(Mindmap) Part-level Scene Understanding for Robots
 Part-level Scene Understanding for Robots/Pasted_image_20250414142333.png)
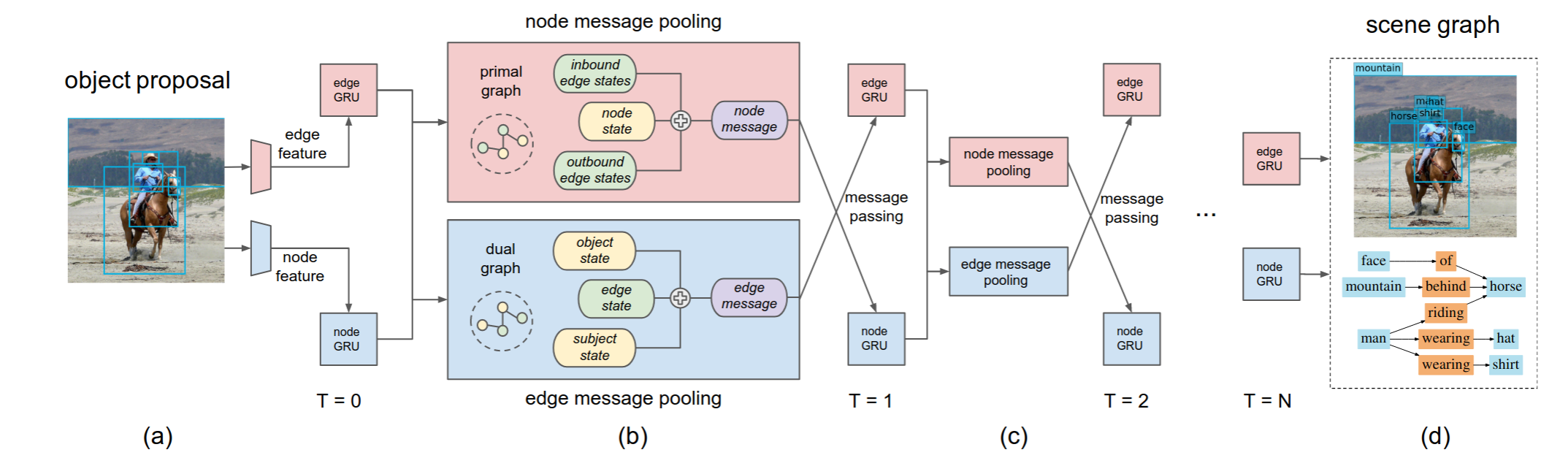
A scene graph is a structural representation, which can capture detailed semantics by explicitly Modeling:

(Mindmap) Part-level Scene Understanding for Robots
A scene graph is a structural representation, which can capture detailed semantics by explicitly Modeling:
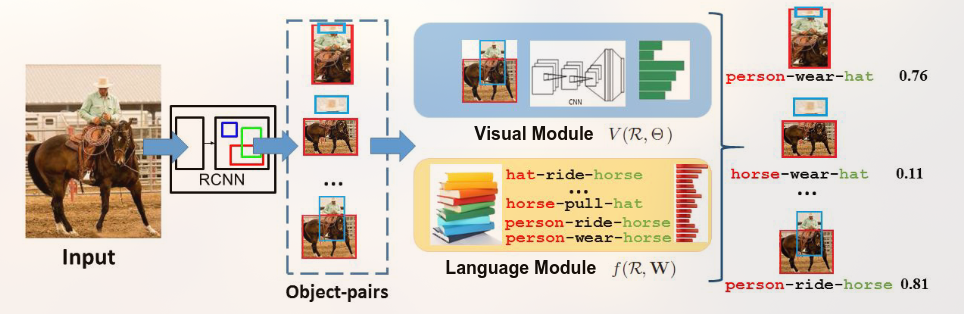
Representation Learning for Scene Graph Completion via Jointly Structural and Visual Embedding
 Representation Learning for Scene Graph Completion via Jointly Structural and Visual Embedding/Pasted_image_20250318162533.png)
The architecture of RLSV is a three-layered hierarchical projection that projects a visual triple onto the attribute space, the relation space, and the visual space in order.
Factorizable Net= An Efficient Subgraph-based Framework for Scene Graph Generation

我的想法是将场景进行panoptic segmentation 之后再在每个物体上进行hierarchical part relation detection,异曲同工。
RelTR= Relation Transformer for Scene Graph Generation
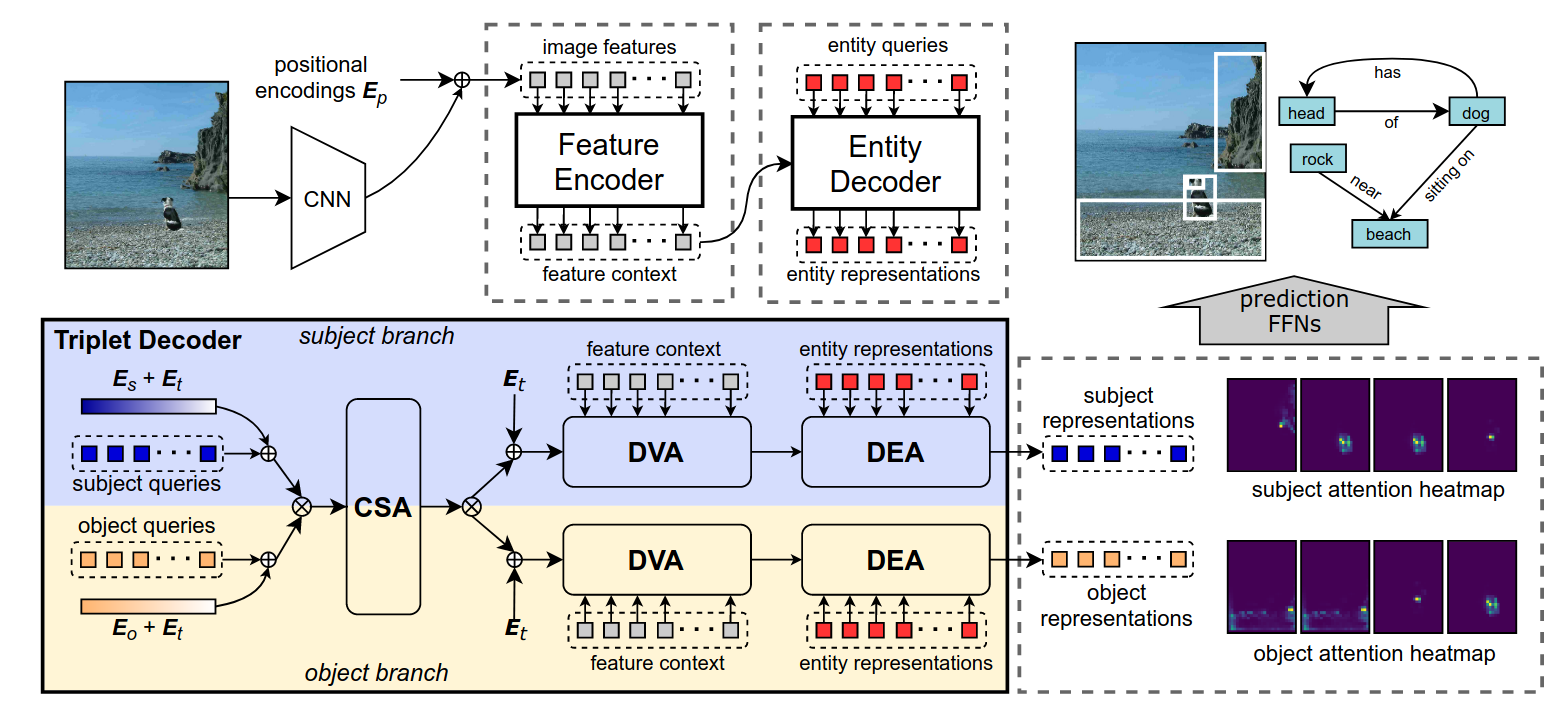
RelTR是自下而上的方法, 使用基于Transformer的 object detector(例如DETR)生成对象候选者,然后使用relation transformer来预测object pairs之间的关系。它还设计了一种基于积分的关系表示方法,该方法将关系编码为二维矢量场。
Fully Convolutional Scene Graph Generation
 Fully Convolutional Scene Graph Generation/Pasted_image_20250314123239.png)
这个模型受启发于 [[CenterNet]] 和 [[OpenPose Using Part Affinity Fields]],通过添加一个新的用于生成RAF的卷积头来获取物体之间的关系。

 Contextual Translation Embedding for Visual Relationship Detection and Scene Graph Generation/Pasted_image_20250318160643.png)
 Visual Translation Embedding Network for Visual Relation Detection/Pasted_image_20250318155431.png)