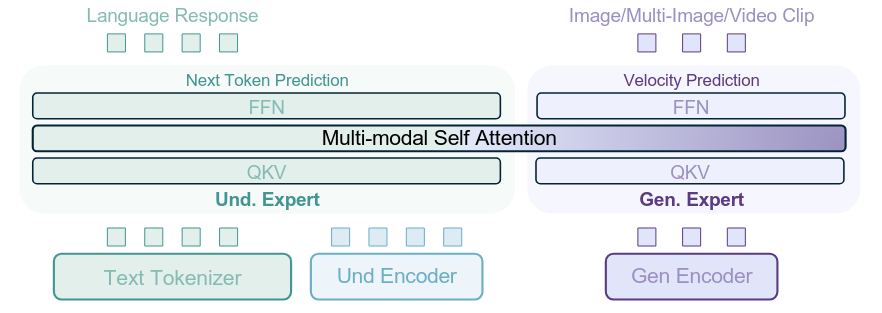
Posted 2026-02-06Updated 2026-03-23Review10 minutes read (About 1443 words)BAGEL-Unified-Multimodal-Pretraining论文链接 | 项目主页#Research-paperMulti-modalVLMDiffusionTransformerMoEUnified-MultimodalFoundationModelImage-generationImage2Text