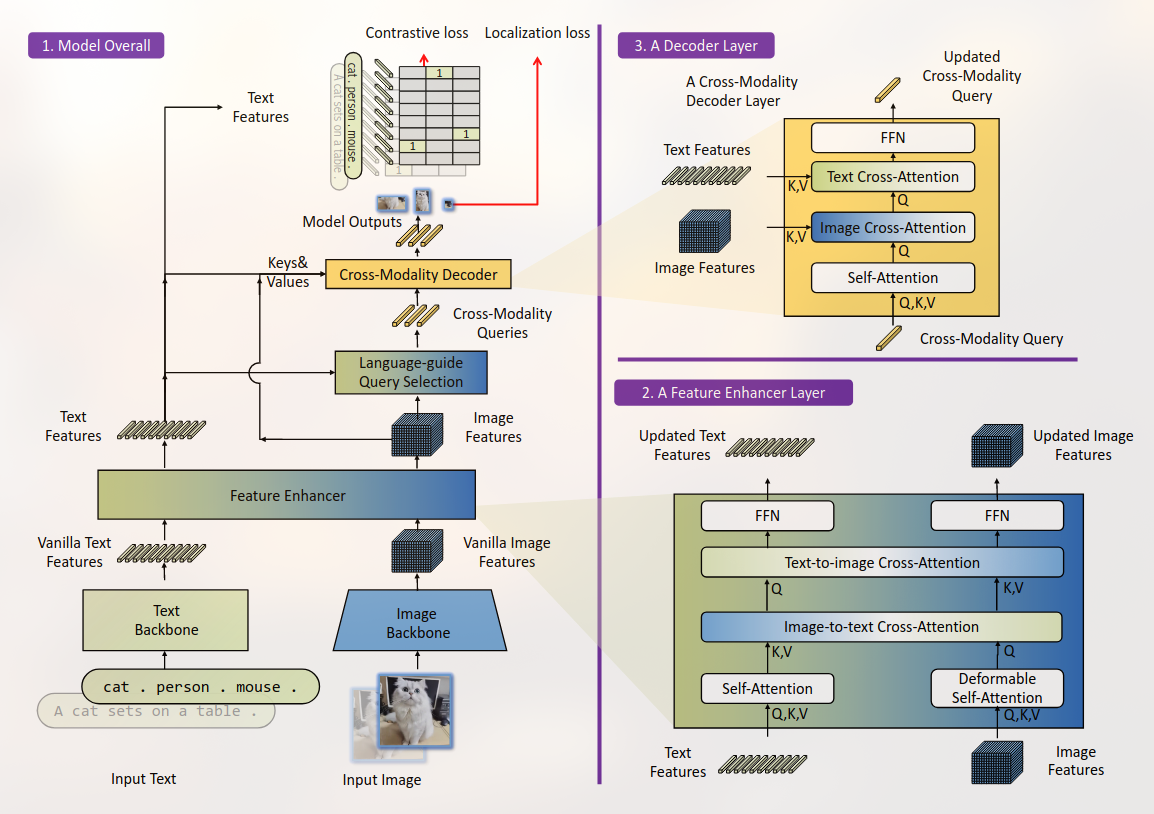
Posted 2025-02-16Updated 2026-03-08Reviewa minute read (About 216 words)Grounding-DINO,#Research-paperTransformerCVObject-DetectionOpen-VocabularyContrastive-LearningMultiModalDINOImage-Grounding
Posted 2025-02-16Updated 2026-03-08Reviewa few seconds read (About 17 words)Gounded-SAMhttps://github.com/IDEA-Research/Grounded-Segment-Anything By [[Grounding-DINO]] + SAMAchieving Open-Vocab. Det & Seg #Research-paperCVObject-DetectionSemanticOpen-VocabularySegmentation
Posted 2025-01-09Updated 2026-03-08Note5 minutes read (About 722 words)Momentum Contrast for Unsupervised Visual Representation Learning伪代码:#Research-paperCVRepresentation-LearningContrastive-Learning
Posted 2025-01-09Updated 2026-03-08Notea few seconds read (About 0 words)Vision Transformers Need Registers#Research-paperTransformerCVViT
Posted 2025-01-09Updated 2026-03-08Notea few seconds read (About 0 words)DINOv2- Learning Robust Visual Features without Supervision#Research-paperTransformerCVRepresentation-LearningViTDINO
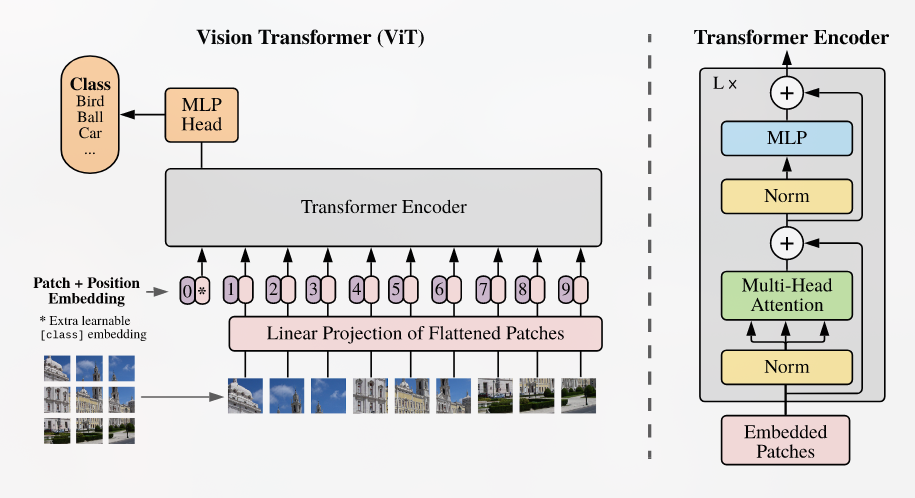
Posted 2025-01-09Updated 2026-03-08Notea few seconds read (About 71 words)AN IMAGE IS WORTH 16X16 WORDS- TRANSFORMERS FOR IMAGE RECOGNITION AT SCALEhttps://www.youtube.com/watch?v=j3VNqtJUoz0&t=16s#Research-paperTransformerCVViT
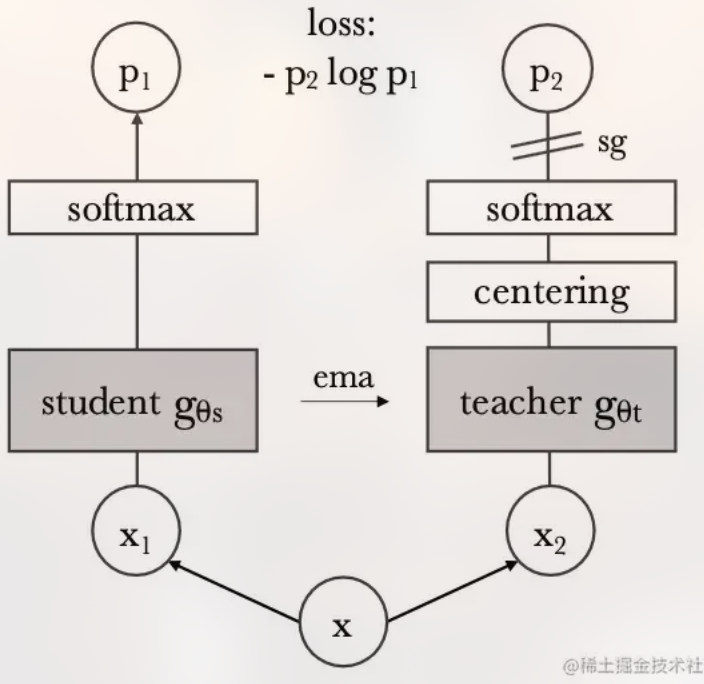
Posted 2025-01-08Updated 2026-03-08Note4 minutes read (About 561 words)DINOhttps://github.com/facebookresearch/dino/tree/main#Research-paperTransformerCVRepresentation-LearningViTDINO
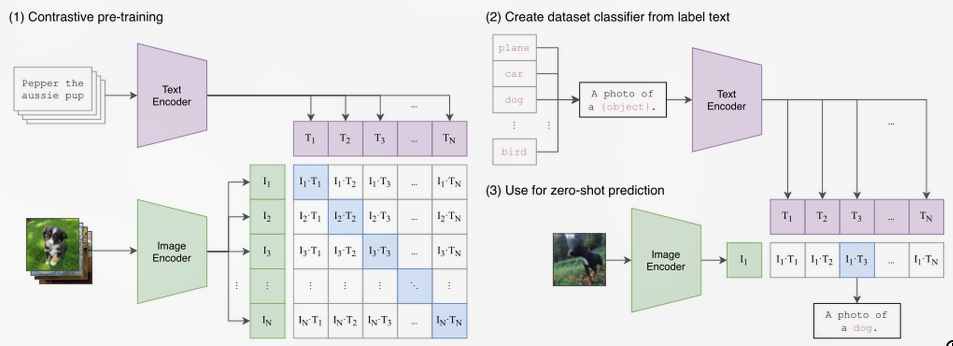
Posted 2025-01-06Updated 2026-03-08Notea minute read (About 197 words)CLIPhttps://blog.csdn.net/h661975/article/details/135116957#Research-paperImage2TextCVCLIPContrastive-LearningMultiModalVLPImage-Text
Posted 2025-01-06Updated 2026-03-08Note5 minutes read (About 790 words)LERF- Language Embedded Radiance FieldsNeRF+CLIP#Research-paperLLMCVReconstruct3D-SceneEmbodied-AISemanticCLIP
Posted 2025-01-06Updated 2026-03-08Notea few seconds read (About 3 words)Simple Open-Vocabulary Object Detection with Vision Transformers#Research-paperTransformerCVObject-DetectionOpen-VocabularyViT