
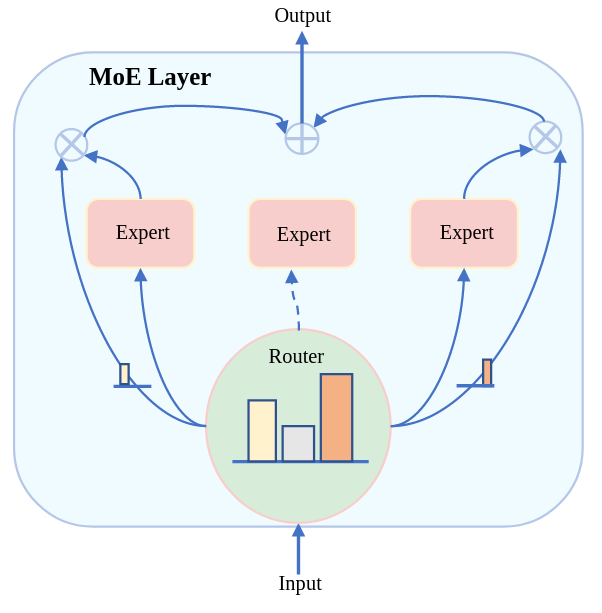

Neural Discrete Representation Learning | VQ-BeT: Behavior Generation with Latent Actions

DREAM TO CONTROL= LEARNING BEHAVIORS BY LATENT IMAGINATION

论文使用**RSSM(Recurrent State Space Model)**:使用encoder来编码环境和动作生成latent state, 预测未来latent state,最后基于latent state预测奖励。
A Survey of Imitation Learning- Algorithms, Recent Developments, and Challenges

IL是区别于传统手动编程来赋予机器人自主能力的方法。
IL 允许机器通过演示(人类演示专家行为)来学习所需的行为,从而消除了对显式编程或特定于任务的奖励函数的需要。
IL主要有两个类别:
联邦学习(Federated Learning, FL)作为一种新兴的分布式机器学习方法,已经引起了大量研究的关注。要系统地理解联邦学习的相关研究,建议遵循以下结构化的阅读图谱,以便逐步加深对其原理、应用和挑战的理解。
这些论文介绍了联邦学习的基本概念、目标、以及经典算法,是了解联邦学习的起点。
Konečnỳ, J., et al. (2016). “Federated Learning: Strategies for Improving Communication Efficiency” arXiv
McMahan, H. B., et al. (2017). “Communication-Efficient Learning of Deep Networks from Decentralized Data” arXiv
Yang, Q., Liu, Y., Cheng, Y., Kang, Y., Chen, T., & Yu, H. (2019). “Federated Learning” ACM Transactions on Intelligent Systems and Technology (TIST)
联邦学习的一个重要目标是确保数据的隐私和安全,这一领域的研究为其提供了理论基础和技术手段。
Bonawitz, K., et al. (2017). “Practical Secure Aggregation for Federated Learning on User-Held Data” arXiv
Geyer, R. C., Klein, T., & Nabi, M. (2017). “Differentially Private Federated Learning: A Client Level Perspective” arXiv
Zhao, Y., et al. (2018). “Federated Learning with Non-IID Data” arXiv
联邦学习中的通信和计算效率问题是该领域的关键研究方向,许多研究尝试通过各种方法优化模型训练过程中的资源消耗。
Li, X., et al. (2020). “Federated Optimization in Heterogeneous Networks” arXiv
Kairouz, P., et al. (2021). “Advances and Open Problems in Federated Learning” arXiv
Chen, M., et al. (2020). “Joint Learning and Communication Optimization for Federated Learning over Wireless Networks” arXiv
要更好地理解联邦学习在实际中的应用和系统架构,可以参考一些开源框架和实际实现案例。
Google AI. “Federated Learning for Mobile Keyboard Prediction” Blog Post
TensorFlow Federated (TFF): GitHub
联邦学习在诸多行业中都具有广泛的应用,了解这些应用有助于扩展对联邦学习实际意义的认识。
Rieke, N., et al. (2020). “The Future of Digital Health with Federated Learning” arXiv
Hard, A., et al. (2019). “Federated Learning for Mobile Keyboard Prediction” arXiv
对于未来的研究,联邦学习还面临许多挑战,比如系统异质性、模型性能与隐私保护的平衡等。
通过这个图谱,你可以系统地了解联邦学习的关键领域,并逐步深入到各个具体问题的解决方法与研究前沿。
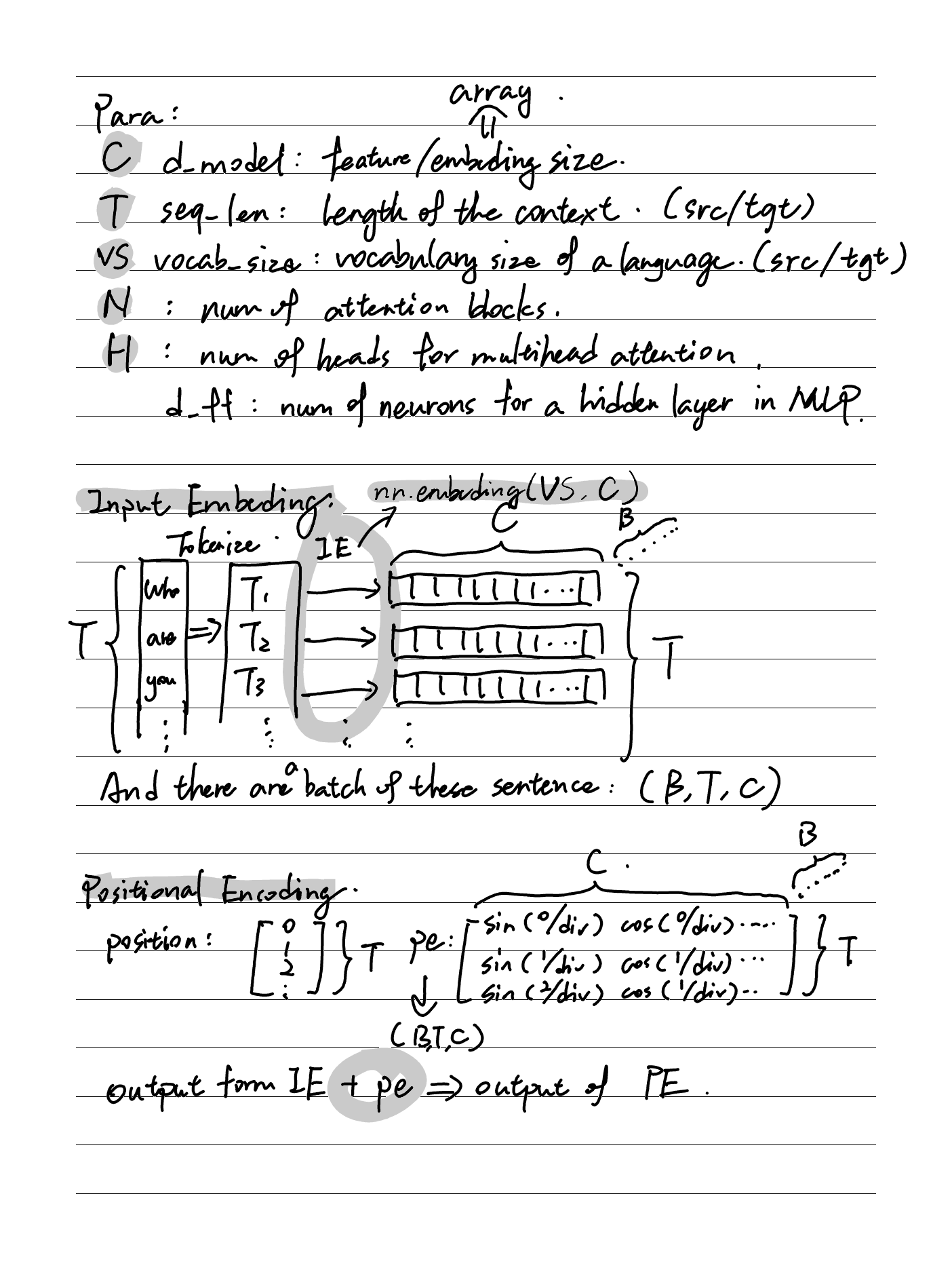
Transformer是一种基于注意力机制,完全不需要递归或卷积网络的序列预测模型,且更易于训练


