目前有许多single-streamd 框架,但是单流架构经常受到跨模式干扰,限制了可扩展性和鲁棒性。即使目标经过精心调整,新引入的模式也可能会破坏现有的表示形式,这凸显了在扩展到新领域的同时保留特定模式能力的挑战。

目前有许多single-streamd 框架,但是单流架构经常受到跨模式干扰,限制了可扩展性和鲁棒性。即使目标经过精心调整,新引入的模式也可能会破坏现有的表示形式,这凸显了在扩展到新领域的同时保留特定模式能力的挑战。
3D-Scene
Atlas
CLIP
CV
Chemistry
Contrastive-Learning
DINO
DT
Diffusion
DiffusionModel
Embodied-AI
FL
FPN
FoundationModel
Gated-NN
HRI
Hierarchical
HumanoidRobot
Image-Grounding
Image-Text
Image-generation
Image2Text
ImgGen
ImitationLearning
LLM
LatentAction
ML
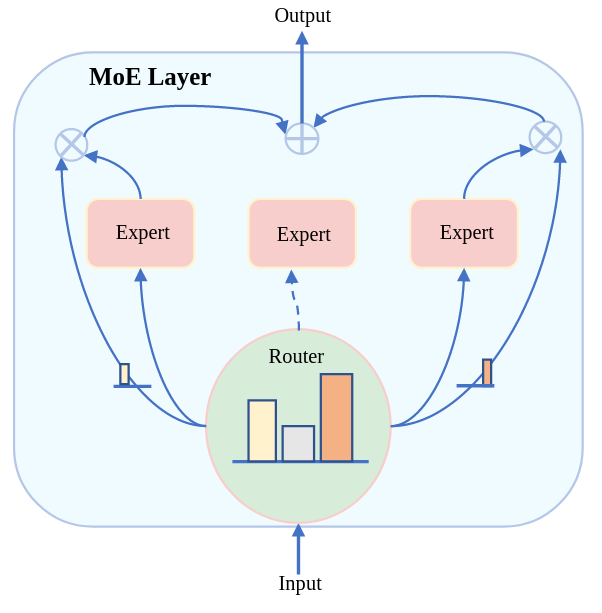
MoE
MR/AR
Message-Passing
Multi-modal
Multi-view
MultiModal
NLP
NN
Object-Detection
Open-Vocabulary
Panoptic
Physical-Scene
PoseEstimation
QML
Quantum
RL
RNN
Real2Sim
Reconstruct
Representation-Learning
RobotLearning
Robotics
Scalability
Scene-graph
Scene-synthesis
Segmentation
Semantic
Sim2Real
Subgraph
Survey
Task-Planning
Transformer
Translation-Embedding
VAE
VLA
VLM
VLP
VQ-VAE
ViT
Visual-Relation
WorldModel
Unified-Multimodal
论文链接 | GitHub | Checkpoints
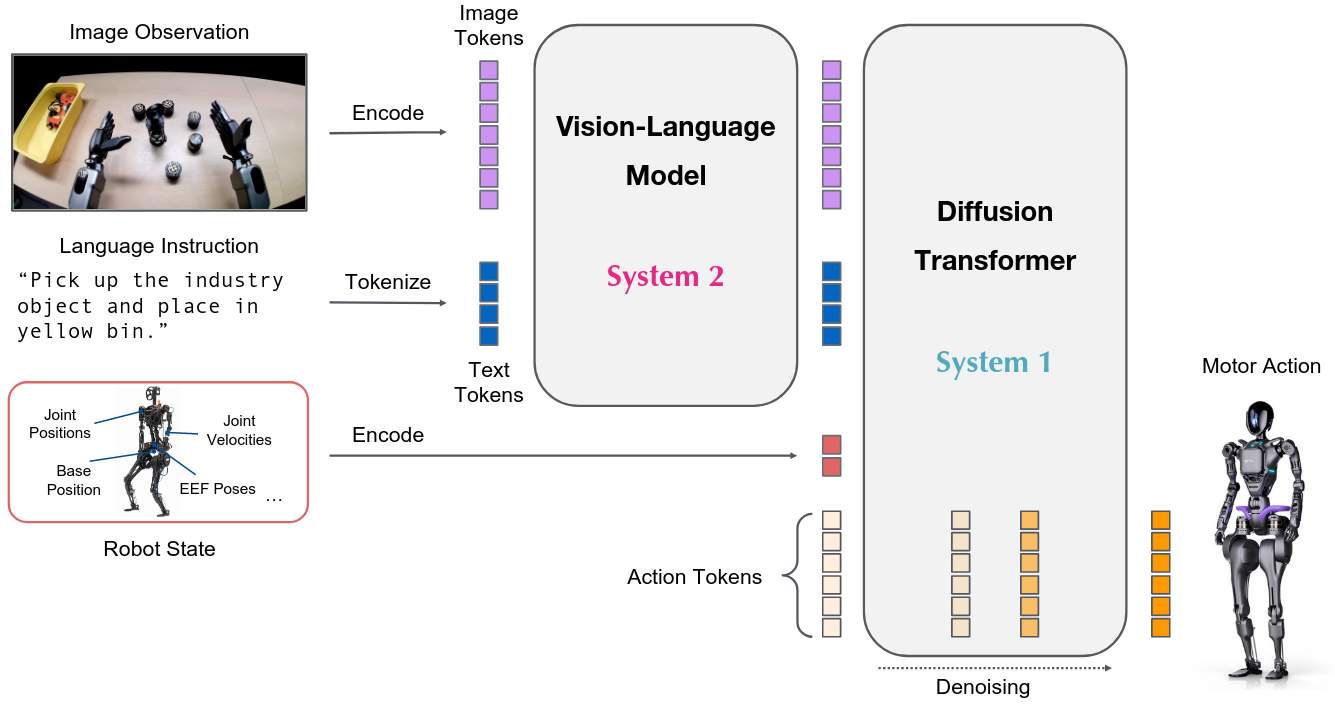
视觉-语言-动作(Vision-Language-Action, VLA)基础模型是机器人操作领域的新兴方法,通过大规模预训练使机器人能够执行由自然语言指令引导的多样化操作任务。然而,目前存在以下问题:
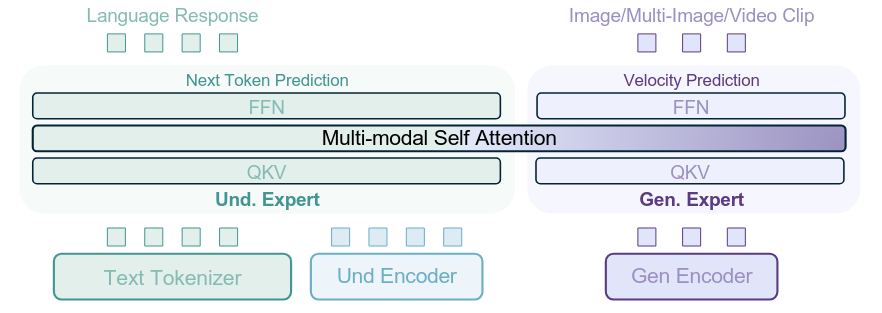
将预训练的视觉语言模型(VLM)与动作生成模块(Action Expert)结合,通过共享自注意力机制实现跨模态统一建模。视觉-语言和动作模态通过独立的 Transformer 路径处理,既保留 VLM 的语义先验,又避免跨模态干扰。
一种用于连续动作建模的生成方法,通过学习从噪声到目标动作的向量场来生成平滑的机器人控制信号。
将序列划分为图像-指令块、状态块和动作块,应用因果掩码防止信息泄露,确保动作预测只能访问当前和历史观测信息。
LingBot-VLA 采用 MoT 架构,整合 Qwen2.5-VL 作为视觉语言骨干网络,配合独立的 Action Expert 模块:
联合建模序列:
$$[O_t, A_t] = [I_t^1, I_t^2, I_t^3, T_t, s_t, a_t, a_{t+1}, \ldots, a_{t+T-1}]$$
其中 $I_t^{1,2,3}$ 为三视角图像,$T_t$ 为任务指令,$s_t$ 为机器人状态,$A_t$ 为动作序列(chunk length = 50)。
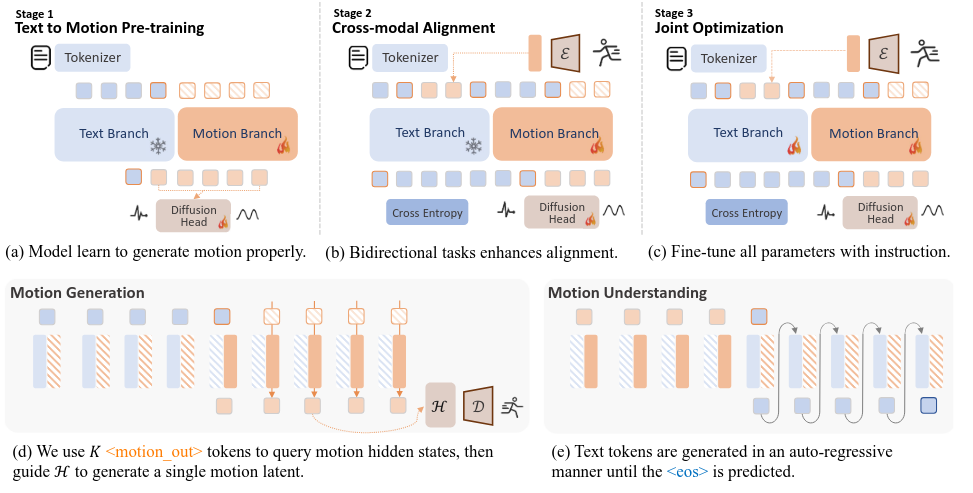
类似[[BAGEL-Unified-Multimodal-Pretraining]]
定义概率路径通过线性插值:
$$A_{t,s} = sA_t + (1-s)\epsilon, \quad \epsilon \sim \mathcal{N}(0, I)$$
训练目标:
$$\mathcal{L}{FM} = \mathbb{E}{s \sim U[0,1], A_t, \epsilon}|v_\theta(A_{t,s}, O_t, s) - (A_t - \epsilon)|^2$$
通过可学习查询 $Q_t$ 与 LingBot-Depth 模型的深度 token $D_t$ 对齐,增强空间感知:
$$\mathcal{L}{distill} = \mathbb{E}{Q_t}|Proj(Q_t) - D_t|$$
| 方法 | 平均成功率(SR) | 平均进度分(PS) |
|---|---|---|
| WALL-OSS | 4.05% | 10.35% |
| GR00T N1.6 | 7.59% | 15.99% |
| π0.5 | 13.02% | 27.65% |
| LingBot-VLA w/o depth | 15.74% | 33.69% |
| LingBot-VLA w/ depth | 17.30% | 35.41% |
| 方法 | Clean 场景 SR | Randomized 场景 SR |
|---|---|---|
| π0.5 | 82.74% | 76.76% |
| LingBot-VLA w/o depth | 86.50% | 85.34% |
| LingBot-VLA w/ depth | 88.56% | 86.68% |


ChemGPT 早期基座模型基于 EleutherAI 的语言模型 GPT‑Neo,在分子字符串语料(SMILES 或 SELFIES)上进行自回归建模。
典型预训练数据集为公开的大规模分子库 PubChem10M,参数规模覆盖百万到十亿级别(如约 4.7M 的轻量版本或 100M+ 的科研版本)。
属于领域特化的 decoder-only 化学语言模型。