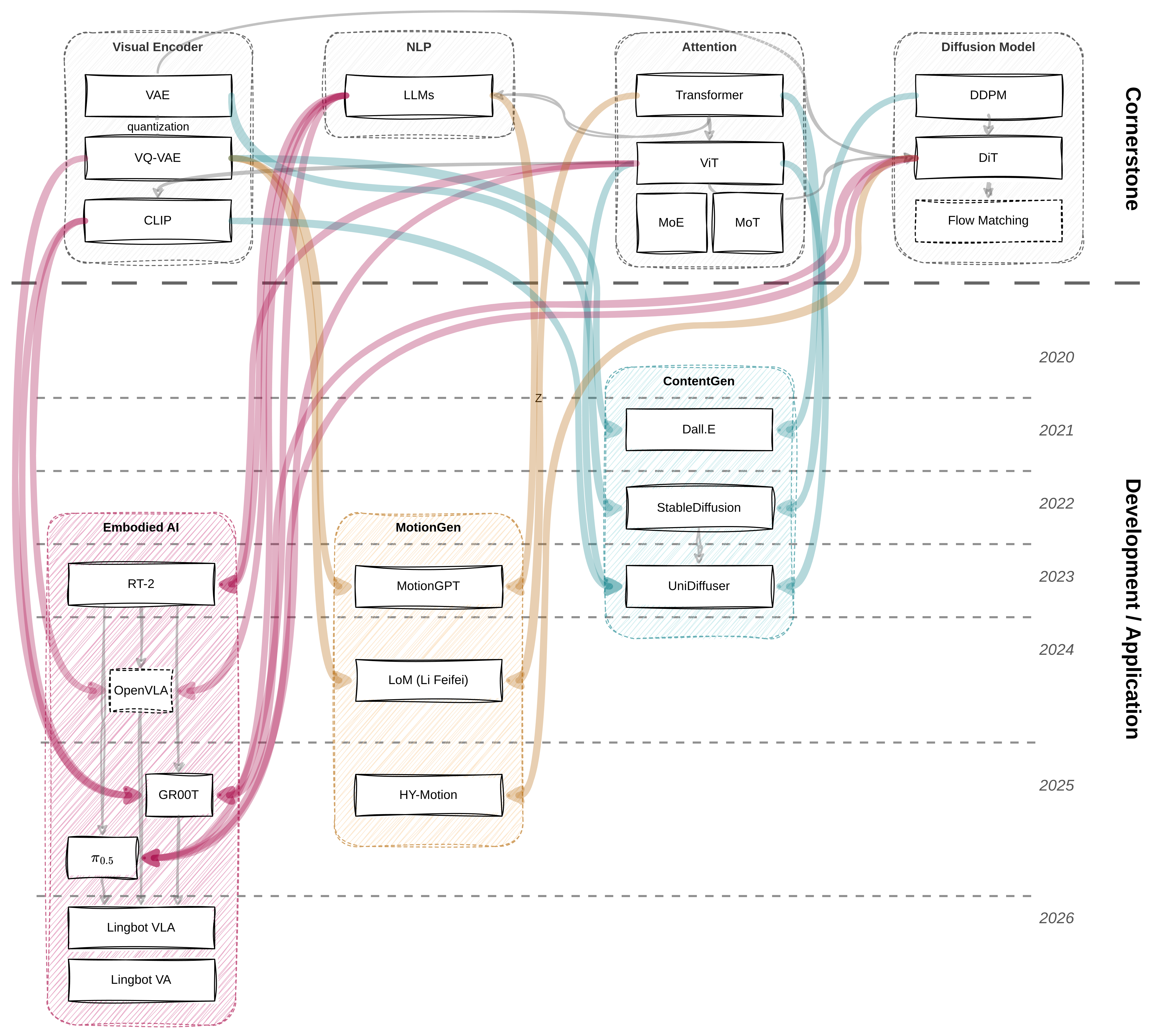
VLA背景论文调研
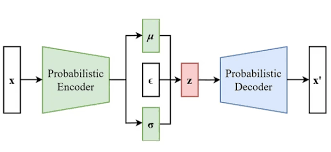
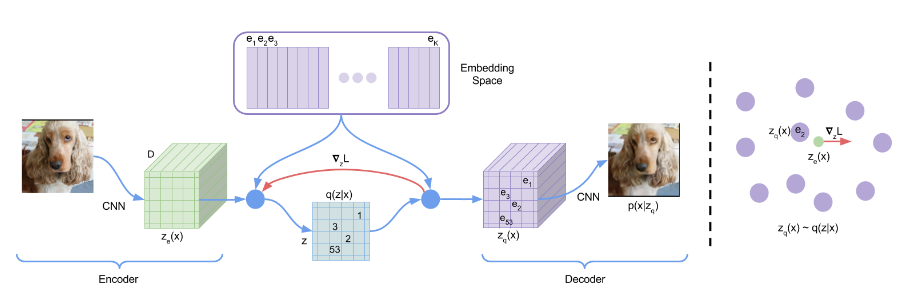
变分自编码器VAE/VQ-VAE
解决了什么问题:如何压缩数据,并从压缩后的特征中重新生成数据。
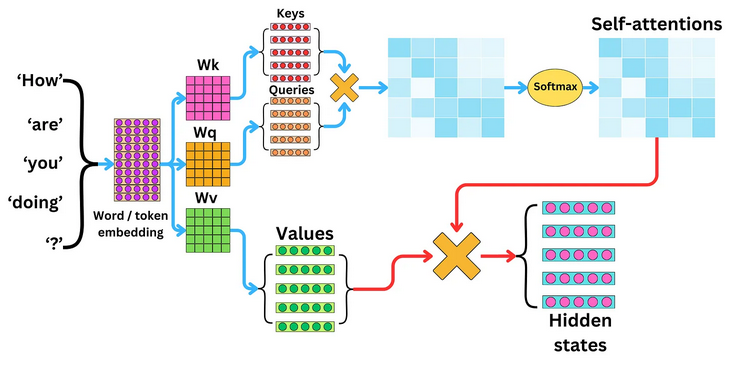
注意力机制Self-Attention/Cross-Attention
解决了什么问题:跨模态,长距离的序列理解和预测。
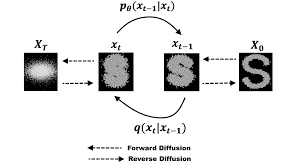
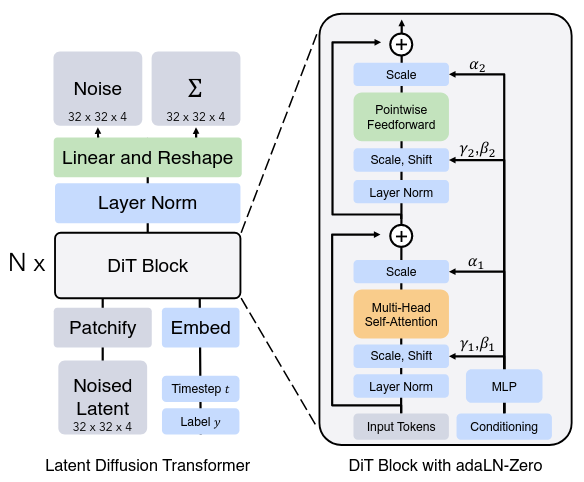
内容生成-图片&文字
主要是基于Diffusion Model的应用,引入了多模态。例如Stable Diffusion结合了CLIP的text encoder和KL-VAE的图像潜空间。
解决了什么问题:如何压缩数据,并从压缩后的特征中重新生成数据。
解决了什么问题:跨模态,长距离的序列理解和预测。
主要是基于Diffusion Model的应用,引入了多模态。例如Stable Diffusion结合了CLIP的text encoder和KL-VAE的图像潜空间。

