Reasoning with Scene Graphs for Robot Planning under Partial Observability


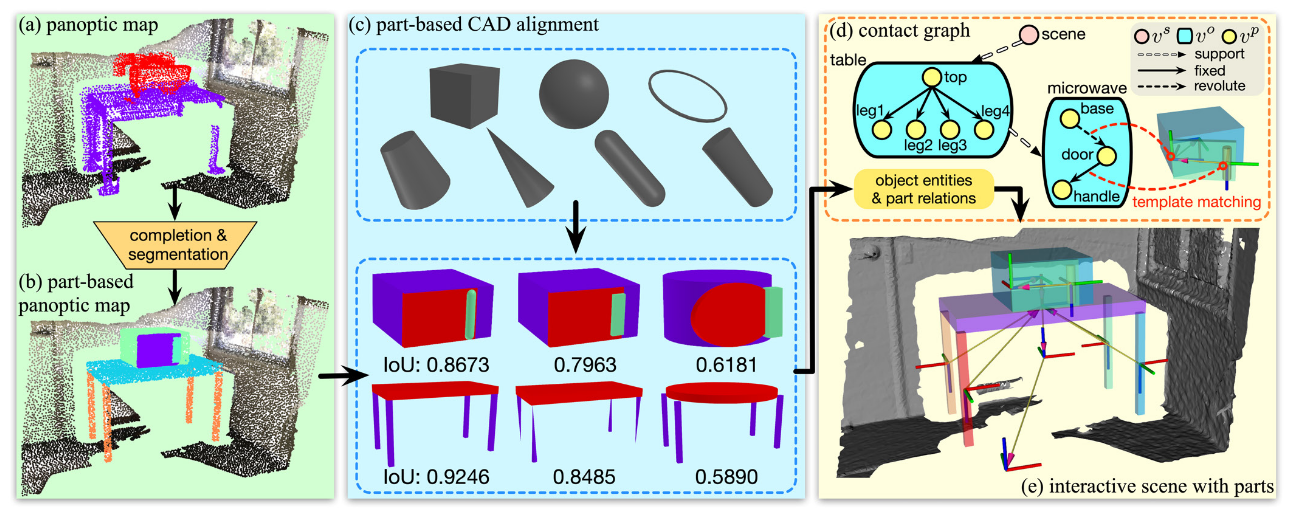
Scene Reconstruction with Functional Objects for Robot Autonomy
和李飞飞[[ACDC- Automated Creation of Digital Cousins for Robust Policy Learning]]的思想类似。

DETR是一个使用transformer作为基本架构的 object detection 模型。

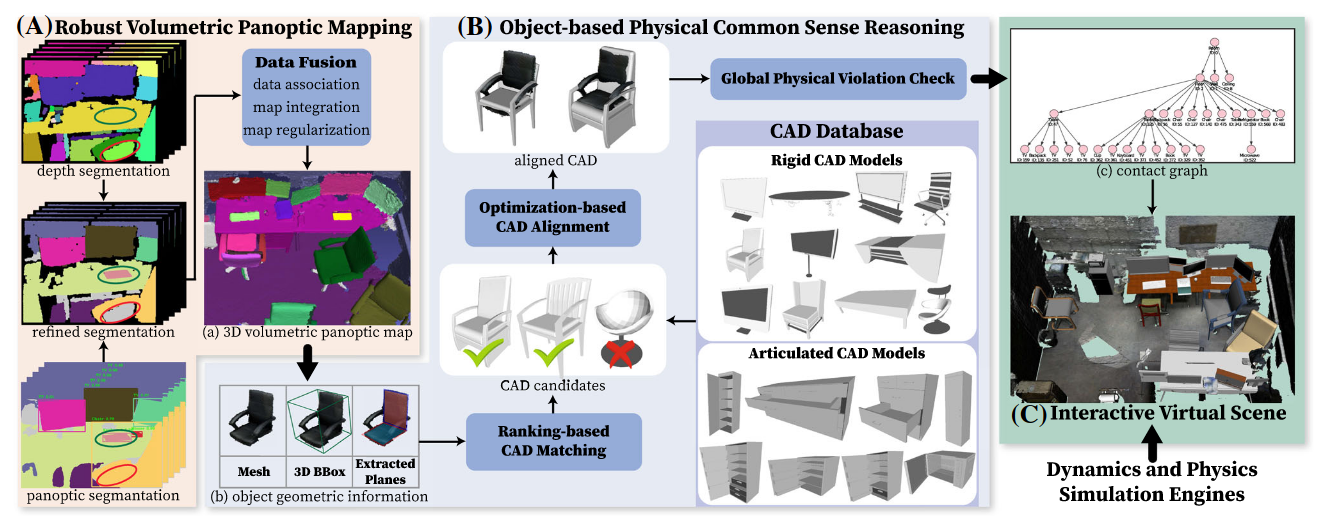
这片文章可以成为场景物理重建的基石之一
类似的后续工作有OMG-Seg
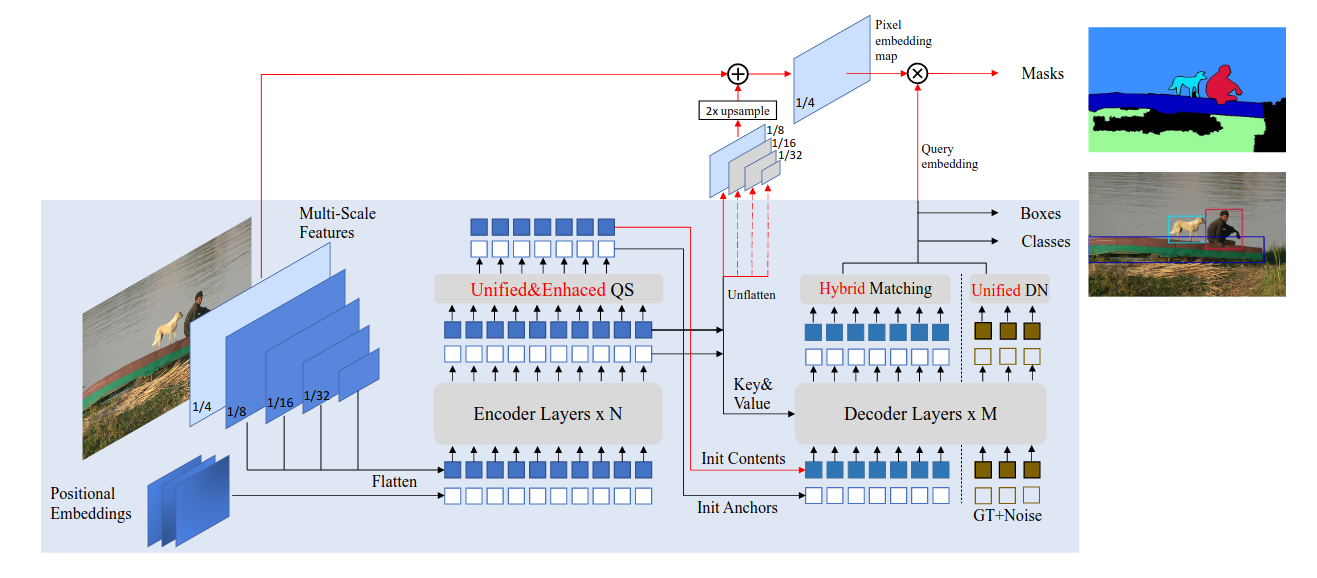
注:此DINO并非自蒸馏自监督的那个[[DINO]],而是派生自[[DETR]]
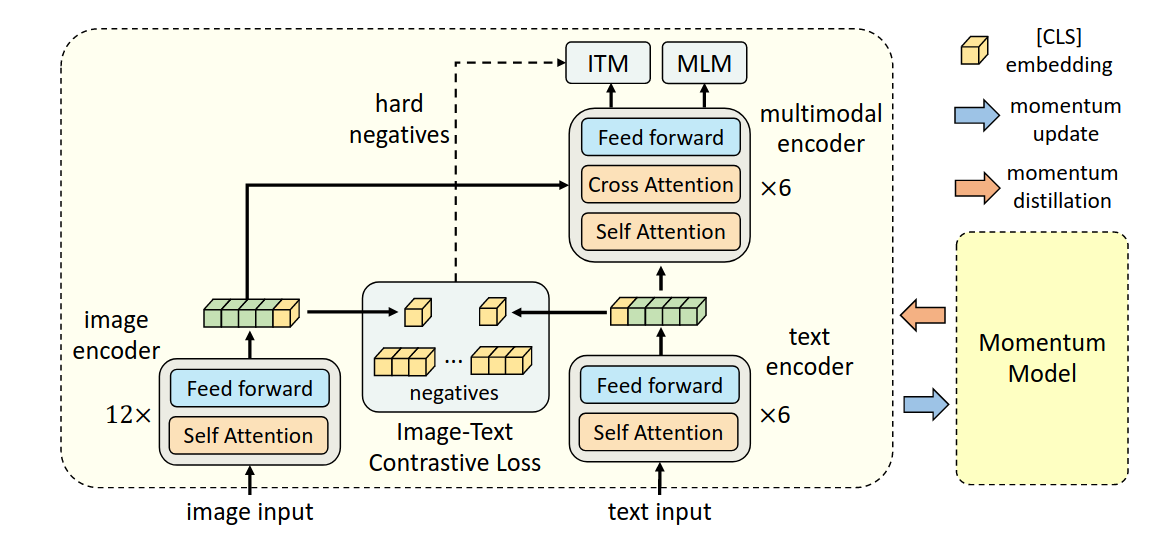
使用的backbone是BERT(通过MLM训练)
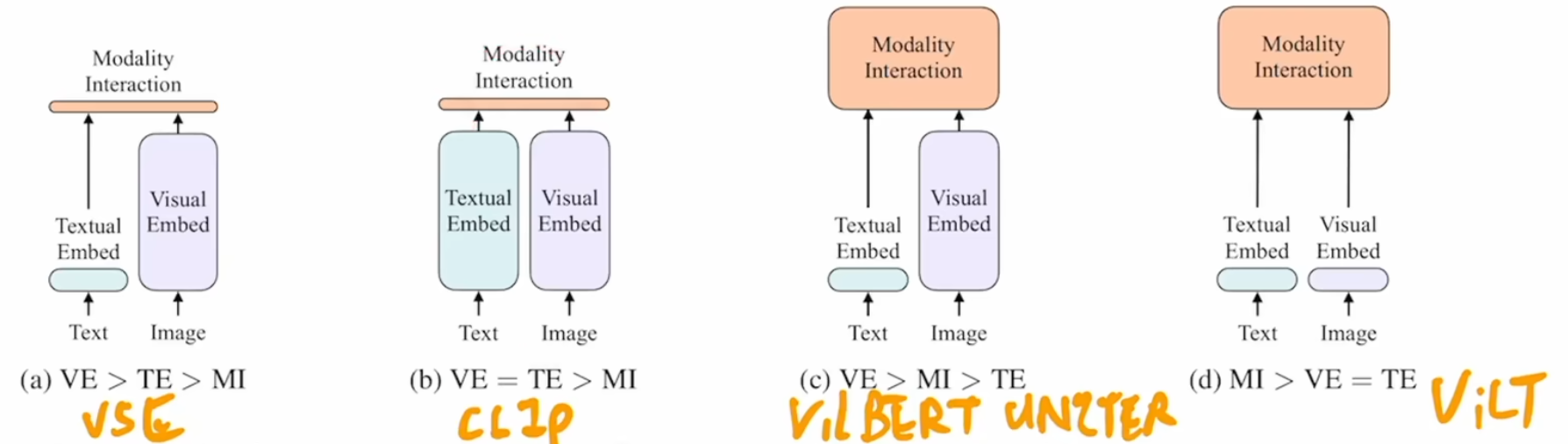
该研究认为,image encoder的模型大小应该大于text encoder,所以在text encoder这里,只使用六层self attention来提取特征,剩余六层cross attention用于multi-modal encoder。