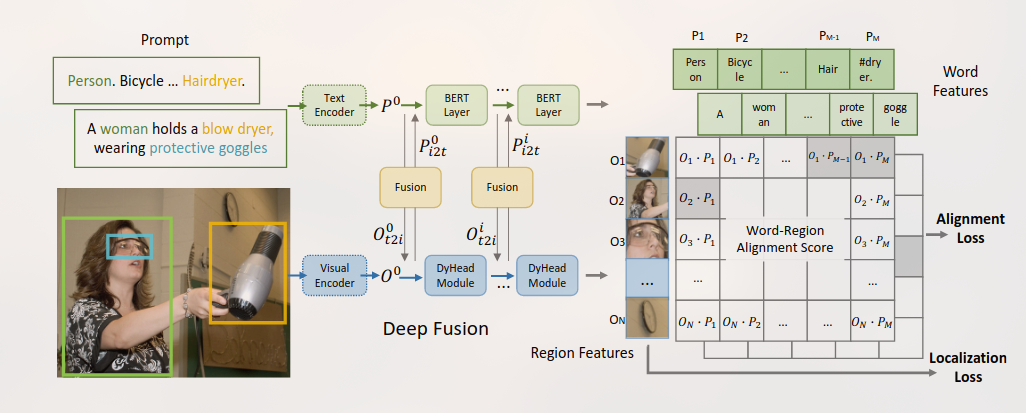
Posted 2025-02-19Updated 2026-03-30Review2 minutes read (About 273 words)GLIPGLIP是一个学习了object-level, language-aware, and semantic-rich visual representations 的模型。统一对象检测和短语接地进行预训练。#Research-paperMulti-modalCVObject-DetectionCLIPContrastive-LearningVLPImage-Grounding
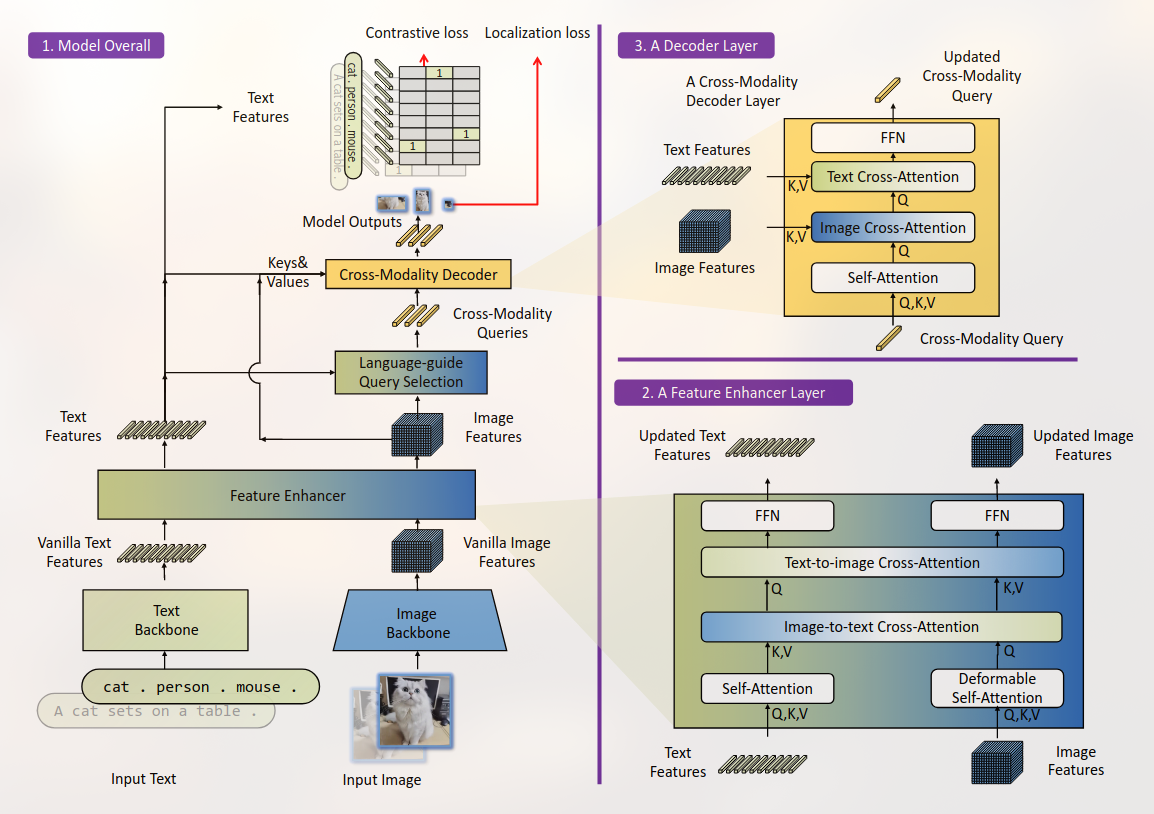
Posted 2025-02-16Updated 2026-03-30Reviewa minute read (About 216 words)Grounding-DINO,#Research-paperTransformerCVObject-DetectionMultiModalOpen-VocabularyContrastive-LearningDINOImage-Grounding