

 Contextual Translation Embedding for Visual Relationship Detection and Scene Graph Generation/Pasted_image_20250318160643.png)
 Visual Translation Embedding Network for Visual Relation Detection/Pasted_image_20250318155431.png)
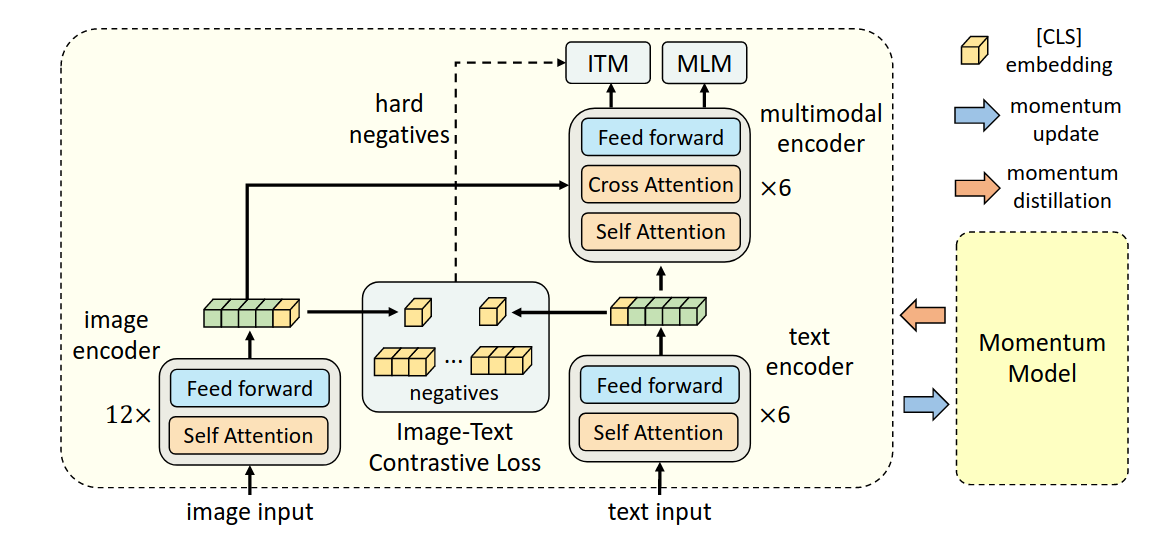
使用的backbone是BERT(通过MLM训练)
该研究认为,image encoder的模型大小应该大于text encoder,所以在text encoder这里,只使用六层self attention来提取特征,剩余六层cross attention用于multi-modal encoder。
使用的backbone是BERT(通过MLM训练)
该研究认为,image encoder的模型大小应该大于text encoder,所以在text encoder这里,只使用六层self attention来提取特征,剩余六层cross attention用于multi-modal encoder。