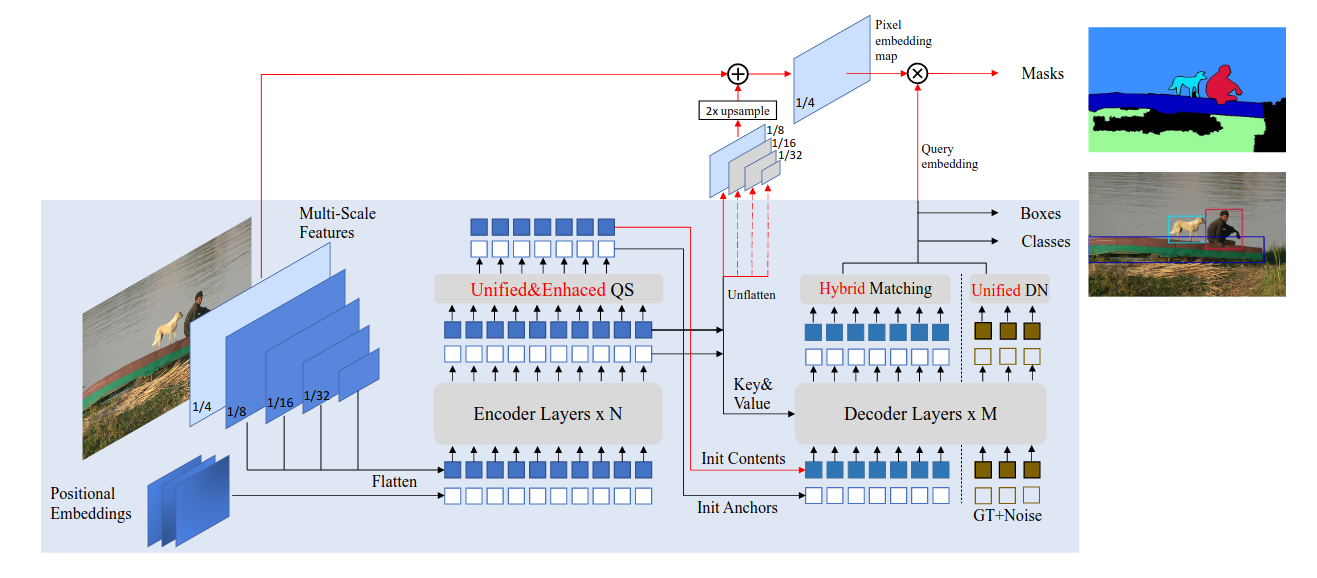
Posted 2025-03-06Updated 2026-03-23Reviewa few seconds read (About 26 words)MaskDINO注:此DINO并非自蒸馏自监督的那个[[DINO]],而是派生自[[DETR]]#Research-paperTransformerCVObject-DetectionSemanticSegmentationMultiModal
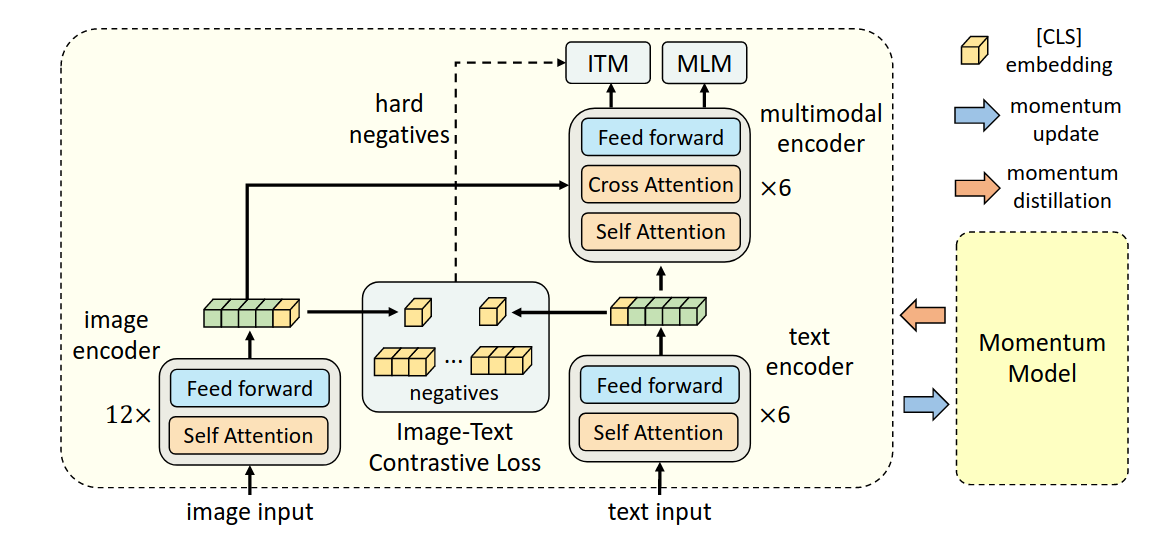
Posted 2025-03-04Updated 2026-03-23Reviewa minute read (About 154 words)ALBEF使用的backbone是BERT(通过MLM训练)该研究认为,image encoder的模型大小应该大于text encoder,所以在text encoder这里,只使用六层self attention来提取特征,剩余六层cross attention用于multi-modal encoder。#Research-paperImage2TextCVContrastive-LearningMultiModalVLPImage-Text
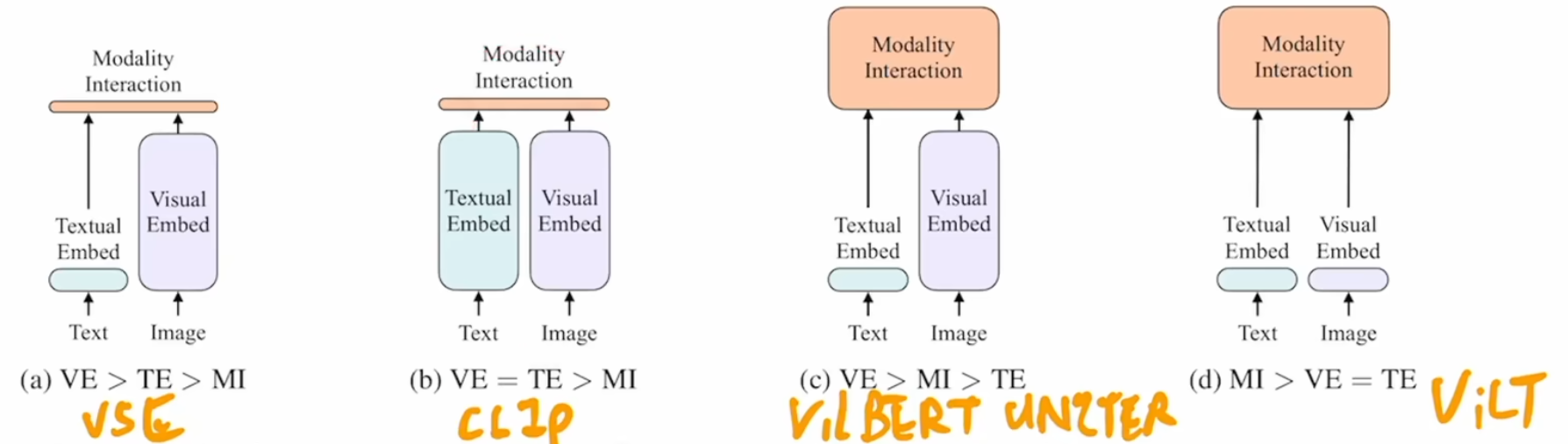
Posted 2025-03-04Updated 2026-03-23Reviewa few seconds read (About 3 words)ViLT#Research-paperTransformerImage2TextCVMultiModalVLPImage-Text
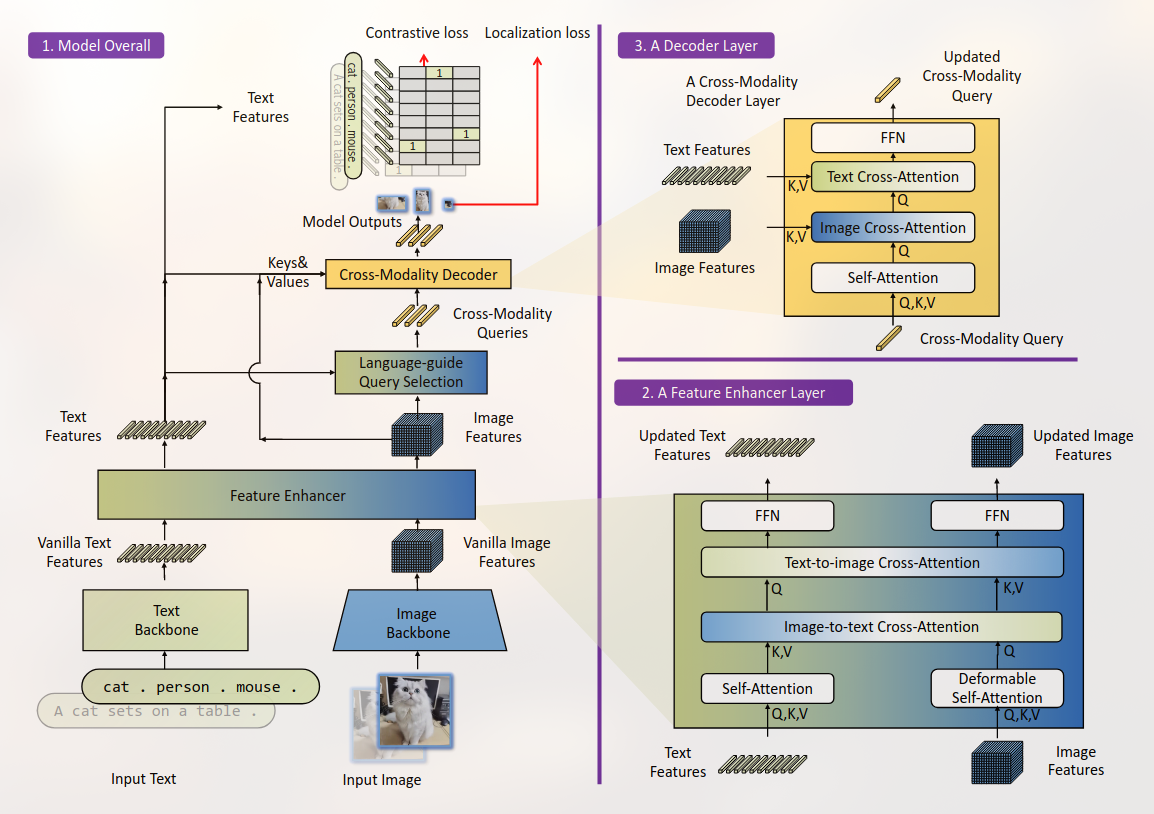
Posted 2025-02-16Updated 2026-03-23Reviewa minute read (About 216 words)Grounding-DINO,#Research-paperTransformerCVObject-DetectionOpen-VocabularyContrastive-LearningMultiModalDINOImage-Grounding
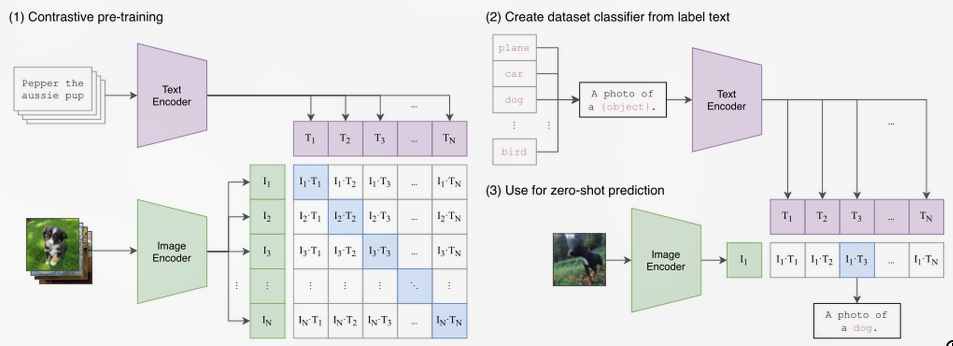
Posted 2025-01-06Updated 2026-03-23Notea minute read (About 197 words)CLIPhttps://blog.csdn.net/h661975/article/details/135116957#Research-paperImage2TextCVCLIPContrastive-LearningMultiModalVLPImage-Text