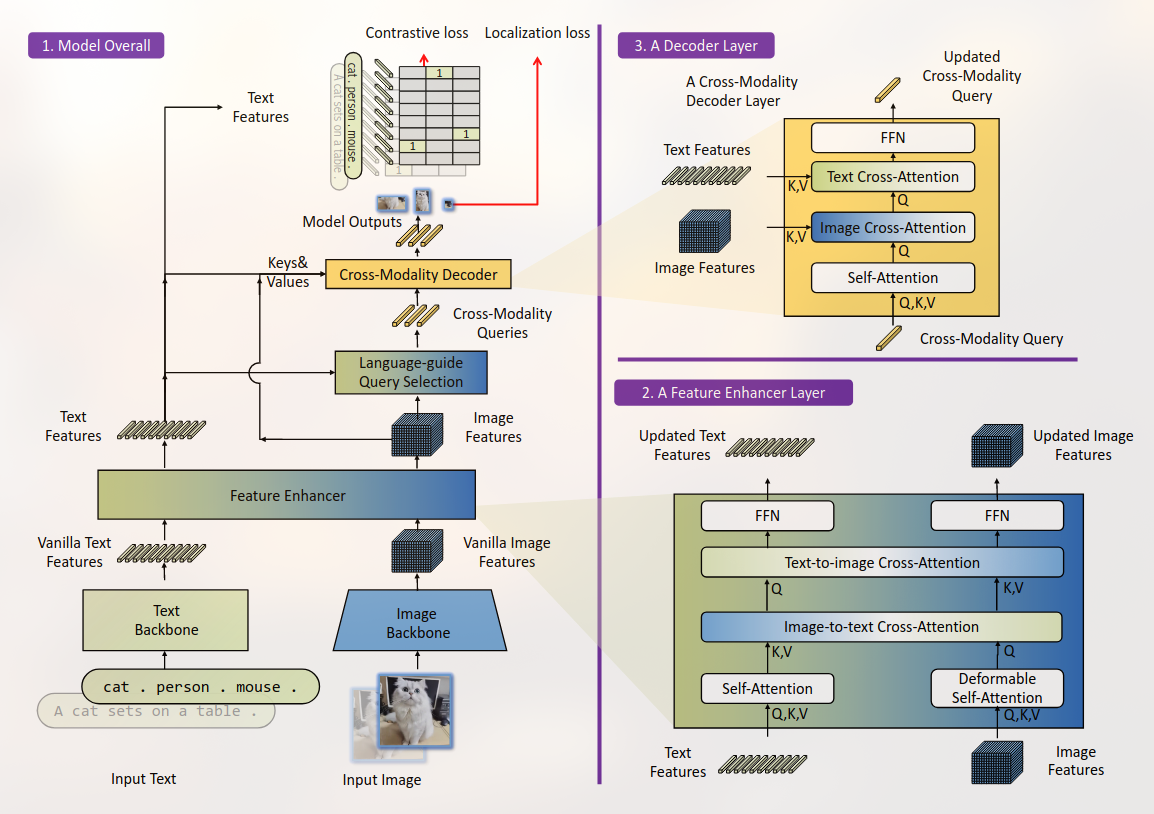
SGTR+= End-to-end Scene Graph Generation with Transformer
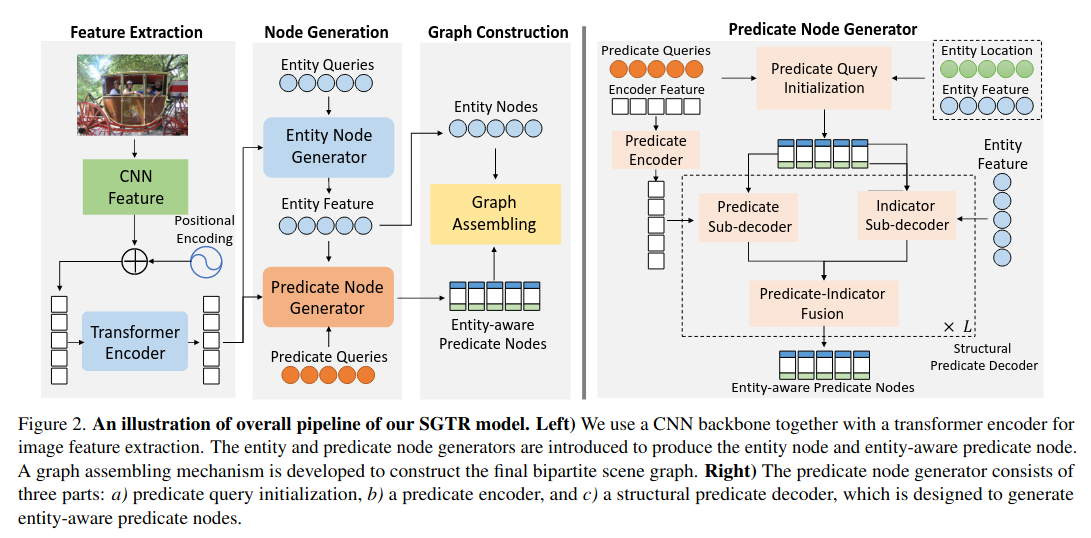
SGTR 是一种自上而下的方法,该方法首先使用基于Transformer的生成器来生成一组可学习的triplet queries (subject–predicate–object),然后使用级联的triplet detector逐步完善这些查询并生成最终场景图。它还提出了一种基于结构化发生器的实体感知关系表示方法,该方法利用了关系的组成属性。

SGTR+= End-to-end Scene Graph Generation with Transformer
SGTR 是一种自上而下的方法,该方法首先使用基于Transformer的生成器来生成一组可学习的triplet queries (subject–predicate–object),然后使用级联的triplet detector逐步完善这些查询并生成最终场景图。它还提出了一种基于结构化发生器的实体感知关系表示方法,该方法利用了关系的组成属性。

DETR是一个使用transformer作为基本架构的 object detection 模型。
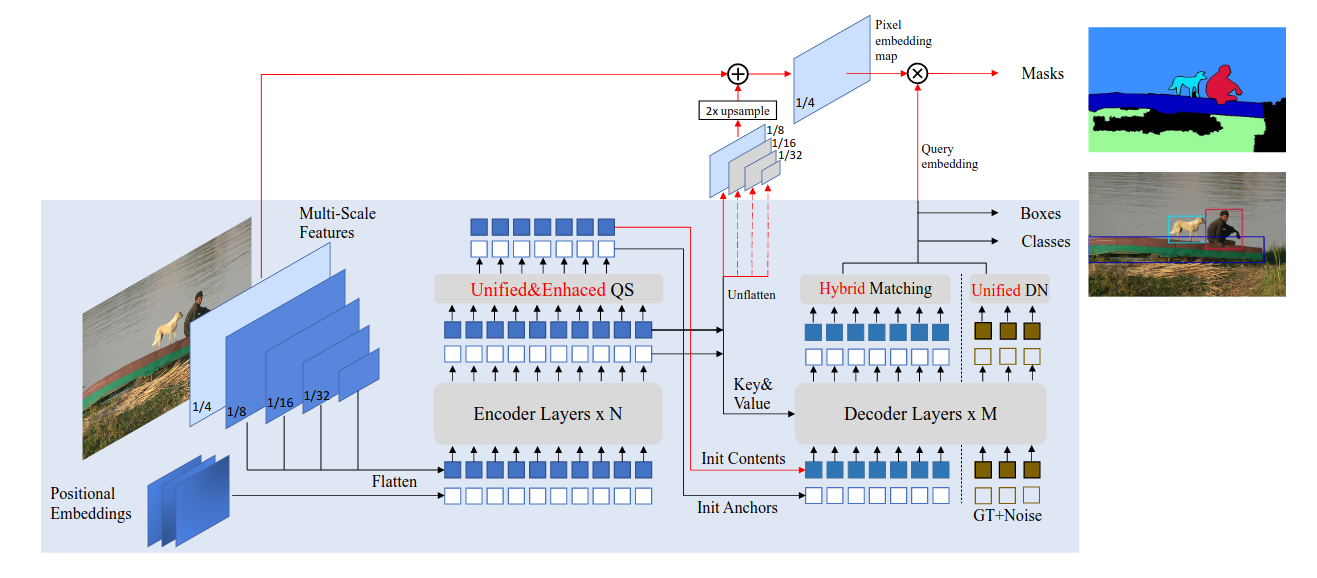
注:此DINO并非自蒸馏自监督的那个[[DINO]],而是派生自[[DETR]]