Posted 2026-02-03Updated 2026-03-23Review18 minutes read (About 2709 words)Scalable Diffusion Models with TransformersScalable Diffusion Models with Transformers | ICCV 2023#Research-paperTransformerCVDiffusionModelImgGenScalability
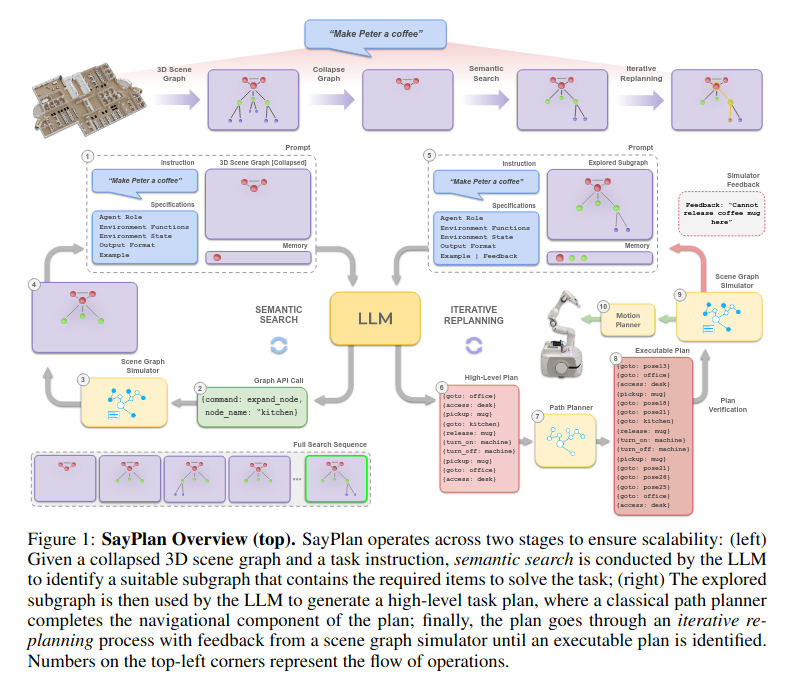
Posted 2025-03-18Updated 2026-03-23Review2 minutes read (About 355 words)SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。#LLMResearch-paperRoboticsScene-graphScalability3D-SceneEmbodied-AITask-Planning