

LERF- Language Embedded Radiance Fields
NeRF+CLIP
Intro
背景
- 神经辐射场 (NeRF) 已成为一种强大的技术,用于捕获复杂的现实世界 3D 场景的逼真数字表示。然而,NeRF 的直接输出只不过是一个彩色的密度场,缺乏意义或上下文,这阻碍了构建与生成的 3D 场景交互的界面。
- 自然语言是与 3D 场景交互的直观界面。考虑厨房的捕获。想象一下,能够通过询问“用具”在哪里来导航这个厨房,或者更具体地说,询问可用于“搅拌”的工具,甚至可以询问您最喜欢的带有特定功能的杯子。其上的徽标——贯穿日常对话的舒适和熟悉。这不仅需要处理自然语言输入查询的能力,还需要能够在多个尺度上合并语义并与长尾和抽象概念相关。
解决方案
一个Language Field
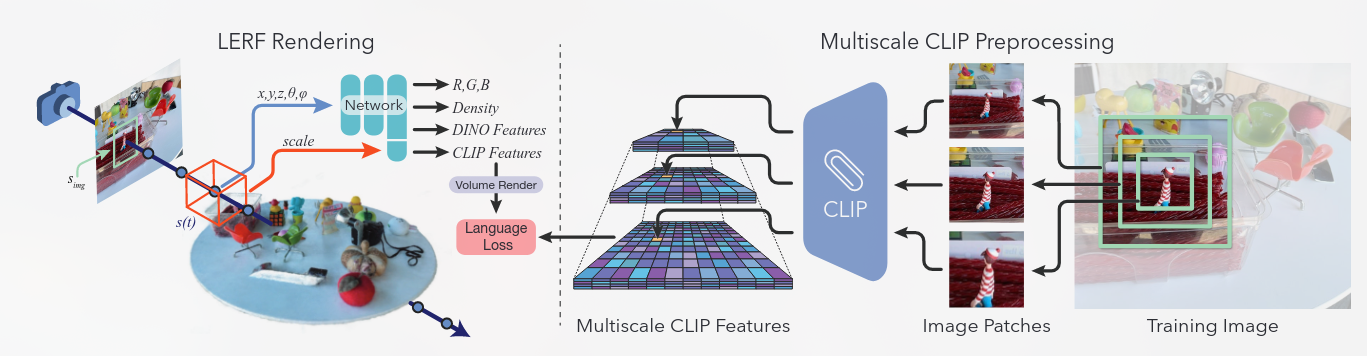
通过优化从现成的视觉语言模型(如 CLIP)到 3D 场景的嵌入,为 NeRF 中的语言奠定基础。
LERF 提供了一个额外的好处:由于我们从多个尺度的多个视图中提取 CLIP 嵌入,因此通过 3D CLIP 嵌入获得的文本查询的相关性图与通过 2D CLIP 嵌入获得的文本查询的相关性图相比更加本地化。根据定义,它们也是 3D 一致的,可以直接在 3D 字段中进行查询,而无需渲染到多个视图。
相较于Clip-Field[[CLIP-Fields- Weakly Supervised Semantic Fields for Robotic Memory]], LERF 更密集。
CLIP-Fields [32] and NLMaps-SayCan [8] fuse CLIP embeddings of crops into pointclouds, using a contrastively supervised field and classical pointcloud fusion respectively. In CLIP-Fields, the crop locations are guided by Detic [40]. On the other hand, NLMaps-SayCan relies on region proposal networks. These maps are sparser than LERF as they primarily query CLIP on detected objects rather than densely throughout views of the scene. Concurrent work ConceptFusion [19] fuses CLIP features more densely in RGBD pointclouds, using Mask2Former [9] to predict regions of interest, meaning it can lose objects which are out of distribution to Mask2Former’s training set. In contrast, LERF does not use region or mask proposals.
LERF
给定一组校准的输入图像,我们将 CLIP 嵌入到 NeRF 内的 3D 场中。然而,查询单个 3D 点的 CLIP 嵌入是不明确的,因为 CLIP 本质上是全局图像嵌入,不利于像素对齐特征提取。为了解释这一特性,我们提出了一种新颖的方法,该方法涉及学习以样本点为中心的卷上的语言嵌入领域。具体来说,该字段的输出是包含指定体积的图像作物的所有训练视图中的平均 CLIP 嵌入。通过将查询从点重新构造为体积,我们可以有效地从输入图像的粗裁剪中监督密集的字段,这些图像可以通过在给定的体积尺度上进行调节来以像素对齐的方式渲染。
OK-Robot- What Really Matters in Integrating Open-Knowledge Models for Robotics

Intro
Creating a general-purpose robot has been a longstanding dream of the robotics community.
背景
当前想要实现这一目标的系统脆弱、封闭,并且在遇到未见过的情况时会失败。即使是最大的机器人模型通常也只能部署在以前见过的环境中 [5, 6]。在机器人数据很少的环境中,例如在非结构化的家庭环境中,这些系统的脆弱性会进一步加剧。
虽然大型视觉模型显示出语义理解 、检测以及将视觉表示与语言联系起来的能力并且与此同时,机器人的导航、抓取和重新排列等基本机器人技能已经相当成熟。
但是将现代视觉模型与机器人特定基元相结合的机器人系统表现非常差。
这可能是因为单纯将多个不确定性的系统组合在一起会导致准确率急剧恶化。
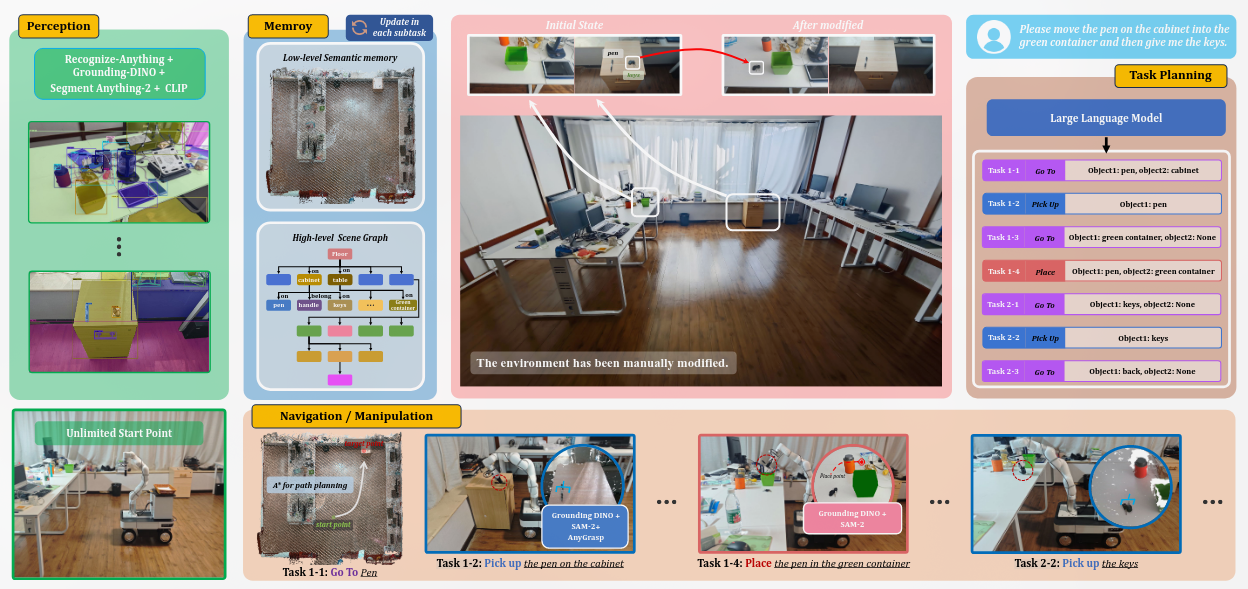
所以我们需要一个将VLM和机器人primitives(导航,抓取,放置)结合在一起的细致框架,即OK-Robot。
发现
- 预训练的 VLM 对于开放词汇导航非常有效: 当前的开放词汇视觉语言模型,例如 CLIP 或 OWL-ViT,在识别现实世界中的任意对象方面提供了强大的性能,并能够以零样本的方式导航到它们。
- 预训练的抓取模型可以直接应用于移动操作:与 VLM 类似,经过大量数据预训练的专用机器人模型可以立即应用于家庭中的开放词汇抓取。这些机器人模型不需要任何额外的训练或微调。
- 如何组合组件至关重要:给定预训练模型,我们发现可以使用简单的状态机模型将它们组合在一起,无需训练。我们还发现,使用启发式方法来抵消机器人的物理限制可以在现实世界中获得更高的成功率。
- 仍然存在一些挑战:虽然,考虑到在任意家庭中进行零样本的巨大挑战,OK-Robot 在之前的工作基础上进行了改进,通过分析故障模式,我们发现 VLM、机器人模型和机器人形态可以进行重大改进,这将直接提高开放知识操纵代理的性能。
Methodology
该框架主要完成的任务
Pick up A (from B) and drop it on/in C”, where A is an object and B and C are places in a real-world environment such as homes
Open-home, open-vocabulary object navigation
负责空间重建,识别物体大致位置,机器人导航
用到的方法:
- CLIP-Fields [[CLIP-Fields- Weakly Supervised Semantic Fields for Robotic Memory]] : a RGB-D video of the home -> a sequence of posed ( with camera pose and positions) RGB-D images,用于重建环境,该研究还基于此获取了环境中物体和容器旁边的地板表面。
- OWL-ViT [[Simple Open-Vocabulary Object Detection with Vision Transformers]] : 我们在每一帧上应用检测器,并提取每个对象边界框、CLIP-embedding、检测器置信度,并将这些信息传递到object memory模块中
- SAM: 用于将ViT的检测框转化为mask
- VoxcelMap: similar to object-centric memory of CLIP-Fields [[CLIP-Fields- Weakly Supervised Semantic Fields for Robotic Memory]], 基于点云中每一个点的CLIP semantic vector,每一个5cm的体素都包含一个CLIP-embedding的detector-confidence weighted average.
- Querying the memory module: 先将language query 转化成CLIP semantic vector,然后基于voxelmap的clip-embeding,寻找最语义接近的那个voxel,以此定位。

Experiment

Dynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
和我的想法非常相近,完成度也很高啊喂。可以参考他的实现思路,引用的文章等等。
ACDC- Automated Creation of Digital Cousins for Robust Policy Learning
Intro
数字孪生(DT)作为现实世界非常精确的映射虽然可以用于高精度的训练但是生产DT资产过于繁琐且没有泛化性,不能做到zero-shot。
数字表亲(DC)通过比对模型特征,从模型库中选择类似的表亲模型,用于重建场景训练机械臂。让机械臂针对不同第一次见的场景具有泛化性。
(a)它减少了手动微调的需要,以保证一定的保真度,从而能够完全自动化地创建数字表亲,(b)它通过提供一组增强的场景来训练机器人策略,从而有助于更好地应对原始场景中的变化。
Methodology
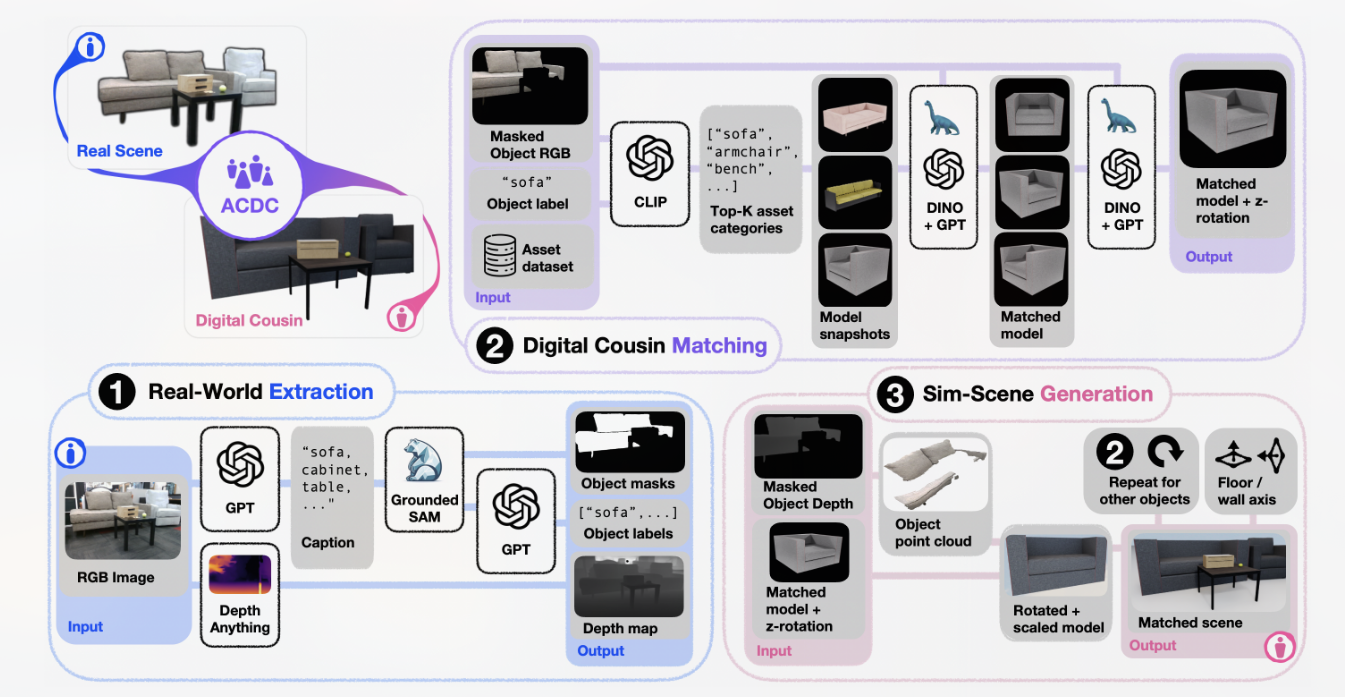
ACDC is our automated pipeline for generating fully interactive simulated scenes from a single RGB image, and is broken down into three steps:
(1) an extraction step, in which relevant object masks are extracted from the raw input image
(2) a matching step, in which we select digital cousins for individual objects extracted from the original scene
(3) a generation step, in which the selected digital cousins are post-processed and compiled together to form a fully-interactive, physically-plausible digital cousin scene.

