
MotionGPT3
相关工作
人体动作建模
- Early: shared embedding for motion&texts
- Recent: raw motion / reconstruct VAE latent
- 为了适配next-token-prediction(LLM) 也有工作使用离散化的动作表达(VQ-VAE),但是根本上还是会有symbolic-continuous mismatch
本文还是使用正常的VAE
- 为了适配next-token-prediction(LLM) 也有工作使用离散化的动作表达(VQ-VAE),但是根本上还是会有symbolic-continuous mismatch
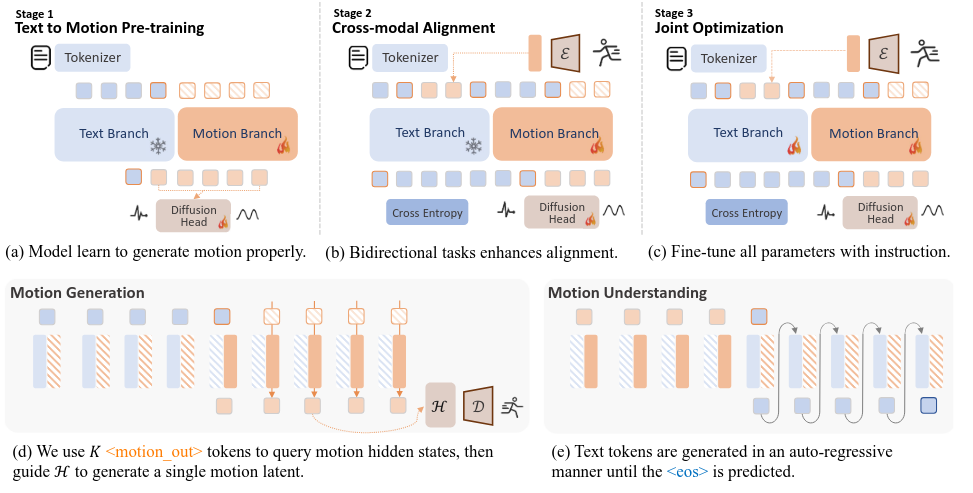
多模态的理解与生成框架
目前有许多single-streamd 框架,但是单流架构经常受到跨模式干扰,限制了可扩展性和鲁棒性。即使目标经过精心调整,新引入的模式也可能会破坏现有的表示形式,这凸显了在扩展到新领域的同时保留特定模式能力的挑战。
MoE & 多流架构
通过将输入路由到该模态特定的Expert中进行处理,同时保留一个共享的融合接口,避免了dradient interference between different modality. 每个模态,每个branch可以有自己的训练目标。
本文使用MoT
方法
Motion Representation
通过重建损失和KL正则来训练的motion VAE.
o

