Posted 2025-01-09Updated 2026-03-30Notea few seconds read (About 0 words)Vision Transformers Need Registers#Research-paperTransformerCVViT
Posted 2025-01-09Updated 2026-03-30Notea few seconds read (About 0 words)DINOv2- Learning Robust Visual Features without Supervision#Research-paperTransformerCVRepresentation-LearningViTDINO
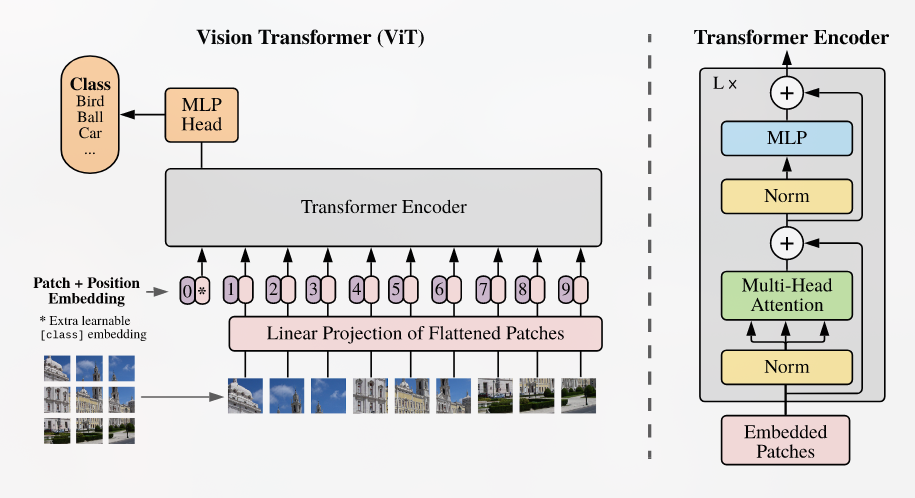
Posted 2025-01-09Updated 2026-03-30Notea few seconds read (About 71 words)AN IMAGE IS WORTH 16X16 WORDS- TRANSFORMERS FOR IMAGE RECOGNITION AT SCALEhttps://www.youtube.com/watch?v=j3VNqtJUoz0&t=16s#Research-paperTransformerCVViT
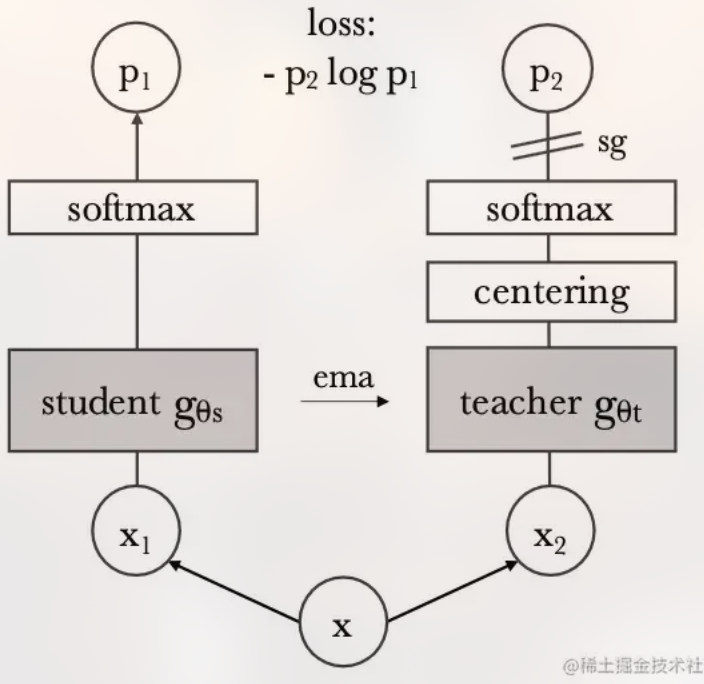
Posted 2025-01-08Updated 2026-03-30Note4 minutes read (About 561 words)DINOhttps://github.com/facebookresearch/dino/tree/main#Research-paperTransformerCVRepresentation-LearningViTDINO
Posted 2025-01-06Updated 2026-03-30Notea few seconds read (About 3 words)Simple Open-Vocabulary Object Detection with Vision Transformers#Research-paperTransformerCVObject-DetectionOpen-VocabularyViT