Posted 2026-02-03Updated 2026-03-23Review15 minutes read (About 2285 words)UniDiffuser论文链接 | GitHub#Research-paperMulti-modalTransformerImage2TextCVDiffusionModelImgGen
Posted 2026-02-03Updated 2026-03-23Review18 minutes read (About 2709 words)Scalable Diffusion Models with TransformersScalable Diffusion Models with Transformers | ICCV 2023#Research-paperTransformerCVDiffusionModelImgGenScalability
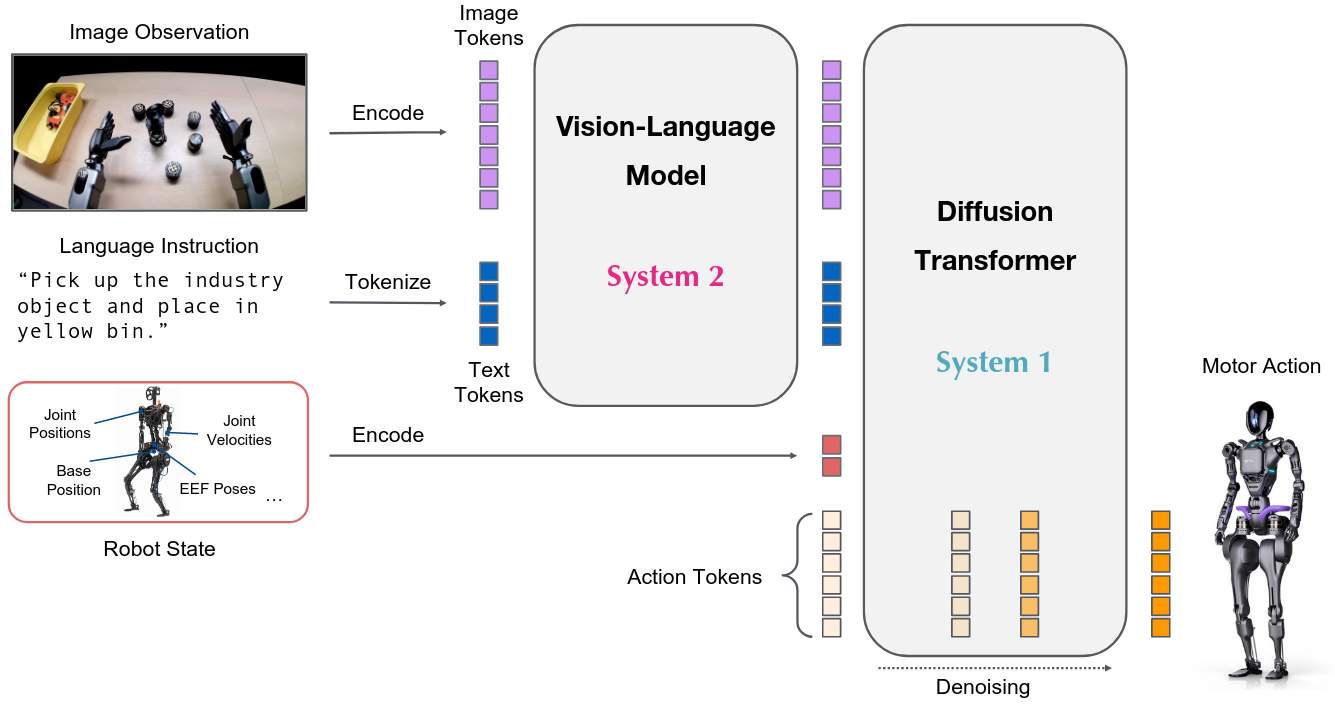
Posted 2026-02-02Updated 2026-03-23Review28 minutes read (About 4167 words)GR00T N1 An Open Foundation Model for Generalist Humanoid Robots论文链接 | NVIDIA, 2025#Research-paperRoboticsMulti-modalVLMTransformerFoundationModelDiffusionModelVLARobotLearningImitationLearningHumanoidRobot
Posted 2025-03-11Updated 2026-03-23Reviewa few seconds read (About 3 words)PHYSCENE- Physically Interactable 3D Scene Synthesis for Embodied AI#Research-paperDiffusionModel3D-SceneEmbodied-AIScene-synthesisPhysical-Scene