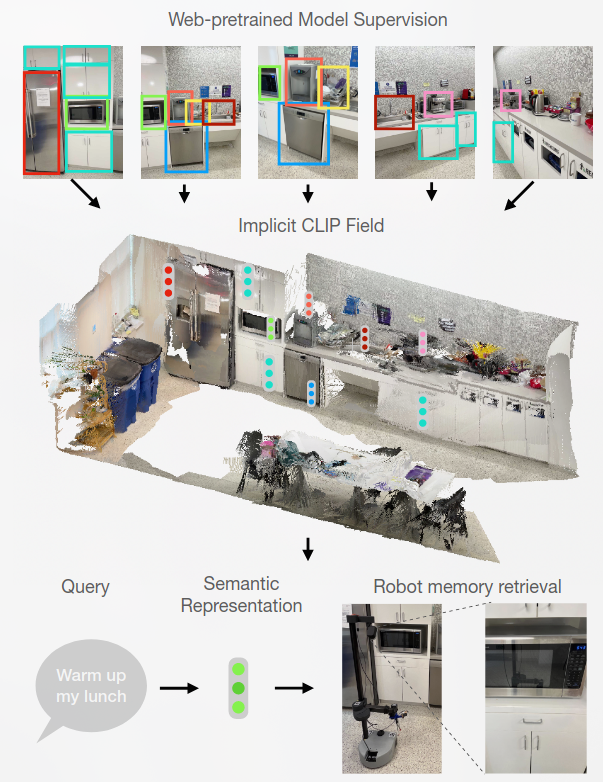


Some Thoughts Regarding -Reconstruct Anything-
主要记录一些读场景语义化重建的论文的过程中的想法
重要的问题
多模态包含哪些任务
- 图文检索 Image-text Retrival
- 视觉问答 VQA
- 视觉推理 Visual Reasoning
- 视觉蕴含 Visual Entailment
多模态有哪些loss
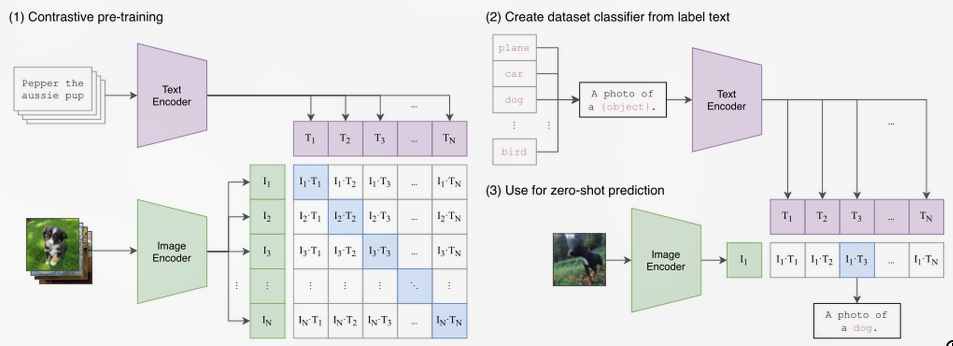
- Image Text Contrastive(ITC) [[CLIP多模态预训练模型]]
- Word Patch Aligment (WPA) used in object detection ViT
- Image Text Matching (ITM)
- Mask Languae Modeling (MLM) BERT 完形填空
给定一个具体的任务,机器人需要哪些场景信息才能顺利执行这个任务(通用机器人)
限定:暂不考虑机器人的移动性,也就是不需要跨视野的导航(OK-Robot),暂定为桌面机器人
具体来说,通用机器人的特点包括:
- 多任务能力:能够执行多种不同类型的任务,如装配、搬运、清洁、检测等。
- 适应性强:具备适应多种环境和工作条件的能力,例如在不同地形或生产线中工作的能力。
- 智能控制:通过先进的传感器、人工智能算法、机器学习技术等手段,能够实现自主决策和任务规划。
- 物体的具体形状(用于抓取, grab-anything)
- 物体语义信息(grounded caption, clip)
Recognize The Relationships Between Child & Parent
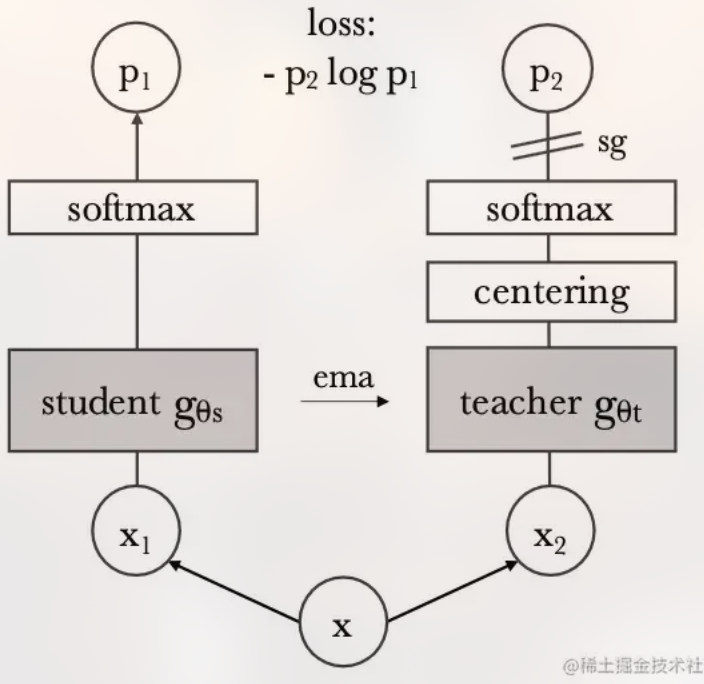
受DINO自蒸馏自监督的启发,可以通过物体活动的图像序列来推测物体各个部分的物理关系(attention map)[[DINO]]
训练集可以使用Unity生成不同的光影/物体,连接语义
Build the physics world in robot mind
voxel collider for detected objects, joints, physics agent interact with physics engine.
点云数据,grounded caption=>object property, hierarchy relation, joints(maybe new model should be proposed)
语义还原物体模型
受[[BLIP]]启发,understanding for language & existing point cloud, generation for the rest of the point cloud (Wonder3D已实现)