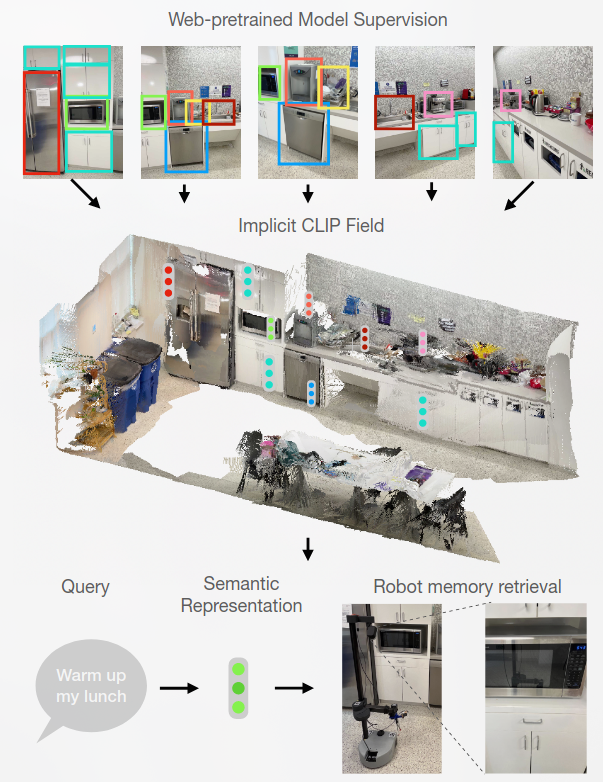
本文提出的模型主要想解决3D密集标注和交互式规划。
结合

本文提出的模型主要想解决3D密集标注和交互式规划。
结合
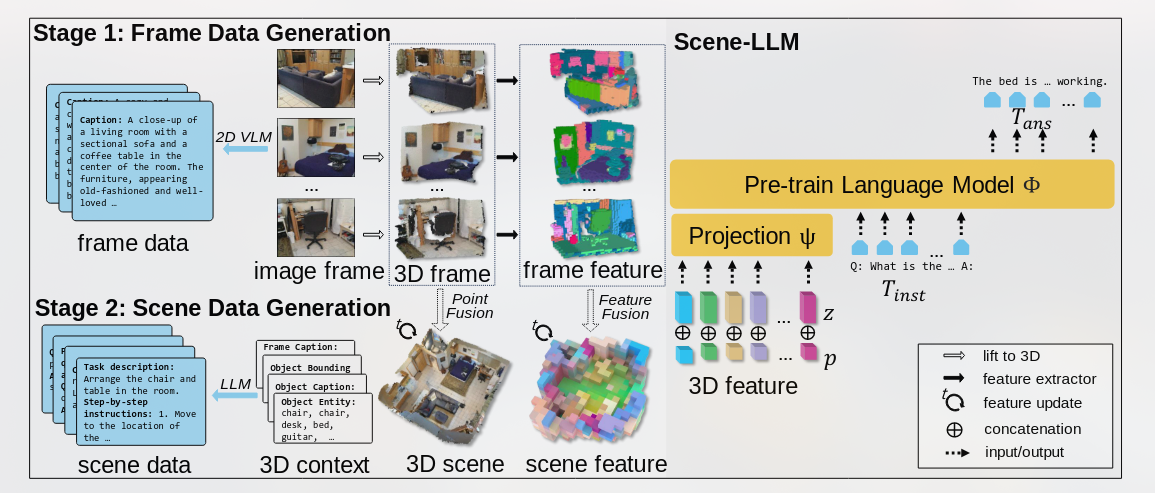
Recent works have explored aligning images and videos with LLM for a new generation of multi-modal LLMs that equip LLMs with the ability to understand and reason about 2D images.
但是仍缺少对于3D物理空间进行分析的模型, which involves richer concepts such as spatial relationships, affordances, physics and interaction so on.
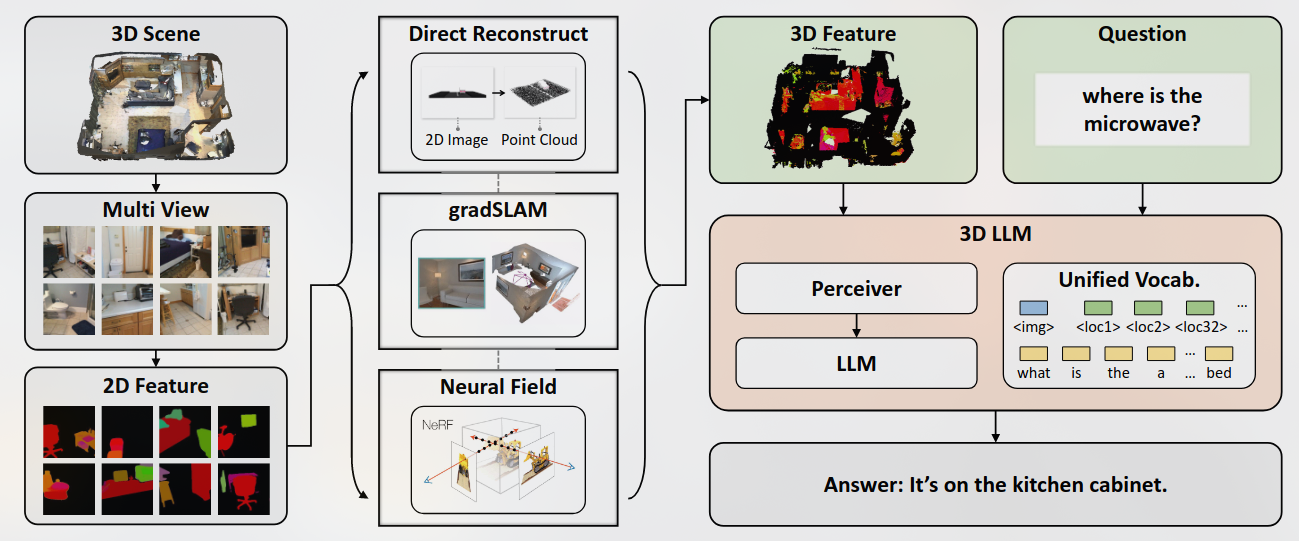
OK-Robot- What Really Matters in Integrating Open-Knowledge Models for Robotics

Creating a general-purpose robot has been a longstanding dream of the robotics community.
Dynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
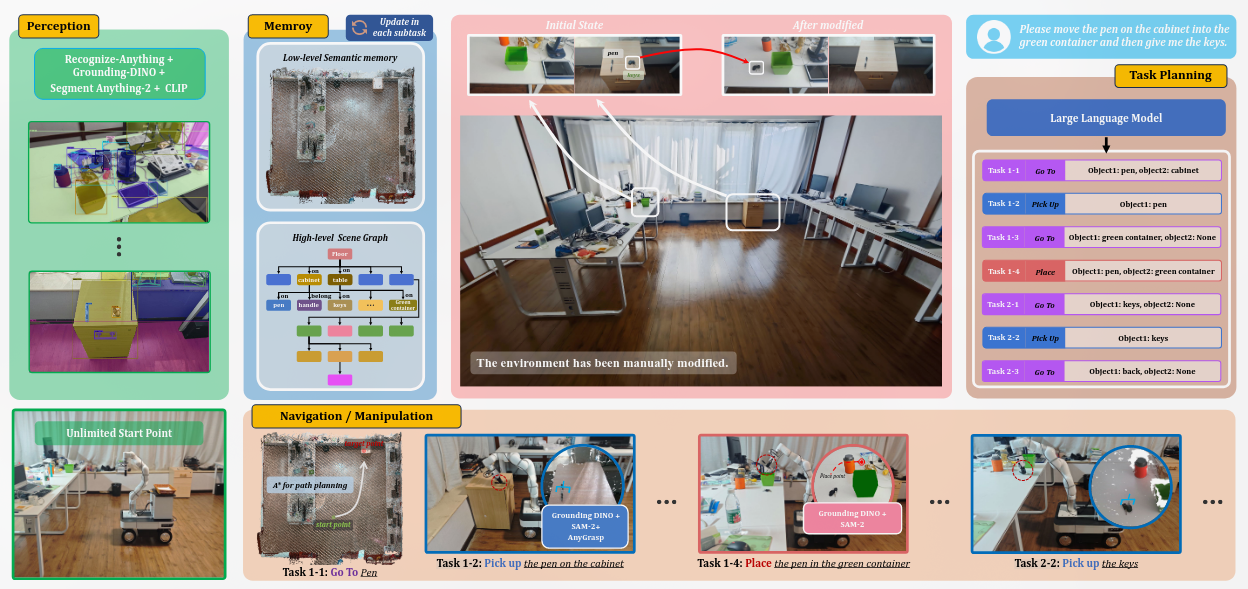
和我的想法非常相近,完成度也很高啊喂。可以参考他的实现思路,引用的文章等等。