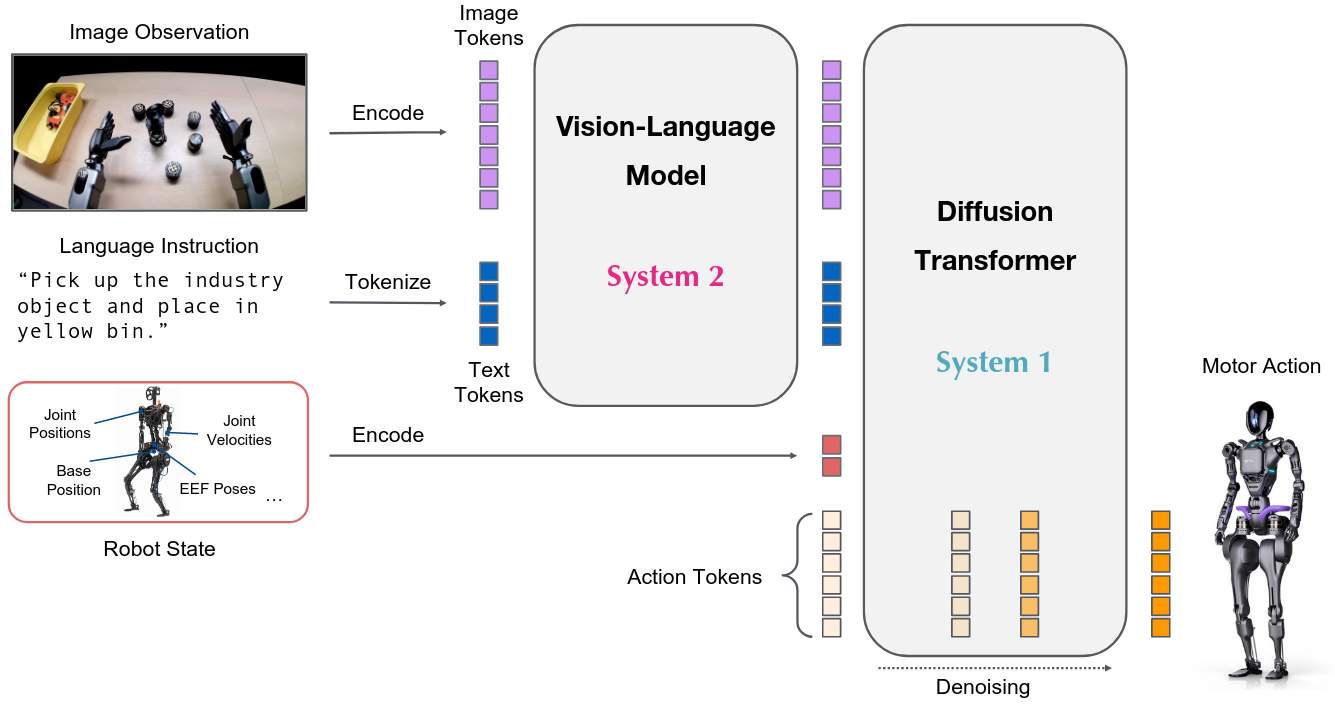
GR00T N1 An Open Foundation Model for Generalist Humanoid Robots
论文链接 | NVIDIA, 2025

A Survey of Imitation Learning- Algorithms, Recent Developments, and Challenges

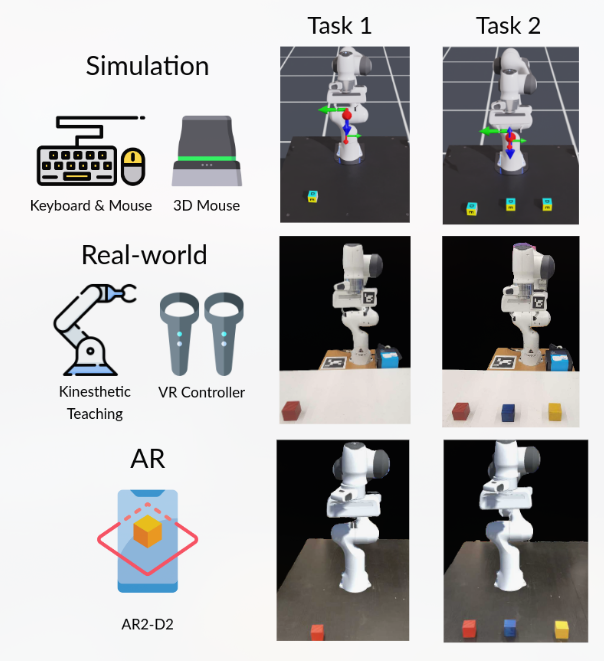
IL是区别于传统手动编程来赋予机器人自主能力的方法。
IL 允许机器通过演示(人类演示专家行为)来学习所需的行为,从而消除了对显式编程或特定于任务的奖励函数的需要。
IL主要有两个类别: