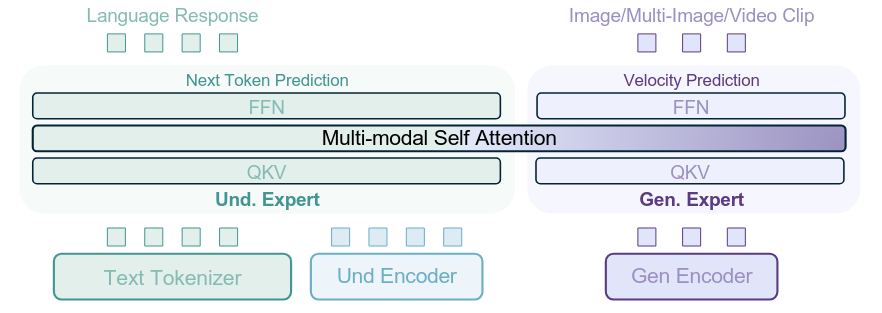
Posted 2026-02-06Updated 2026-05-05Review10 minutes read (About 1443 words)BAGEL-Unified-Multimodal-Pretraining论文链接 | 项目主页#Research-paperMulti-modalVLMDiffusionTransformerMoEUnified-MultimodalFoundationModelImage-generationImage2Text
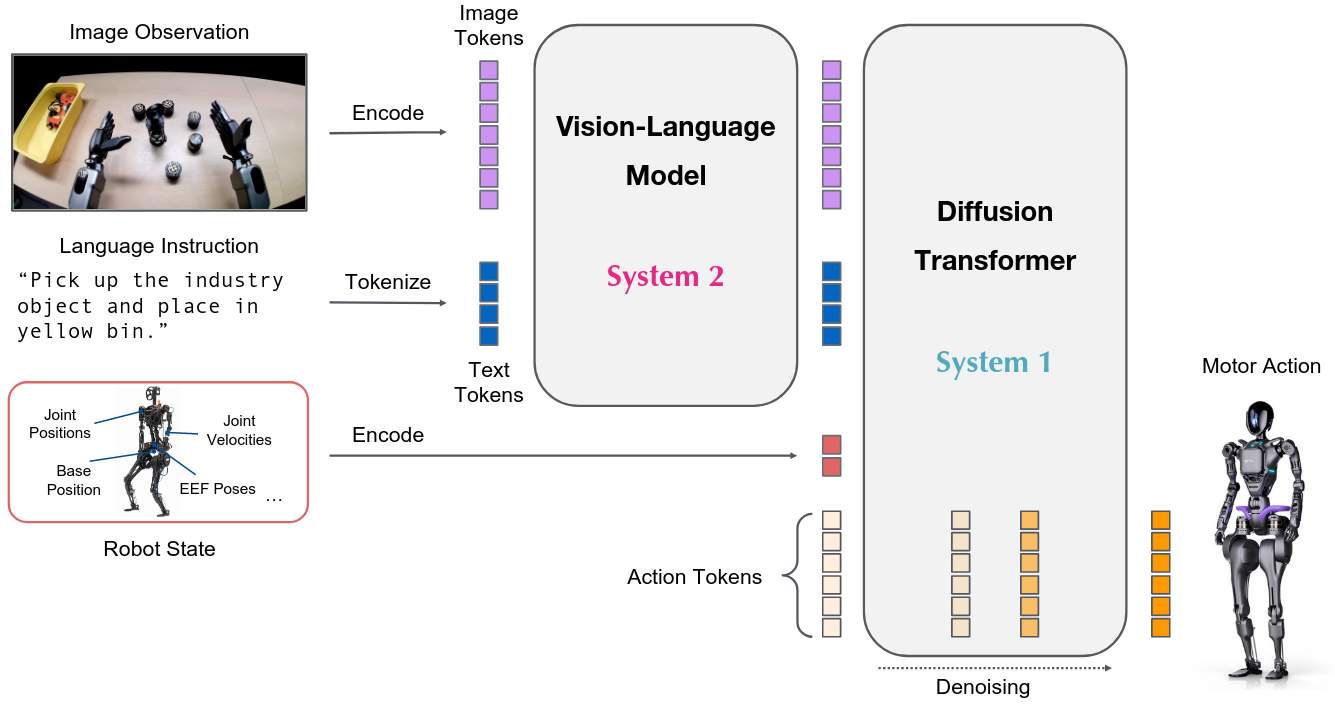
Posted 2026-02-02Updated 2026-05-05Review28 minutes read (About 4167 words)GR00T N1 An Open Foundation Model for Generalist Humanoid Robots论文链接 | NVIDIA, 2025#RoboticsResearch-paperMulti-modalVLMTransformerFoundationModelDiffusionModelImitationLearningRobotLearningVLAHumanoidRobot
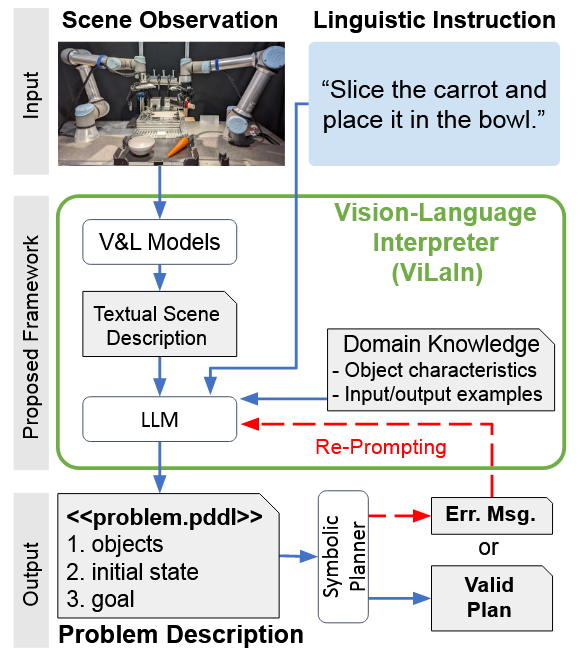
Posted 2025-04-16Updated 2026-05-05Notea few seconds read (About 3 words)Vision-Language Interpreter for Robot Task Planning#RoboticsResearch-paperMulti-modalVLMEmbodied-AITask-Planning
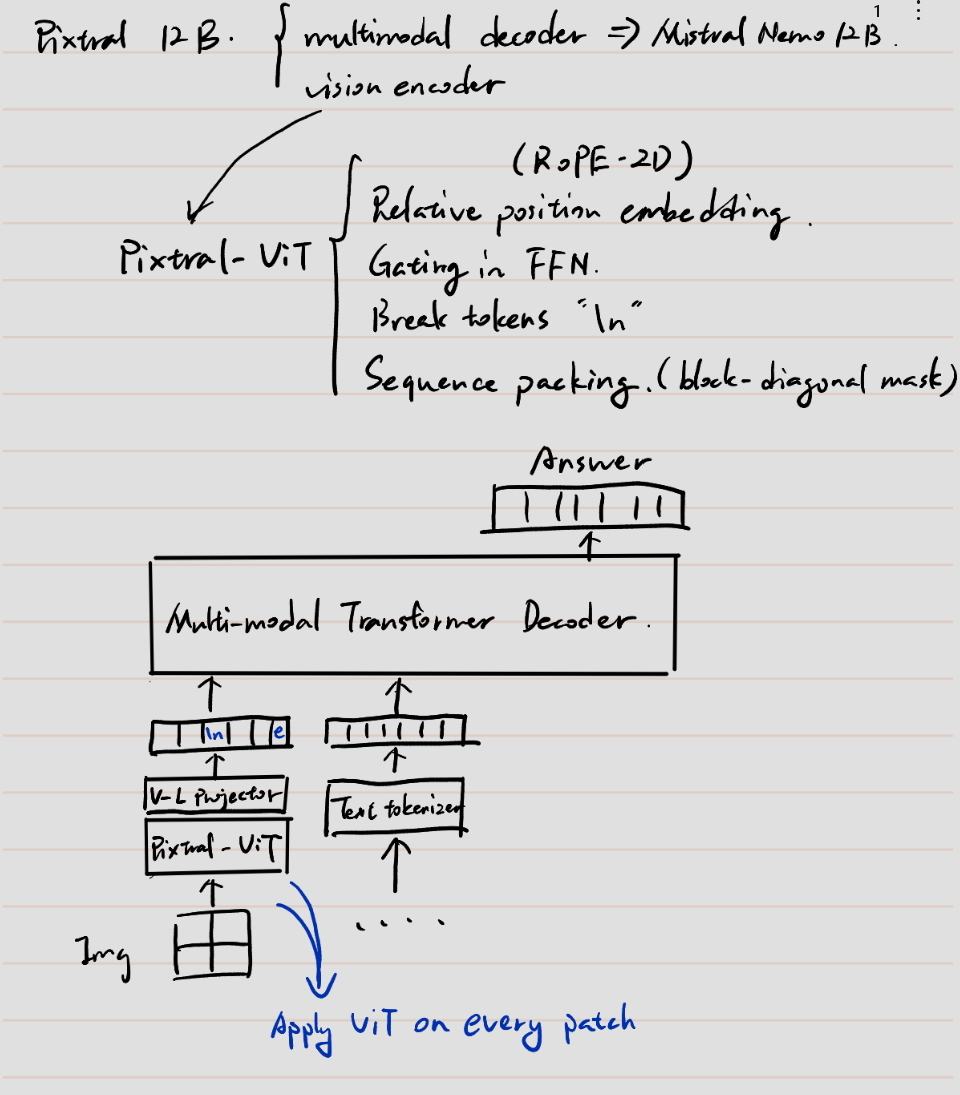
Posted 2025-04-15Updated 2026-05-05Reviewa few seconds read (About 30 words)Pixtral 12BWeb: https://mistral.ai/news/pixtral-12bDemo: https://chat.mistral.ai/chatFinetune: https://github.com/2U1/Pixtral-FinetuneModel: https://huggingface.co/mistralai/Pixtral-12B-2409#Research-paperMulti-modalVLMTransformerFoundationModel
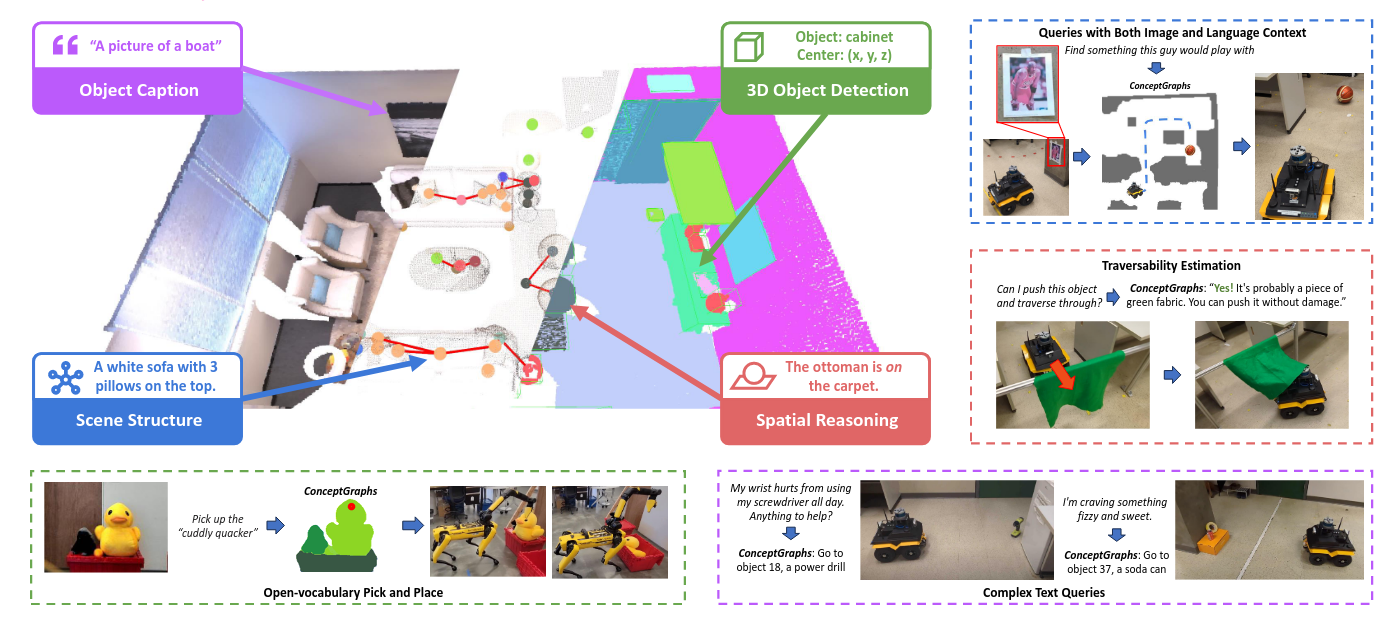
Posted 2025-03-19Updated 2026-05-05Reviewa few seconds read (About 42 words)ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning通过LLM来判断位置关系,以此构建scene graph#RoboticsScene-graphResearch-paperLLMVLM3D-SceneEmbodied-AIOpen-VocabularyTask-Planning
Posted 2025-03-13Updated 2026-05-05Reviewa few seconds read (About 6 words)From Pixels to Graphs= Open-Vocabulary Scene Graph Generation with Vision-Language Models#Scene-graphVisual-RelationResearch-paperCVMulti-modalVLMOpen-Vocabulary
Posted 2025-03-11Updated 2026-05-05Reviewa few seconds read (About 0 words)OMG-LLaVA#Research-paperLLMMulti-modalVLM
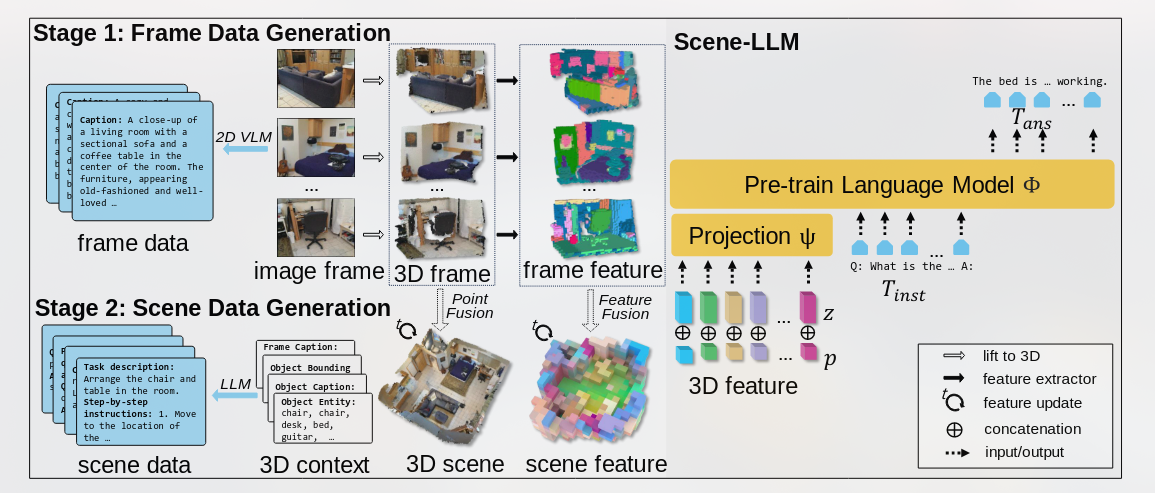
Posted 2025-02-15Updated 2026-05-05Review6 minutes read (About 919 words)Scene-LLM本文提出的模型主要想解决3D密集标注和交互式规划。结合#RoboticsResearch-paperLLMMulti-modalVLM3D-SceneEmbodied-AICLIP