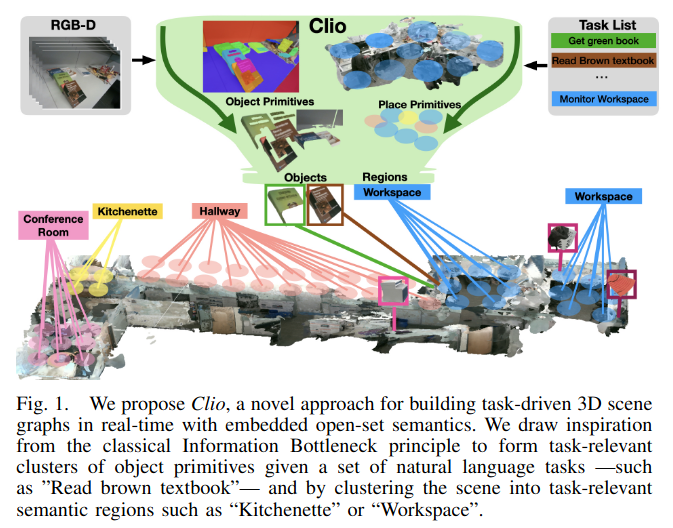
Language Models as Zero-Shot Planners= Extracting Actionable Knowledge for Embodied Agents


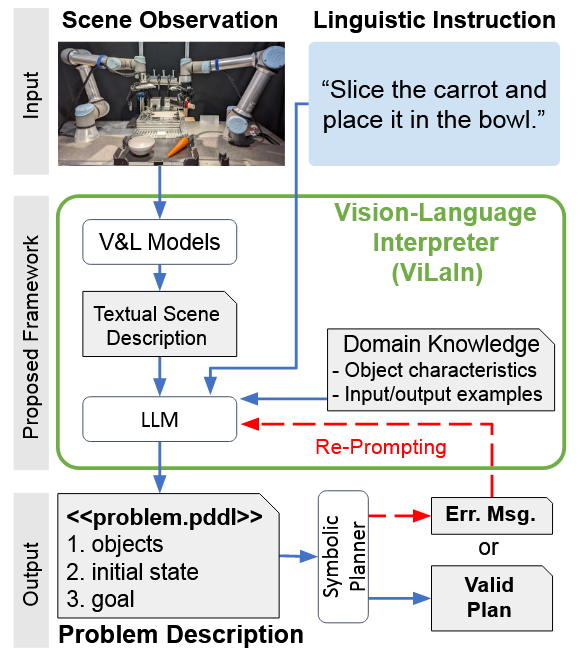
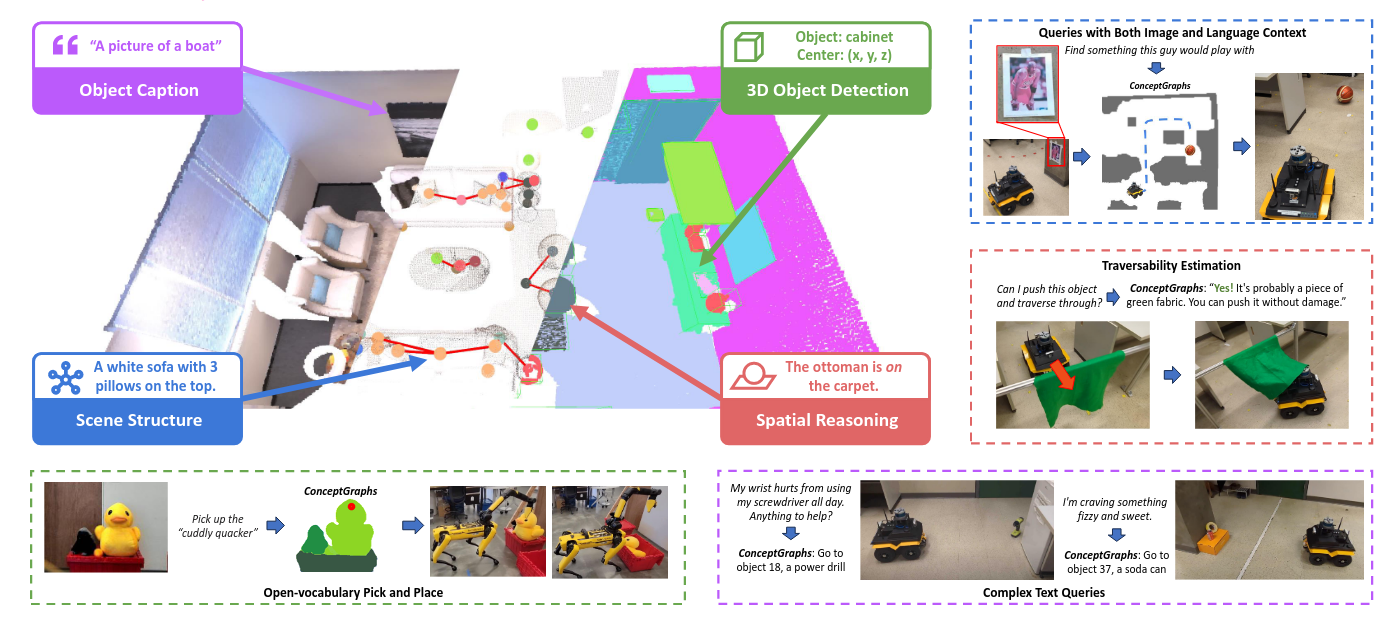
ConceptGraphs= Open-Vocabulary 3D Scene Graphs for Perception and Planning
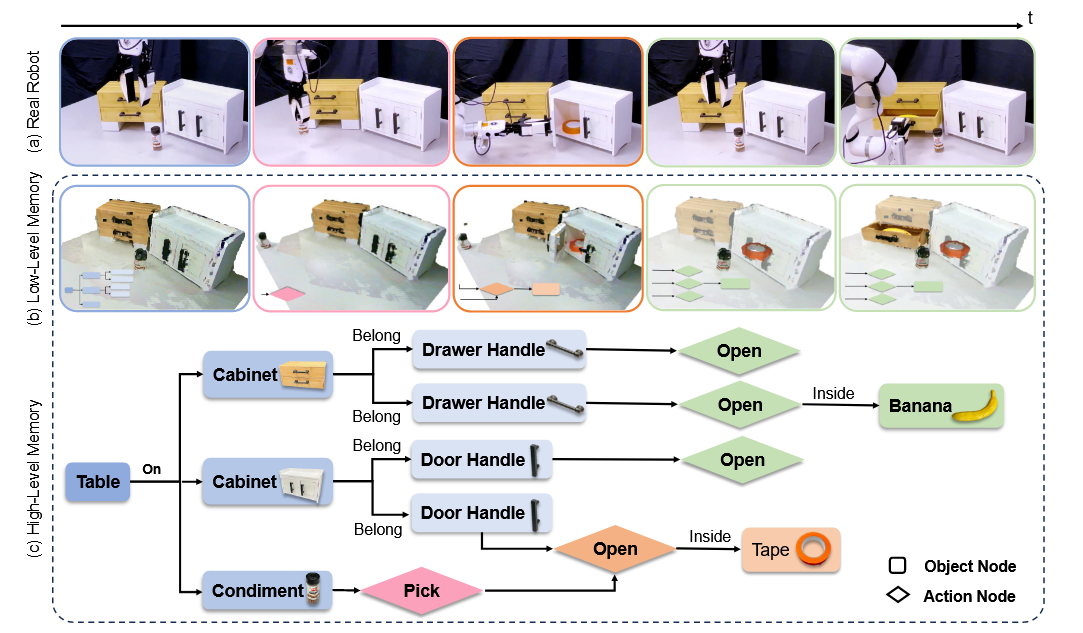
通过LLM来判断位置关系,以此构建scene graph
SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
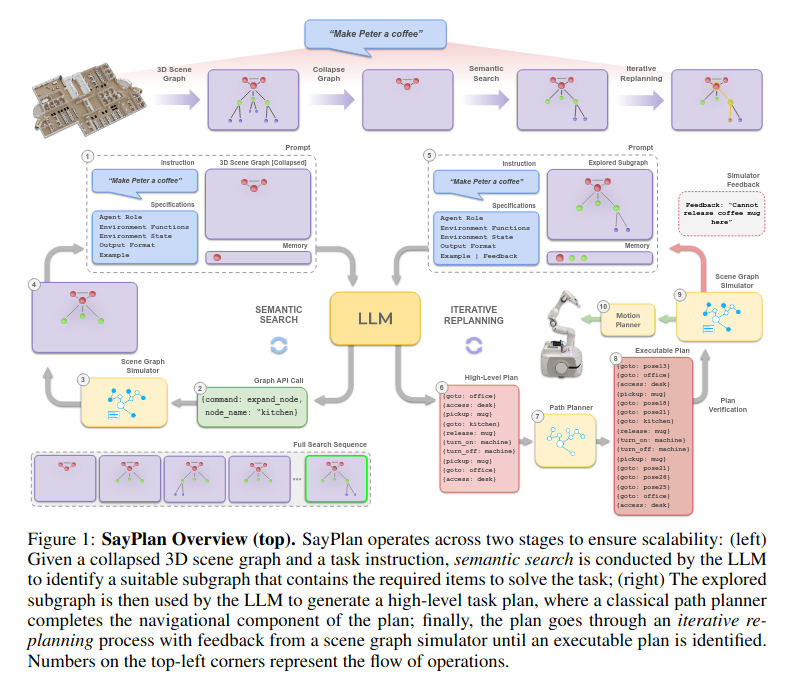
主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。