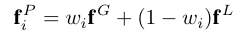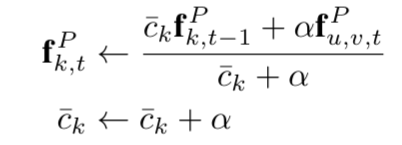## Approach
目标是构建一个open-set multimodal 3D map `M`.
可以使用特定于模态的编码器(基础模型)$F_{Mode}$将图像,文本,音频和点击等多维信号编码为矢量空间
其中,`M` 由一系列点构成,每个点都包含:顶点位置,法向向量,置信度数量,颜色和概念向量(concept vector)组成
首先是帧(单张输入图片)预处理:通过一系列输入的深度图片获取顶点法相maps和相机方位,再通过计算获得每张图片中每个像素的语义上下文嵌入。其中,语义上下文的嵌入是通过结合局部和全局的CLIP features获得的。
然后再进行特征融合:通过相机的方位将每个帧的顶点和法相图映射到全局坐标系。对于帧$X_{t}$中的每个像素$(u,v)_t$,都在`M`中具有相应的点$P_k$
将不同帧$X_t$中的特征集合在M中特征点的公式: