
Simple Open-Vocabulary Object Detection with Vision Transformers

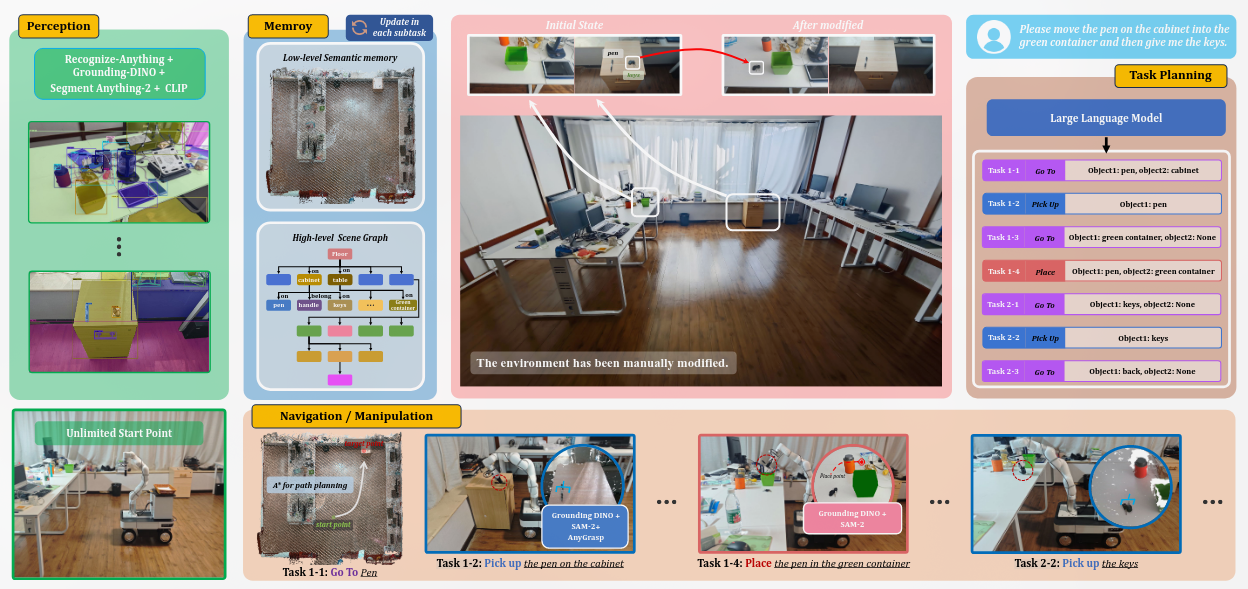
OK-Robot- What Really Matters in Integrating Open-Knowledge Models for Robotics

Creating a general-purpose robot has been a longstanding dream of the robotics community.
当前想要实现这一目标的系统脆弱、封闭,并且在遇到未见过的情况时会失败。即使是最大的机器人模型通常也只能部署在以前见过的环境中 [5, 6]。在机器人数据很少的环境中,例如在非结构化的家庭环境中,这些系统的脆弱性会进一步加剧。
虽然大型视觉模型显示出语义理解 、检测以及将视觉表示与语言联系起来的能力并且与此同时,机器人的导航、抓取和重新排列等基本机器人技能已经相当成熟。
但是将现代视觉模型与机器人特定基元相结合的机器人系统表现非常差。
这可能是因为单纯将多个不确定性的系统组合在一起会导致准确率急剧恶化。
所以我们需要一个将VLM和机器人primitives(导航,抓取,放置)结合在一起的细致框架,即OK-Robot。
Pick up A (from B) and drop it on/in C”, where A is an object and B and C are places in a real-world environment such as homes
负责空间重建,识别物体大致位置,机器人导航
用到的方法:



A Survey of Imitation Learning- Algorithms, Recent Developments, and Challenges
IL是区别于传统手动编程来赋予机器人自主能力的方法。
IL 允许机器通过演示(人类演示专家行为)来学习所需的行为,从而消除了对显式编程或特定于任务的奖励函数的需要。
IL主要有两个类别:

BC 是一种 IL 技术,它将学习行为的问题视为监督学习任务 。 BC 涉及通过建立环境状态与相应专家操作之间的映射来训练模型来复制专家的行为。专家的行为被记录为一组state-action pair,也称为演示。在训练过程中,模型学习一个函数,利用这些演示作为输入,将当前状态转换为相应的专家操作。经过训练,模型可以利用这个学习函数来生成遇到新状态的动作。
不需要了解环境的潜在动态,计算效率很高,相对简单的方法。
The covariate shift problem: 测试期间观察到的状态分布可能与训练期间观察到的状态分布有所不同,使得代理在遇到未见过的状态时容易出错,而对于如何进行操作缺乏明确的指导。BC监督方法的问题是,当智能体漂移并遇到分布外状态时,它不知道如何返回到演示的状态。
为了解决这个问题:

IRL 涉及一个学徒代理,其任务是推断观察到的演示背后的奖励函数,这些演示被认为源自表现最佳的专家 。然后使用推断的奖励函数通过 RL 训练学习代理的策略。
为了解决“政策->奖励函数“的模糊性,有以下三种IRL
The agent strives to deceive the discriminator by generating trajectories closely resembling those of the expert.
仅通过图像序列来学习,不需要具体的关节动作操作数据。
Unlike the traditional methods, IfO presents a more organic approach to learning from experts, mirroring how humans and animals approach imitation. Humans often learn new behaviors by observing others without detailed knowledge of their actions (e.g., the muscle commands). People learn a diverse range of tasks, from weaving to swimming to playing games, by watching online videos. Despite differences in body shapes, sensory inputs, and timing, humans exhibit an impressive ability to apply knowledge gained from the online demonstrations
将可学习的资源扩大到了线上的视频资源。
过分析观察到的动态,LAPO 推断出行动空间的底层结构,促进潜在行动策略的训练。然后,这些策略可以进行高效的微调,以达到专家级的性能,从而提供离线和在线场景的适应性。使用包含标记动作的小数据集进行离线微调是可行的,而在线微调可以使用奖励来完成。与依赖标记数据来训练逆动力学模型不同,LAPO直接从观察到的环境动态中导出潜在动作信息,而不需要任何标签。
。。。
Dynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
和我的想法非常相近,完成度也很高啊喂。可以参考他的实现思路,引用的文章等等。
ACDC- Automated Creation of Digital Cousins for Robust Policy Learning
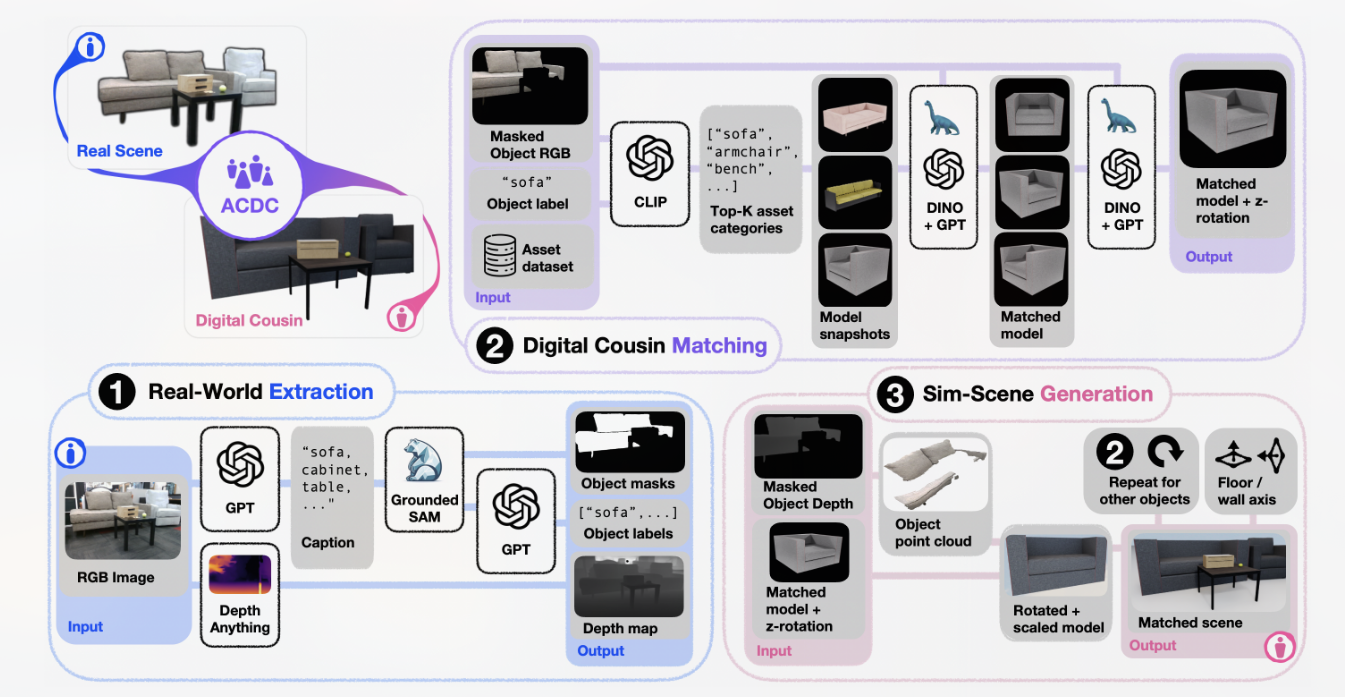
数字孪生(DT)作为现实世界非常精确的映射虽然可以用于高精度的训练但是生产DT资产过于繁琐且没有泛化性,不能做到zero-shot。
数字表亲(DC)通过比对模型特征,从模型库中选择类似的表亲模型,用于重建场景训练机械臂。让机械臂针对不同第一次见的场景具有泛化性。
(a)它减少了手动微调的需要,以保证一定的保真度,从而能够完全自动化地创建数字表亲,(b)它通过提供一组增强的场景来训练机器人策略,从而有助于更好地应对原始场景中的变化。
ACDC is our automated pipeline for generating fully interactive simulated scenes from a single RGB image, and is broken down into three steps:
(1) an extraction step, in which relevant object masks are extracted from the raw input image
(2) a matching step, in which we select digital cousins for individual objects extracted from the original scene
(3) a generation step, in which the selected digital cousins are post-processed and compiled together to form a fully-interactive, physically-plausible digital cousin scene.
CosyPose-- Consistent multi-view multi-object 6D pose estimation
Estimate accurate 6D poses of multiple known objects in a 3D scene captured by multiple cameras with unknown positions


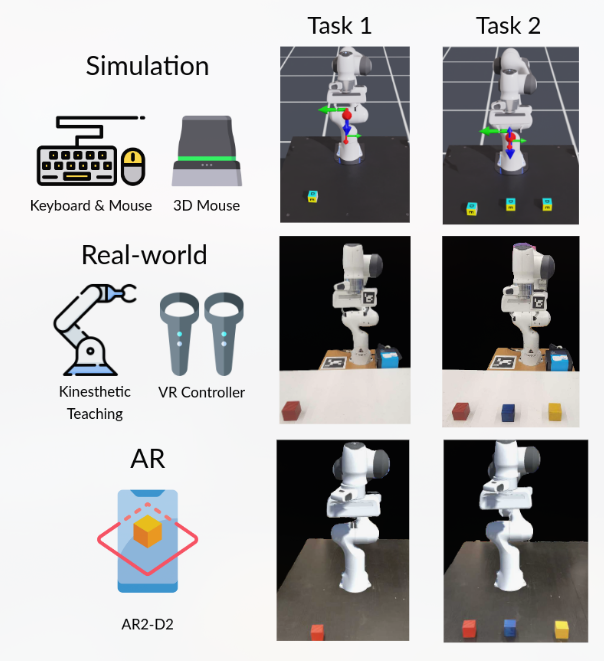
AR2-D2 -- Training a Robot Without a Robot
机器人执行任务的视频数据集非常重要,特别是对于Visual Imitation Learning来说。
想要获得这些训练集视频,传统的方法是人工引导机器人做相关动作,然后再录制,耗费大量人力和时间成本,最关键的是机器人是固定在实验室内的,能接触到的物品和任务比较有限,因此这些训练数据中不包含更日常的场景。
提出了一个IOS APP,可以通过追踪用户手部的动作在视频中生成一个执行动作的AR机器人。
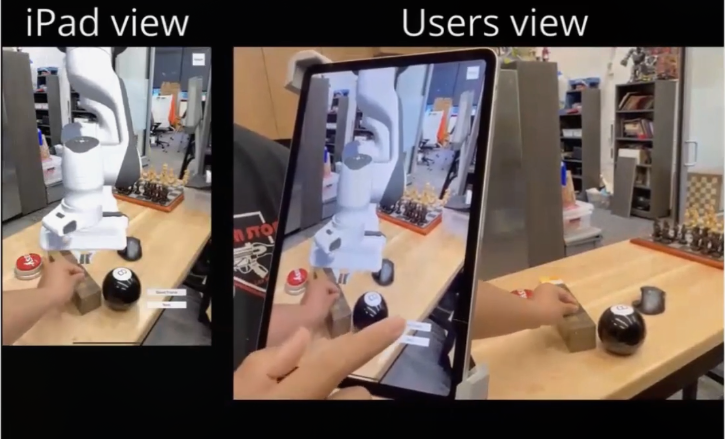
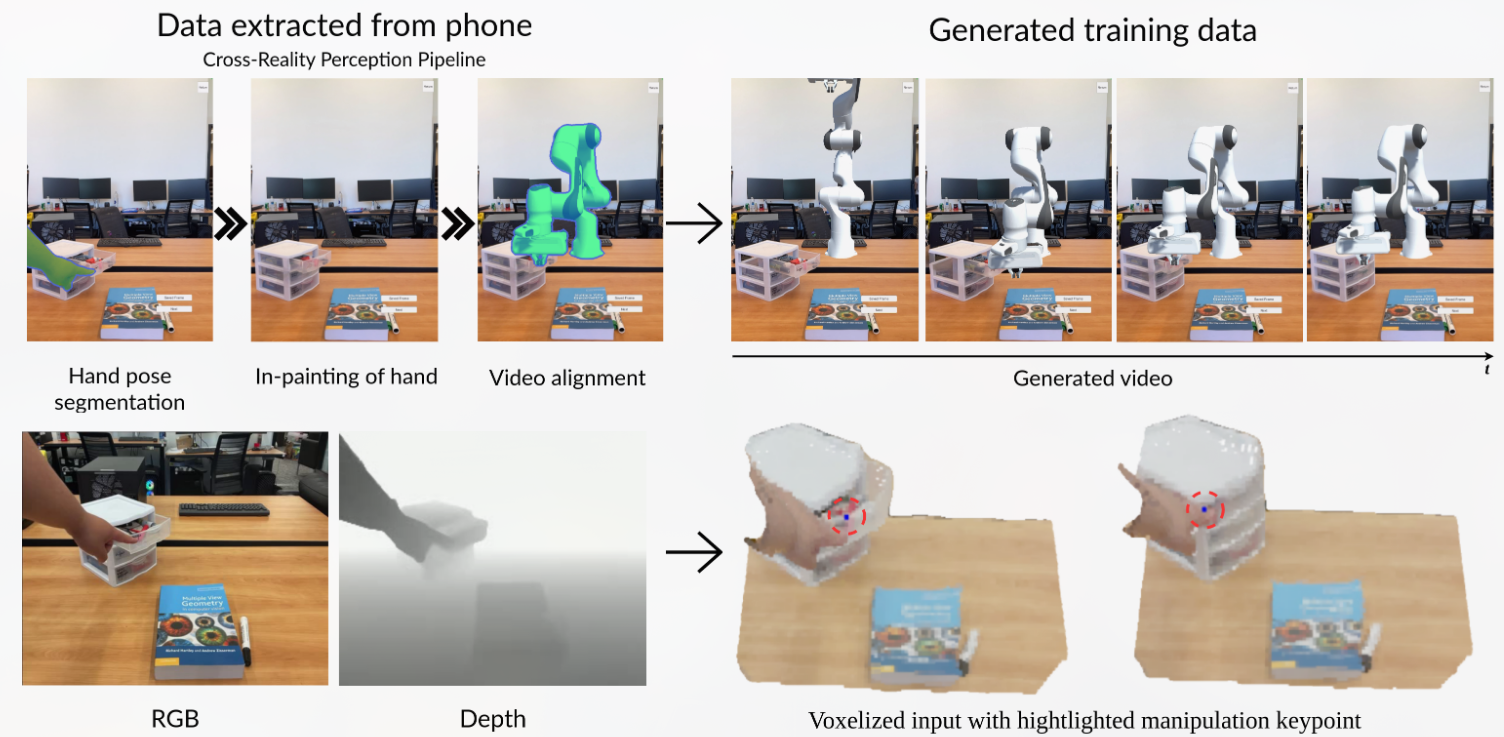
如上图,AR2-D2 的设计和实现由两个主要组件组成。第一个组件是一个手机应用程序,它将 AR 机器人投射到现实世界中,允许用户与物理对象和 AR 机器人进行交互。第二个组件将收集的视频转换为可用于训练不同行为克隆代理的格式,这些克隆代理随后可以部署在真实的机器人上。
Unity + AR Foundation kit(用于生成一个虚拟机械臂并布置在场景中)
传感器:苹果设备摄像头和自带的LiDAR
通过ios自己的人手姿态算法和深度信息获取手部动作,由此获取机械臂需要运动到的关键点,并且可以让AR界面中的机械臂移动到指定位置。
得到APP生成的视频后消除人手并填补消除的区域(E2FGVI),就可以得到机械臂操作物体的视频,它可以用作基于视觉的模仿学习的训练数据。
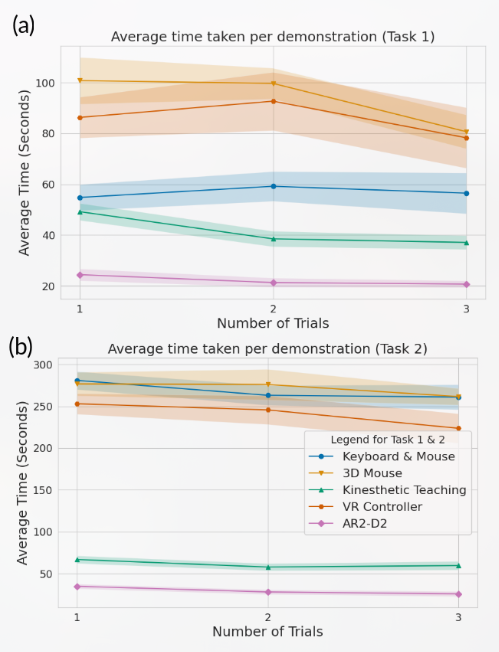
围绕三个常见的机器人任务收集演示:{press, push, pick up}
使用 Perciver-Actor (PERACT)训练基于 Transformer 的语言引导行为cloning policy
PERACT takes a 3D voxel observation and a language goal (v, l) as input and produces discretized outputs for translation, rotation, and gripper state of the end-effector. These outputs, coupled with a motion planner, enable the execution of the task specified by the language goal.
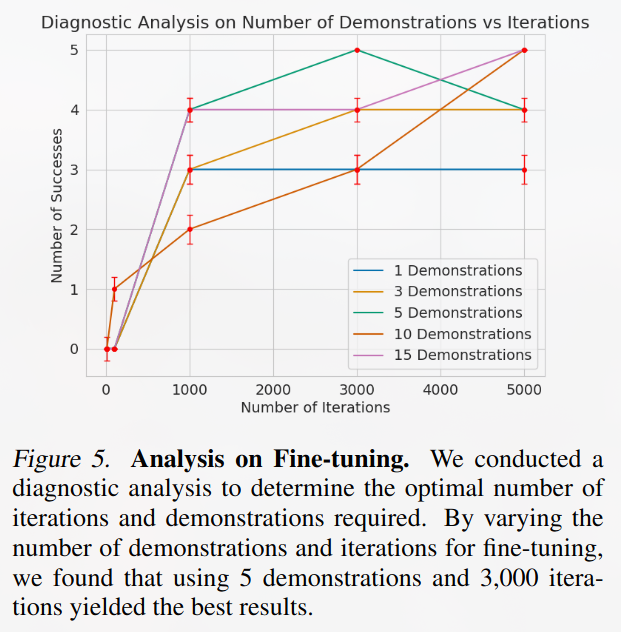
每一个agent执行一种任务({press, push, pick up}),先训练3k次,然后再微调训练(3k iteration),用于缩小iphone摄像机和agent使用的kinect v2相机之间的偏差。
微调结果
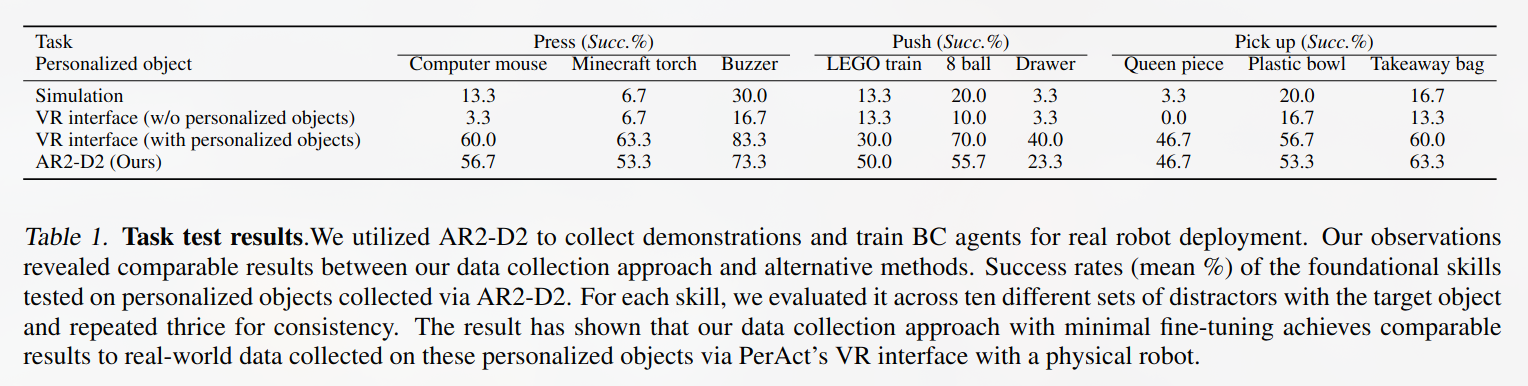
测试结果
Human-robot interaction for robotic manipulator programming in Mixed Reality
和我毕设很像的工作,居然已经发ICRA了?

