Simple Open-Vocabulary Object Detection with Vision Transformers


OK-Robot- What Really Matters in Integrating Open-Knowledge Models for Robotics

Creating a general-purpose robot has been a longstanding dream of the robotics community.

A Survey of Imitation Learning- Algorithms, Recent Developments, and Challenges

IL是区别于传统手动编程来赋予机器人自主能力的方法。
IL 允许机器通过演示(人类演示专家行为)来学习所需的行为,从而消除了对显式编程或特定于任务的奖励函数的需要。
IL主要有两个类别:
Dynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
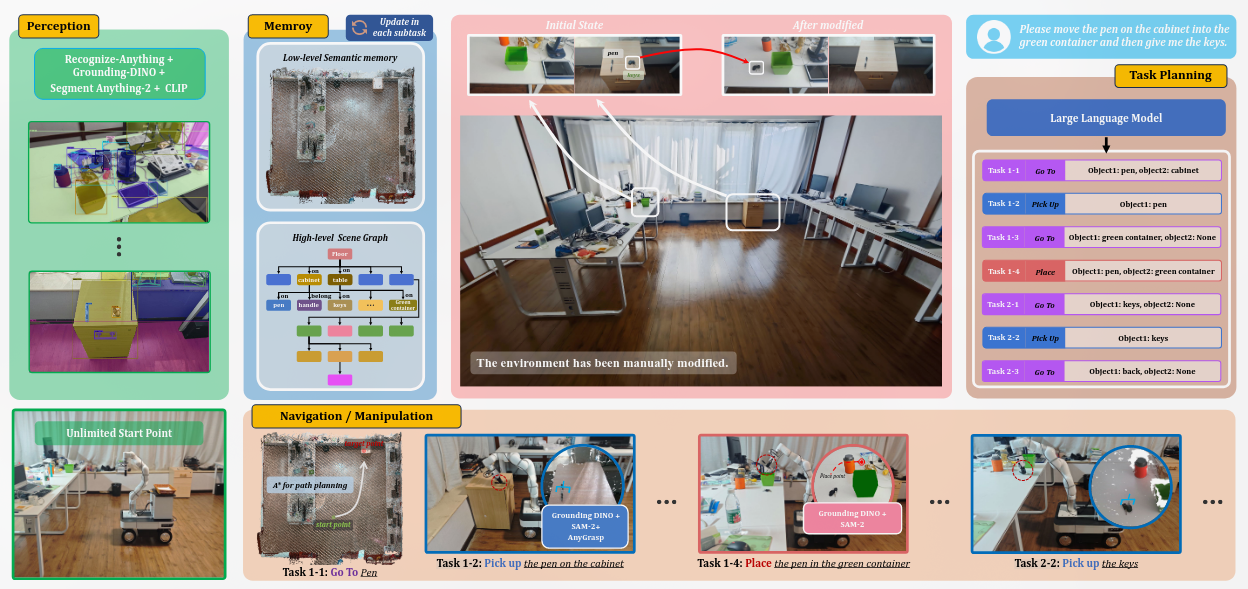
和我的想法非常相近,完成度也很高啊喂。可以参考他的实现思路,引用的文章等等。
ACDC- Automated Creation of Digital Cousins for Robust Policy Learning
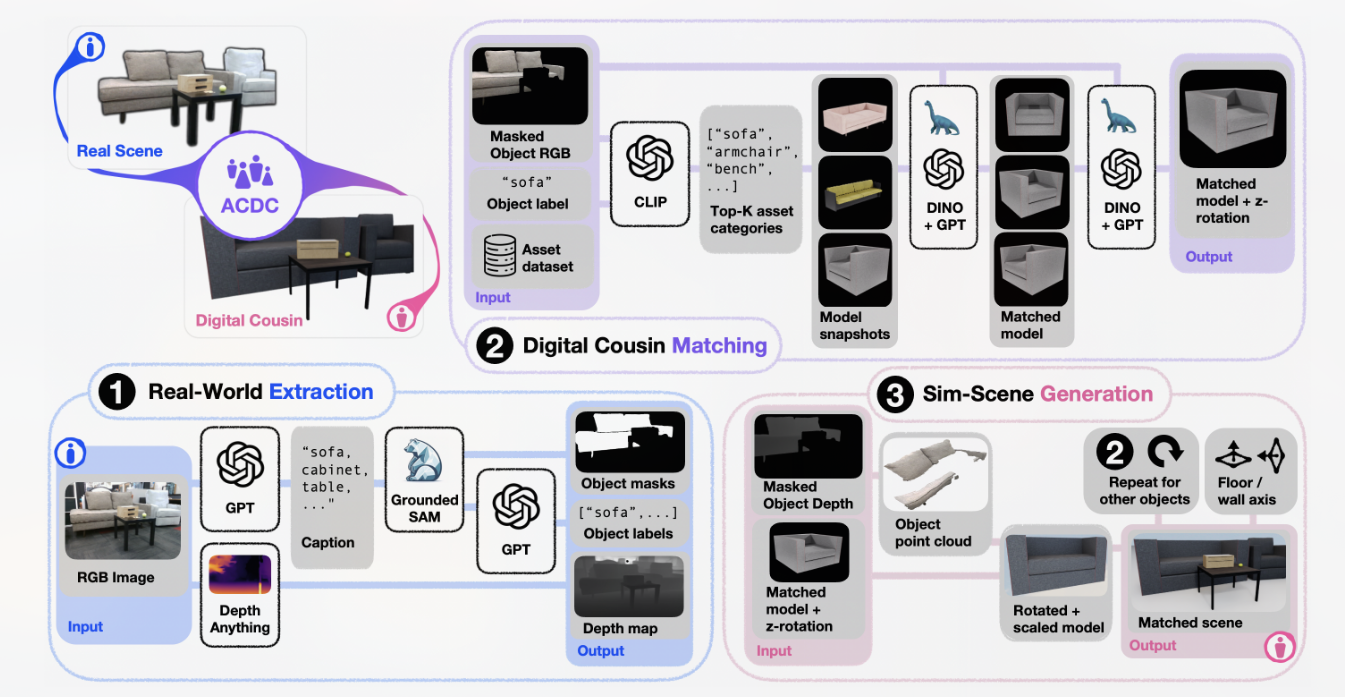
数字孪生(DT)作为现实世界非常精确的映射虽然可以用于高精度的训练但是生产DT资产过于繁琐且没有泛化性,不能做到zero-shot。
数字表亲(DC)通过比对模型特征,从模型库中选择类似的表亲模型,用于重建场景训练机械臂。让机械臂针对不同第一次见的场景具有泛化性。
(a)它减少了手动微调的需要,以保证一定的保真度,从而能够完全自动化地创建数字表亲,(b)它通过提供一组增强的场景来训练机器人策略,从而有助于更好地应对原始场景中的变化。
CosyPose-- Consistent multi-view multi-object 6D pose estimation

Estimate accurate 6D poses of multiple known objects in a 3D scene captured by multiple cameras with unknown positions
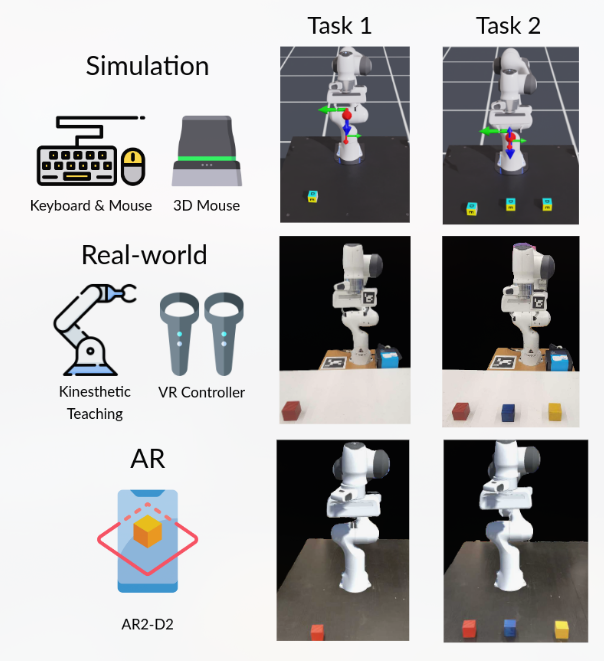
Human-robot interaction for robotic manipulator programming in Mixed Reality
和我毕设很像的工作,居然已经发ICRA了?