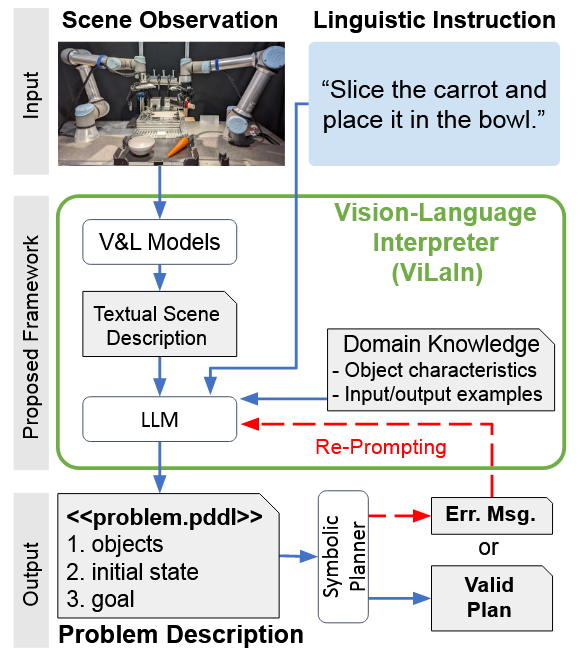
DREAM TO CONTROL= LEARNING BEHAVIORS BY LATENT IMAGINATION

论文使用**RSSM(Recurrent State Space Model)**:使用encoder来编码环境和动作生成latent state, 预测未来latent state,最后基于latent state预测奖励。

DREAM TO CONTROL= LEARNING BEHAVIORS BY LATENT IMAGINATION
论文使用**RSSM(Recurrent State Space Model)**:使用encoder来编码环境和动作生成latent state, 预测未来latent state,最后基于latent state预测奖励。
奠定世界模型= Intelligence without representation
目前学界广泛认为,世界模型是通往AGI的正确道路。而世界模型这一理念可以追溯到这篇1991年的文章。
1890 年代的人想造飞机,却只能根据他们零碎的观察去猜。他们看到现代飞机巨大、复杂,于是做了一个错误类比:
“现代飞机又大又重 → 所以重量不是问题。”
这当然荒唐。真正让飞机能飞的前提是升力、功率重量比、材料强度等关键工程指标的平衡。但他们只看到了表象,所以:
寓言中的团队觉得项目太大,所以分专业化研究,但他们犯了一个致命错误: 没有系统架构,没有统一指标,没有工程指导思想。
因此:
Brooks 的核心观点用一句话总结就是:
智能不是“建模世界 + 推理”的结果,而是“直接在世界中行动”的结果。世界本身就是模型,不需要额外的表征。
传统 AI(symbolic AI)强调:
Brooks 强烈反对。他认为:
这种思想后来直接催生了:

ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning
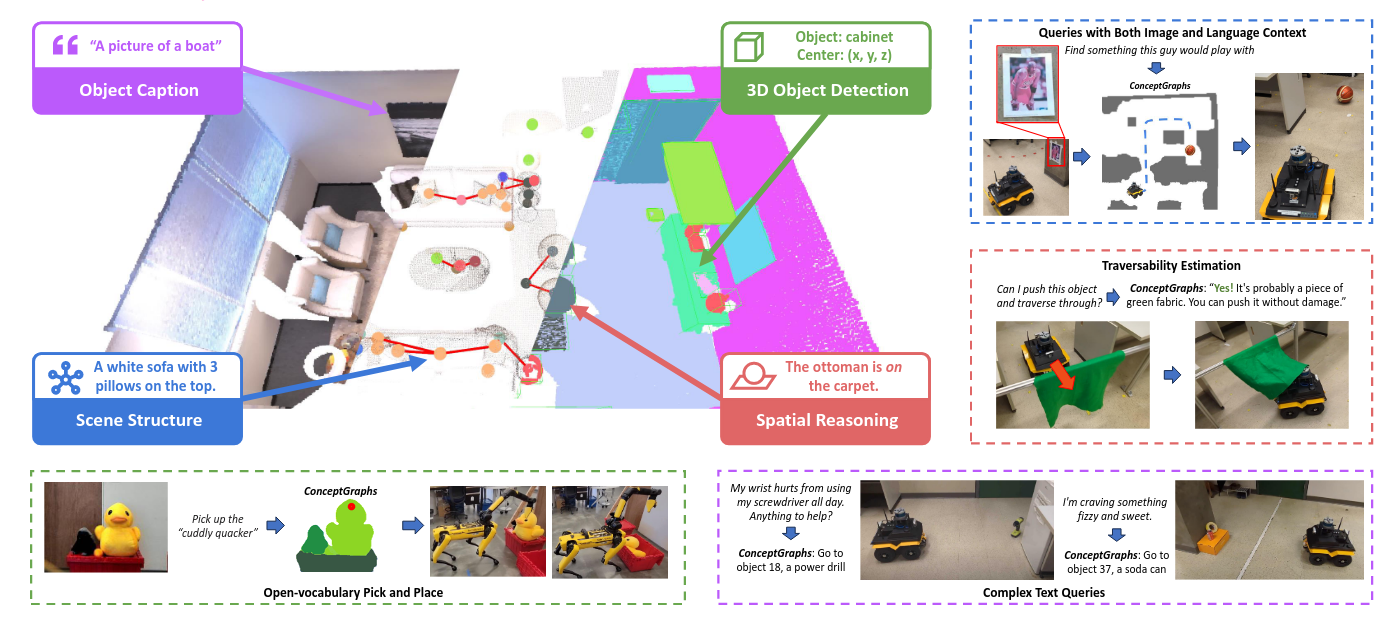
通过LLM来判断位置关系,以此构建scene graph
SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
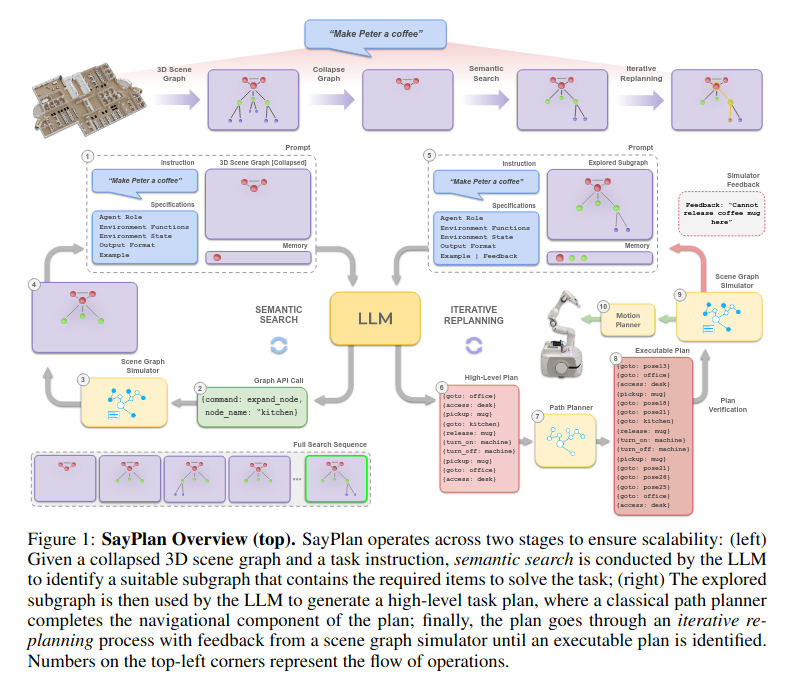
主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。