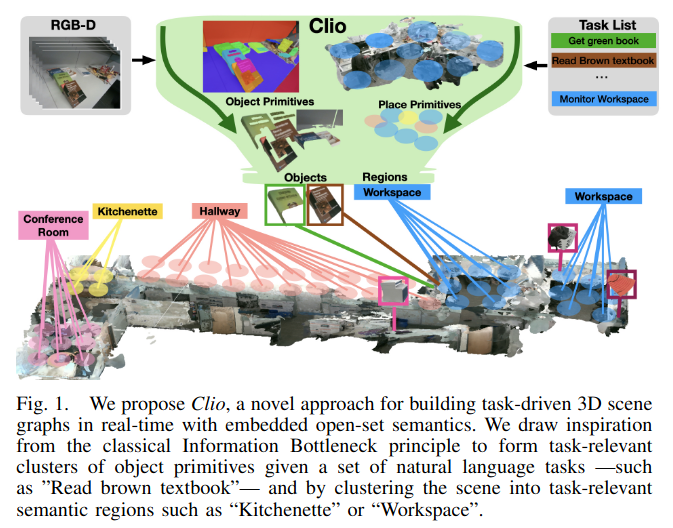
Clio= Real-time Task-Driven Open-Set 3D Scene Graphs
贡献:


A vision-language model that unifies vision-language understanding and generation tasks.
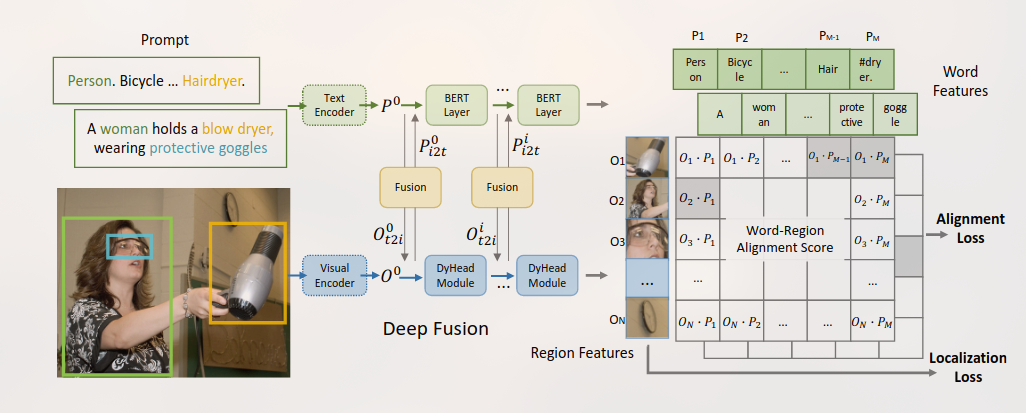
GLIP是一个学习了object-level, language-aware, and semantic-rich visual representations 的模型。
统一对象检测和短语接地进行预训练。

将不同帧$X_t$中的特征集合在M中特征点的公式:

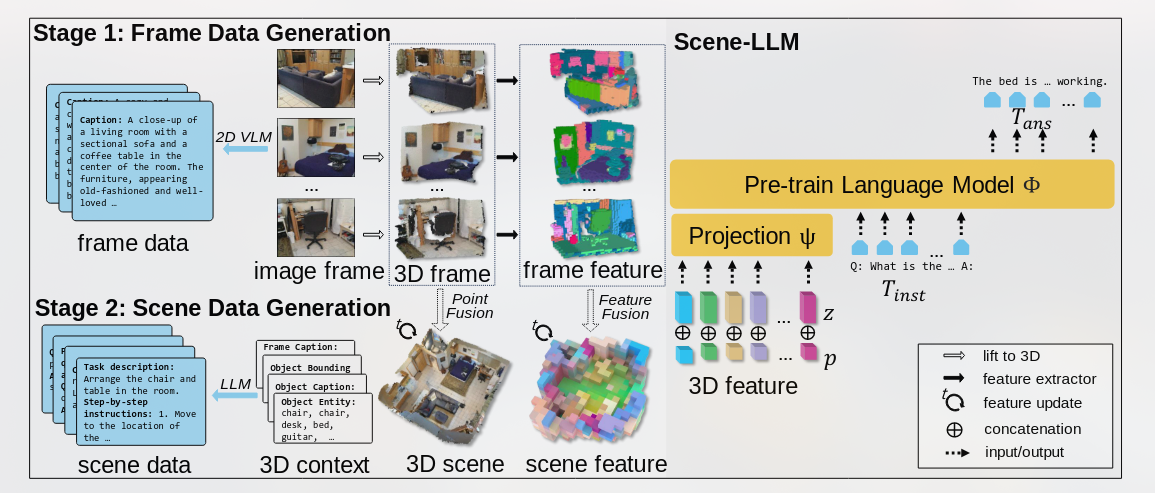
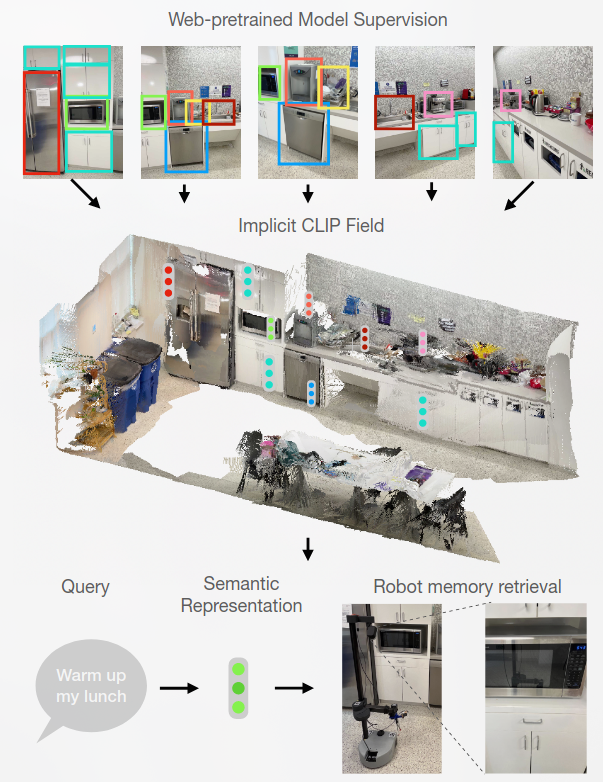
本文提出的模型主要想解决3D密集标注和交互式规划。
结合