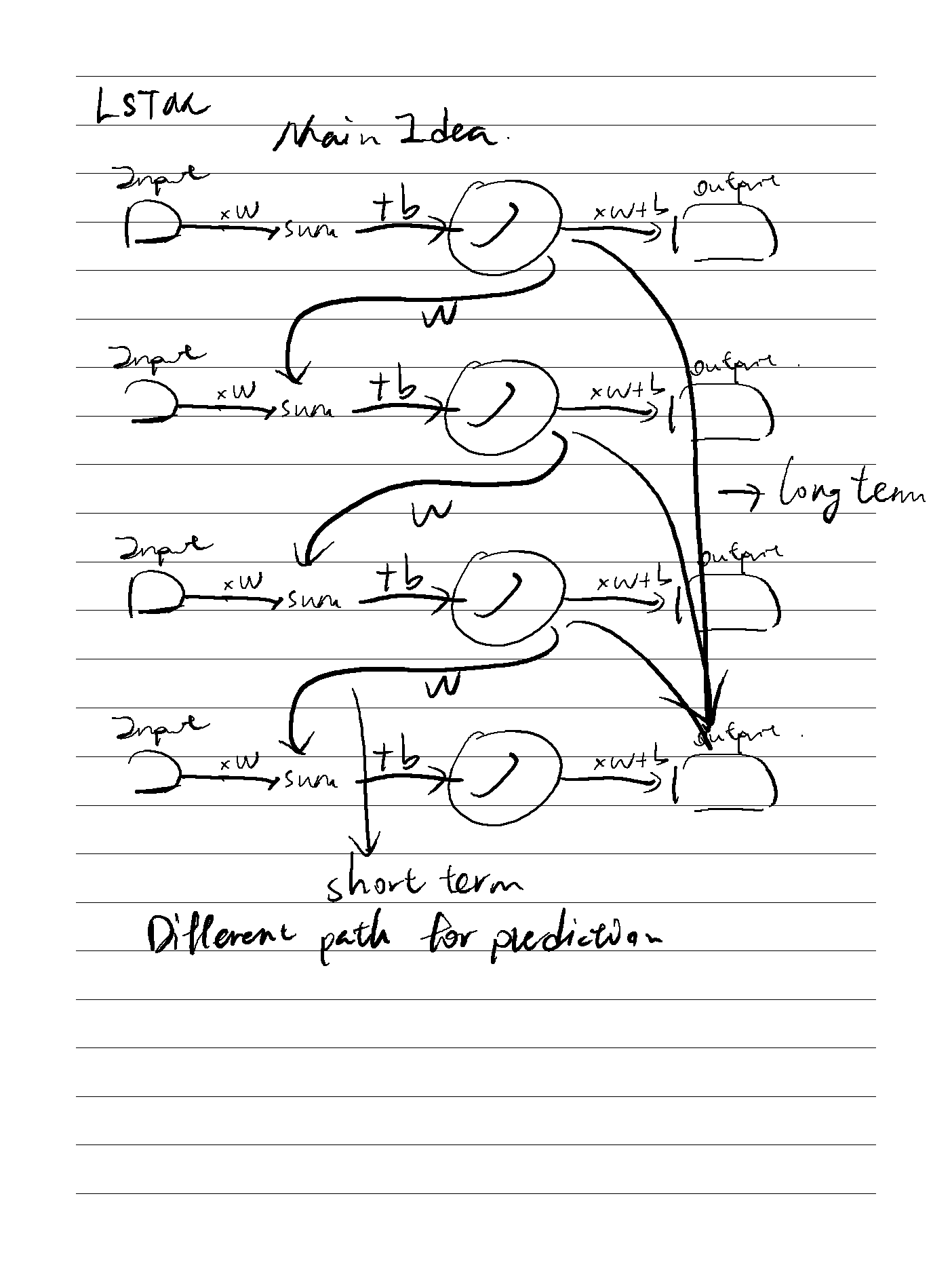
LSTM主要是用于解决递归网络中梯度指数级消失或者梯度爆炸的问题

LSTM主要是用于解决递归网络中梯度指数级消失或者梯度爆炸的问题
On the Properties of Neural Machine Translation= Encoder–Decoder Approaches

对比了 RNN Encoder-Decoder 和 GRU(new proposed)之间的翻译能力,发现GRU更具优势且能够理解语法。
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling

首先介绍了RNN通过hidden state来实现记忆力功能

