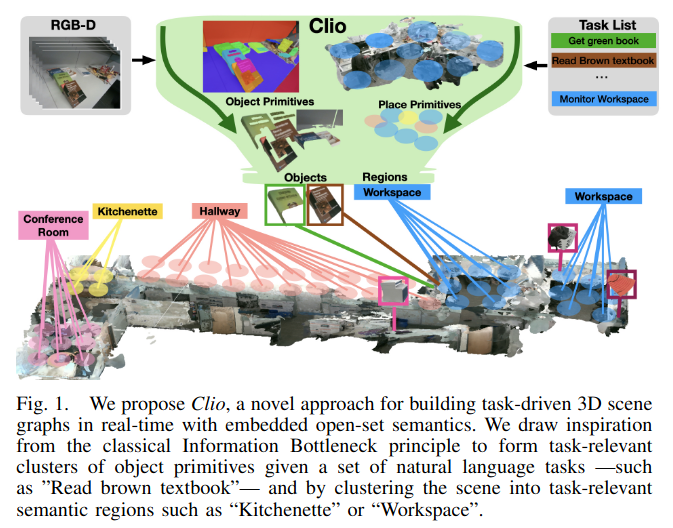


ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning
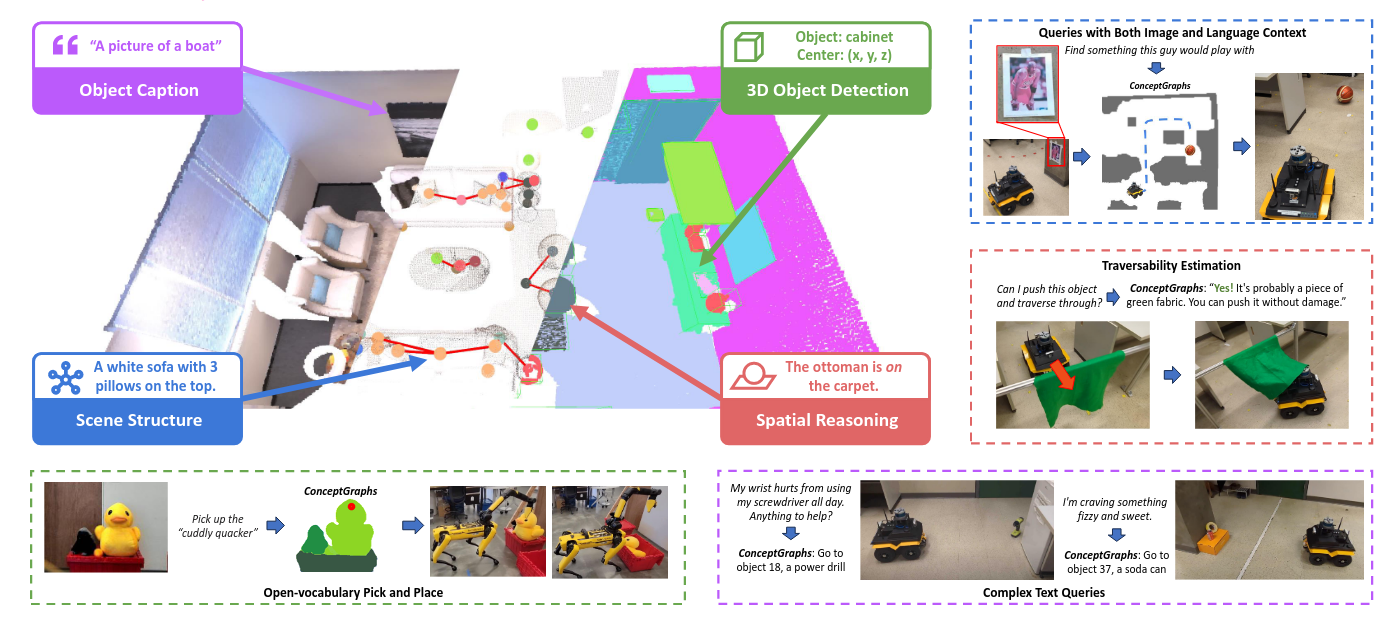
通过LLM来判断位置关系,以此构建scene graph

ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning
通过LLM来判断位置关系,以此构建scene graph

https://github.com/IDEA-Research/Grounded-Segment-Anything
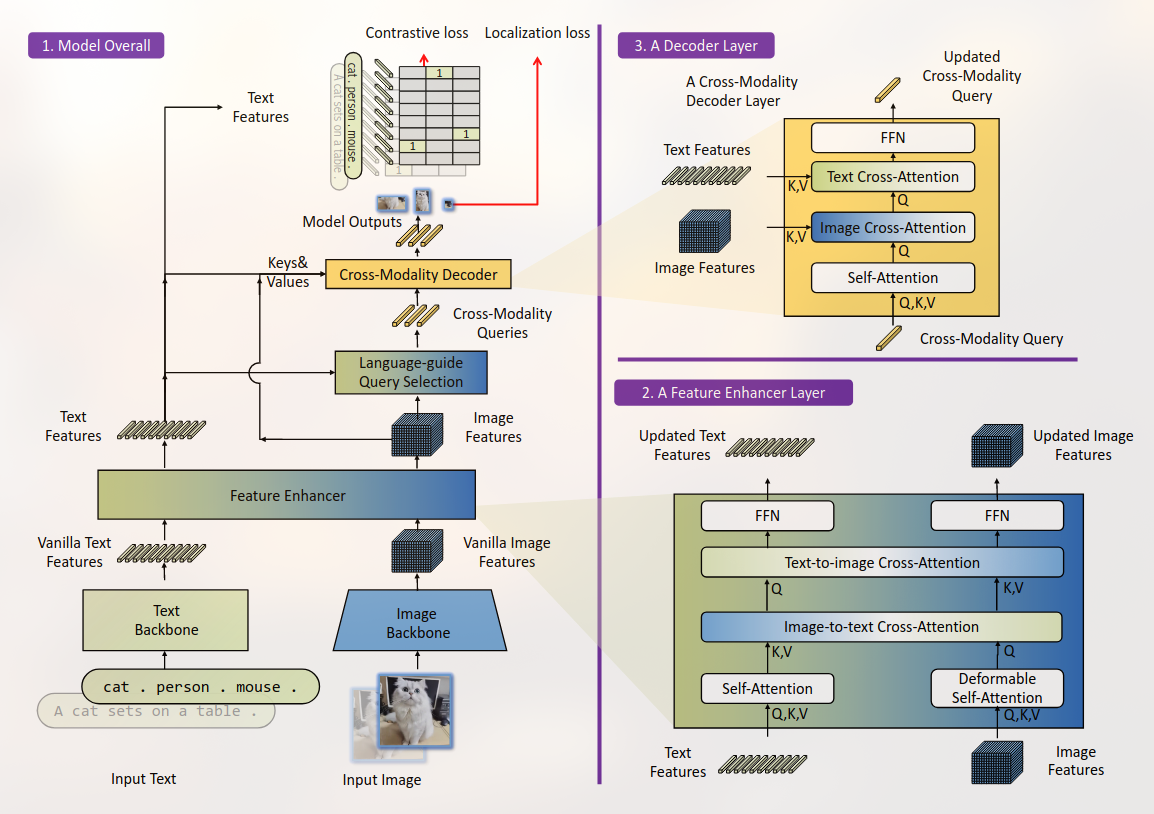
By [[Grounding-DINO]] + SAM
Achieving Open-Vocab. Det & Seg
OK-Robot- What Really Matters in Integrating Open-Knowledge Models for Robotics

Creating a general-purpose robot has been a longstanding dream of the robotics community.


