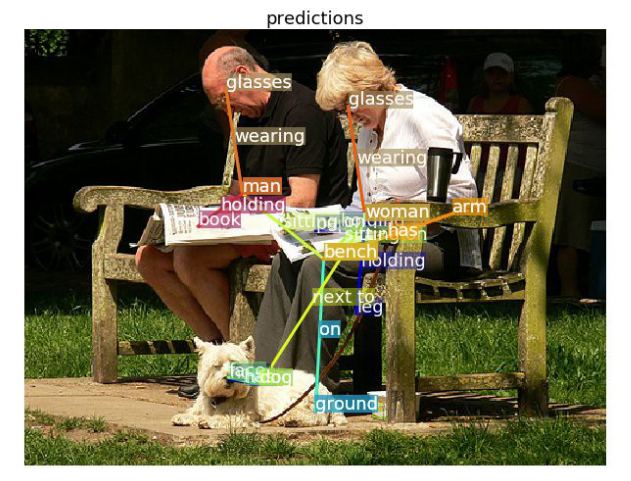
Image Retrieval using Scene Graphs
Building an efficient structured representation that captures comprehensive semantic knowledge is a crucial step towards a deeper understanding of visual scenes

Image Retrieval using Scene Graphs
Building an efficient structured representation that captures comprehensive semantic knowledge is a crucial step towards a deeper understanding of visual scenes
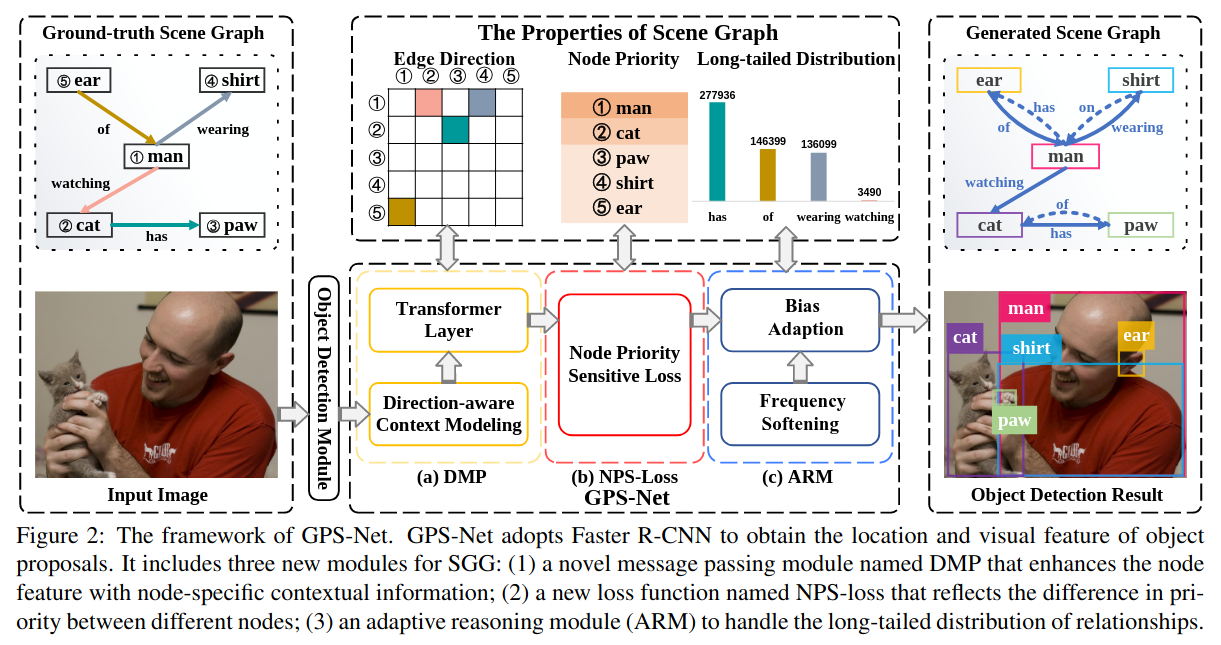
SGTR+= End-to-end Scene Graph Generation with Transformer
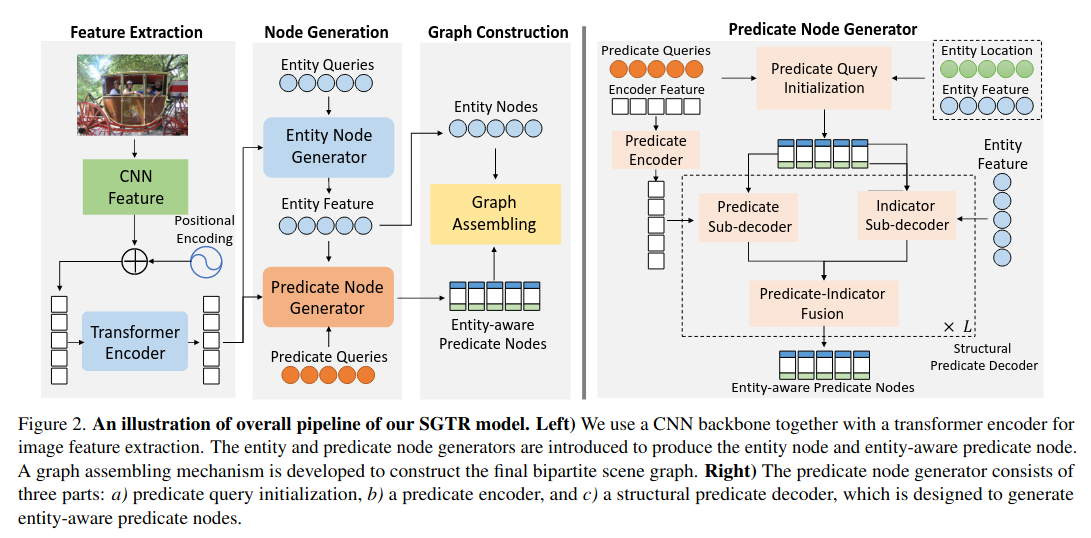
SGTR 是一种自上而下的方法,该方法首先使用基于Transformer的生成器来生成一组可学习的triplet queries (subject–predicate–object),然后使用级联的triplet detector逐步完善这些查询并生成最终场景图。它还提出了一种基于结构化发生器的实体感知关系表示方法,该方法利用了关系的组成属性。
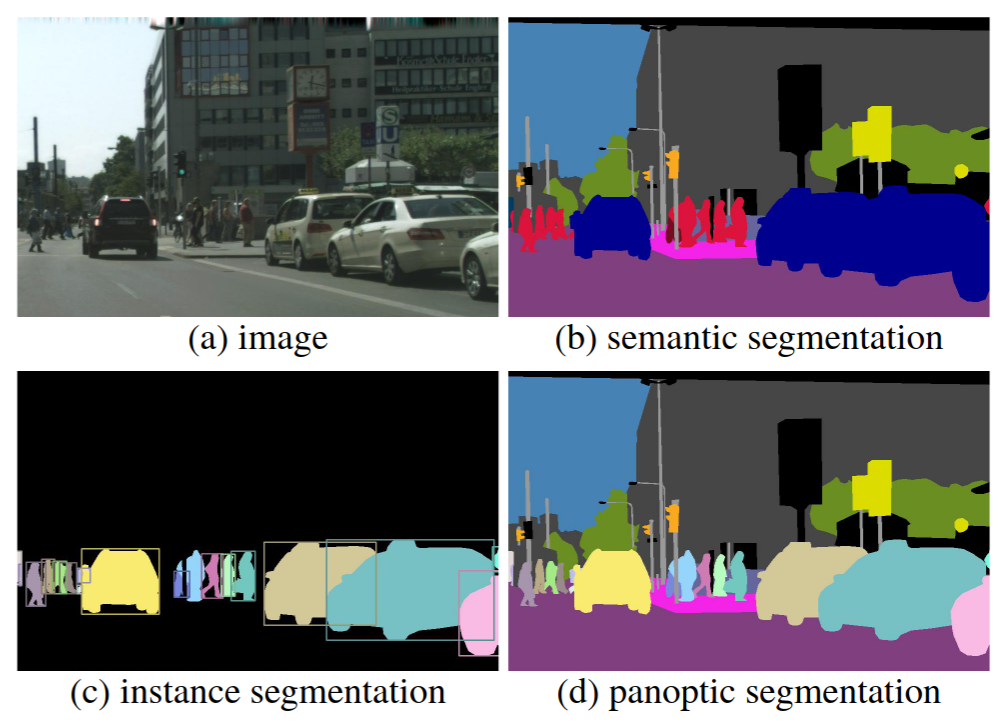
Scene Graph Generation- A comprehensive survey
See [[Reconstruct-Anything Literature Review]]
SceneGraphFusion- Incremental 3D Scene Graph Predictionfrom RGB-D Sequences
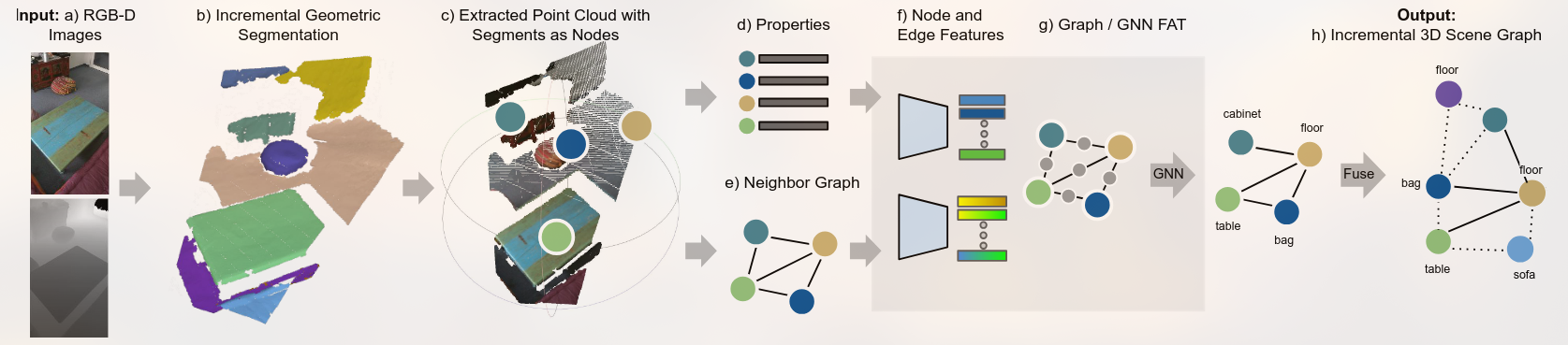
Overview of the proposed SceneGraphFusion framework. Our method takes a stream of RGB-D images a) as input to create an incremental geometric segmentation b). Then, the properties of each segment and a neighbor graph between segments are constructed. The properties d) and neighbor graph e) of the segments that have been updated in the current frame c) are used as the inputs to compute node and edge features f) and to predict a 3D scene graph g). Finally, the predictions are h) fused back into a globally consistent 3D graph.