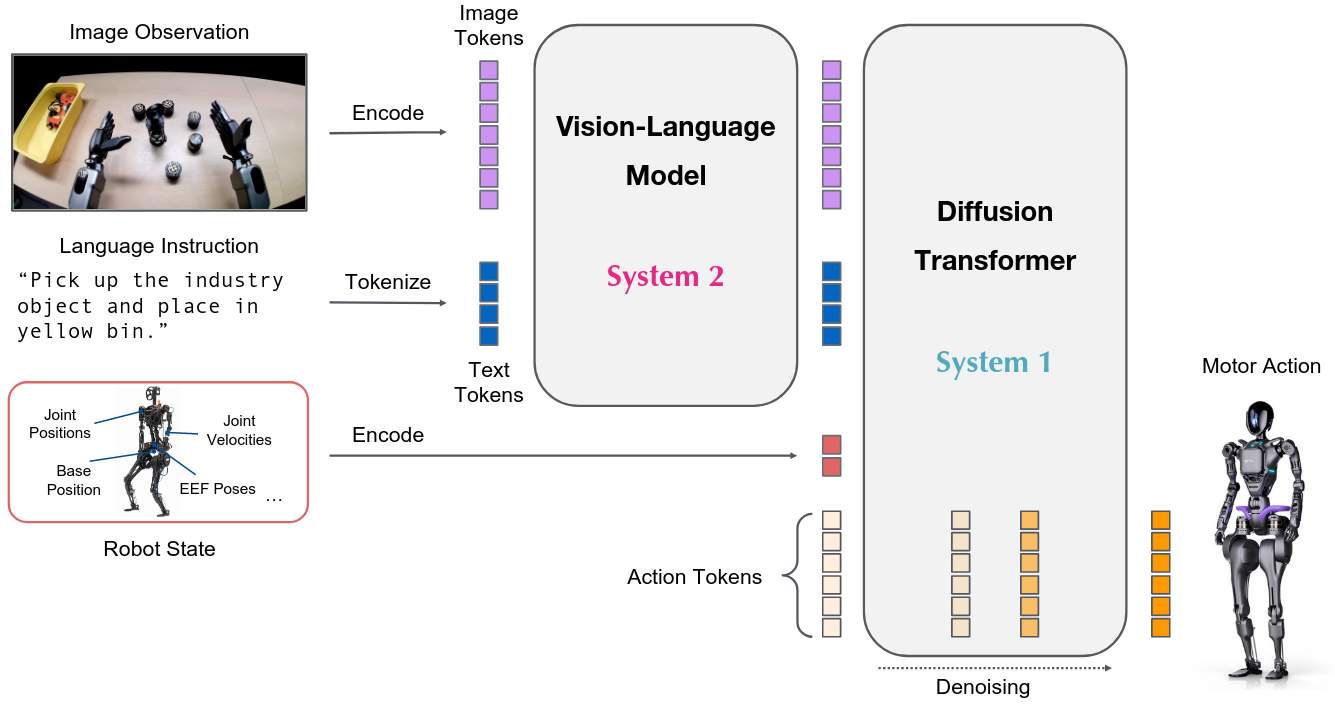
Posted 2026-02-02Updated 2026-03-23Review28 minutes read (About 4167 words)GR00T N1 An Open Foundation Model for Generalist Humanoid Robots论文链接 | NVIDIA, 2025#Research-paperRoboticsMulti-modalVLMTransformerFoundationModelDiffusionModelVLARobotLearningImitationLearningHumanoidRobot