SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
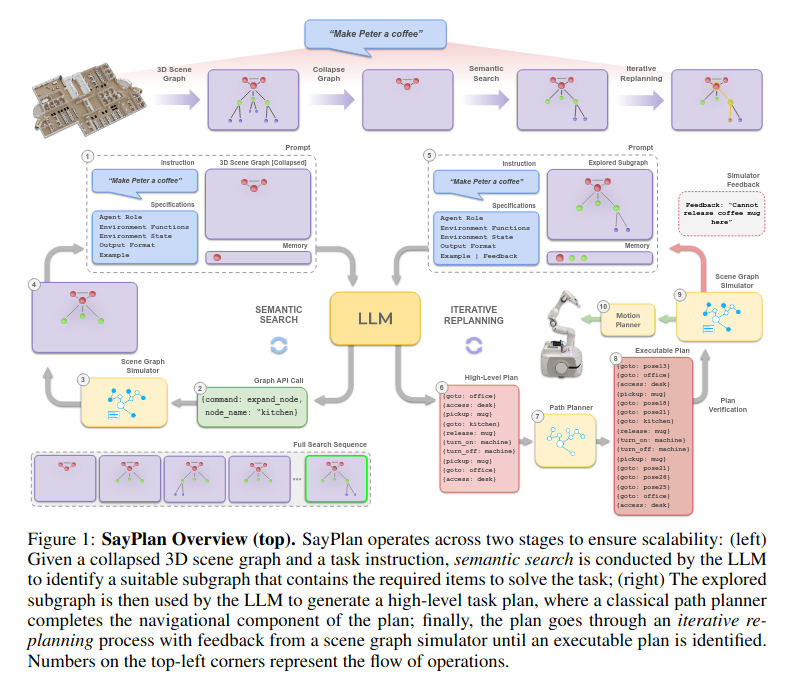
主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。

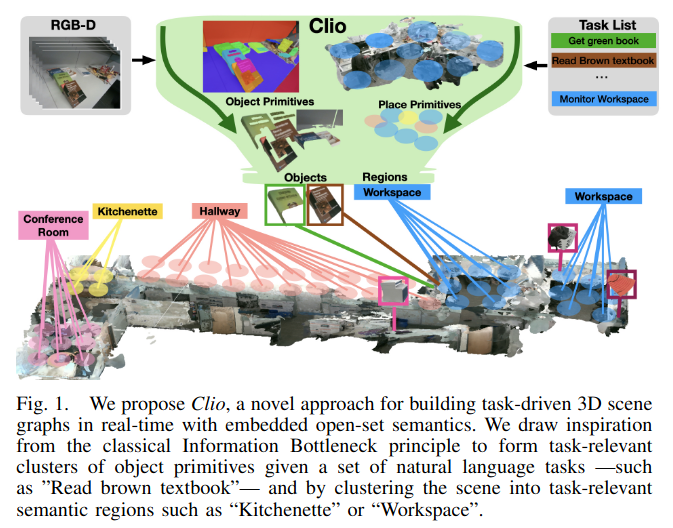
SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。

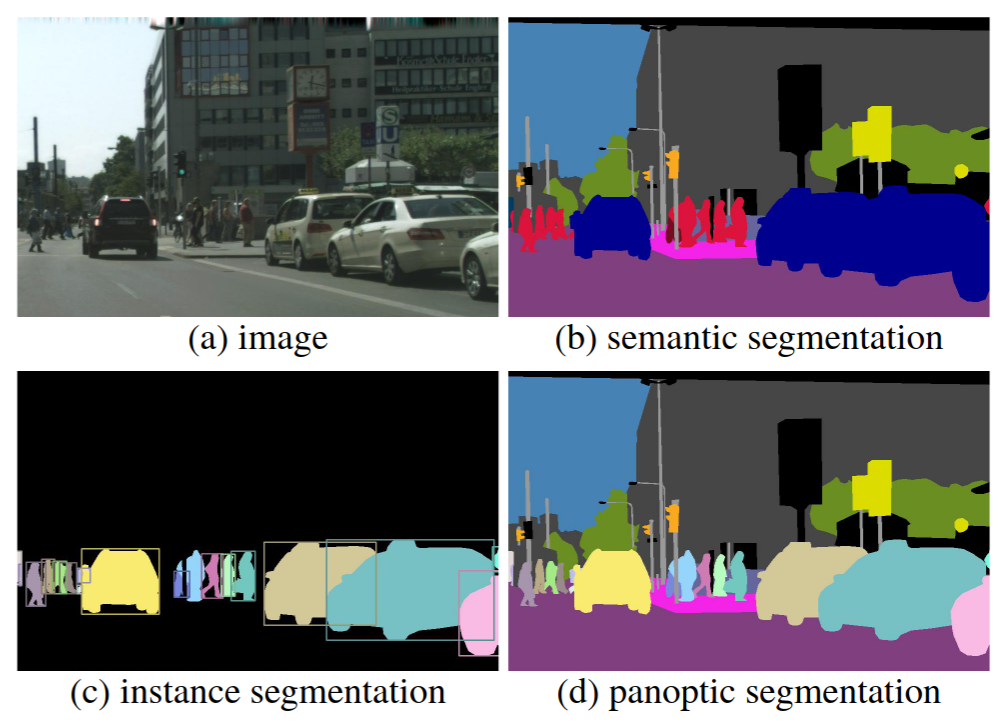
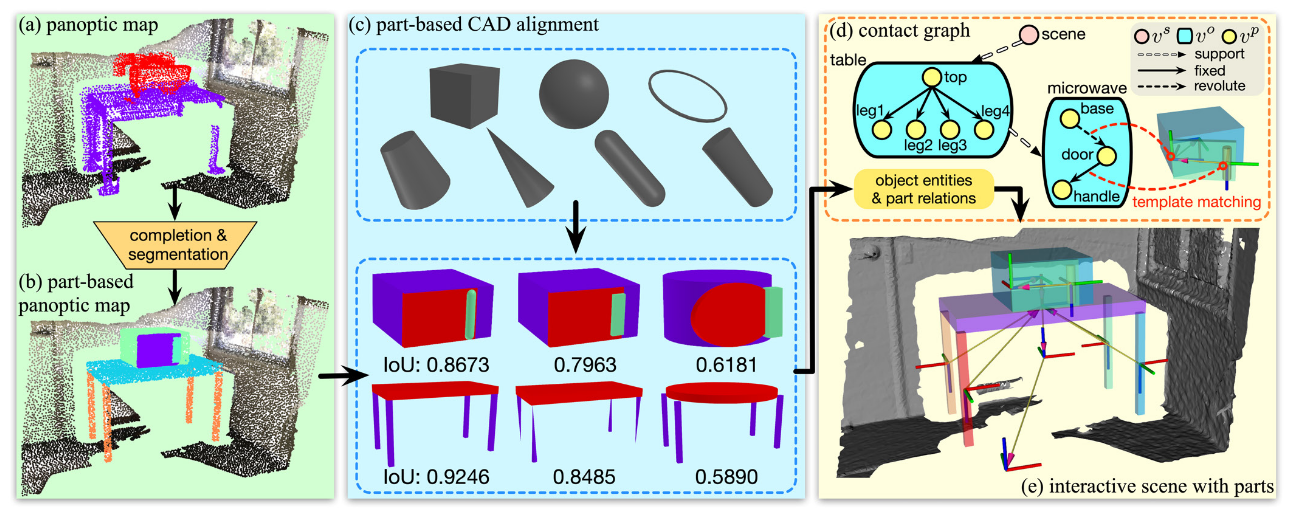
Scene Reconstruction with Functional Objects for Robot Autonomy
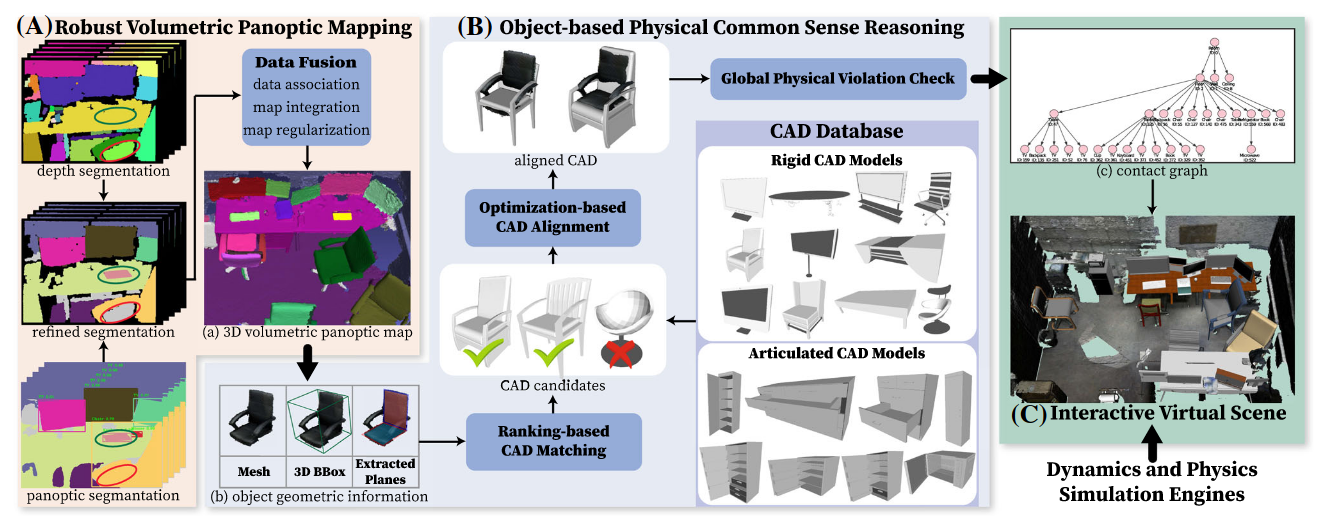
和李飞飞[[ACDC- Automated Creation of Digital Cousins for Robust Policy Learning]]的思想类似。
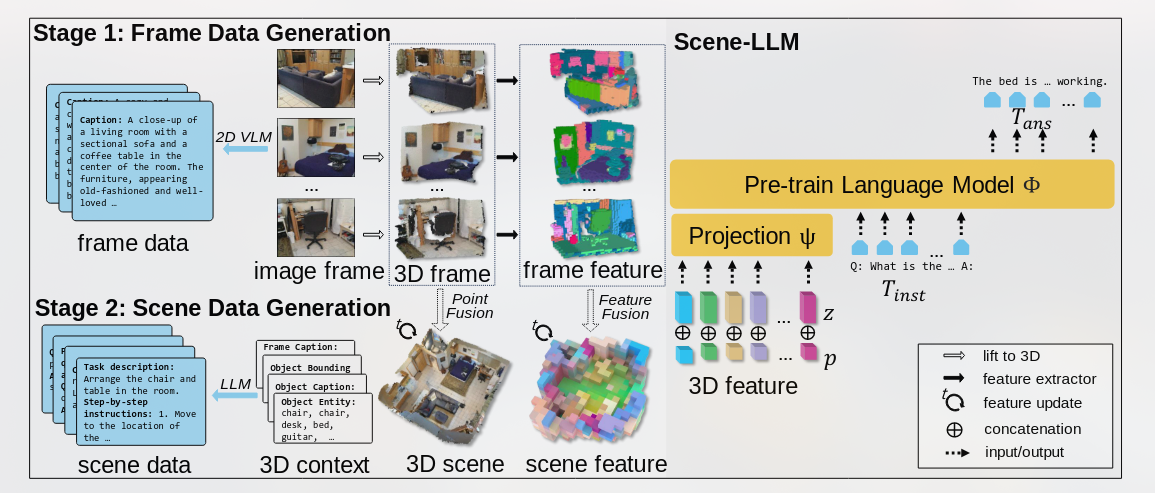
本文提出的模型主要想解决3D密集标注和交互式规划。
结合
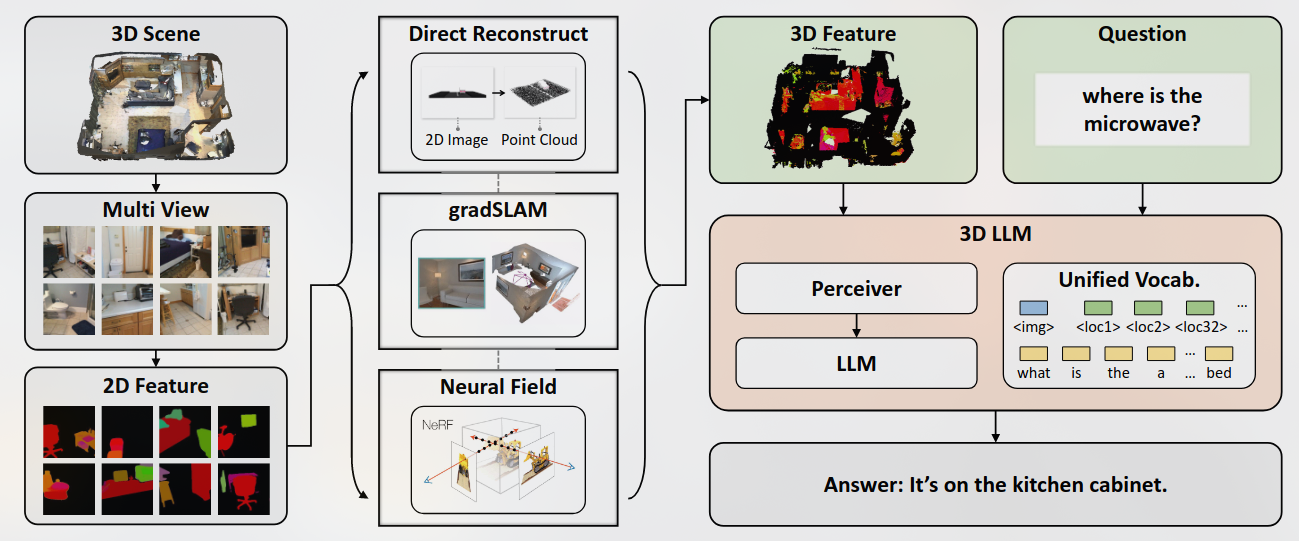
Recent works have explored aligning images and videos with LLM for a new generation of multi-modal LLMs that equip LLMs with the ability to understand and reason about 2D images.
但是仍缺少对于3D物理空间进行分析的模型, which involves richer concepts such as spatial relationships, affordances, physics and interaction so on.